
Python3.x爬虫下载网页图片的实例讲解

一、选取网址进行爬虫
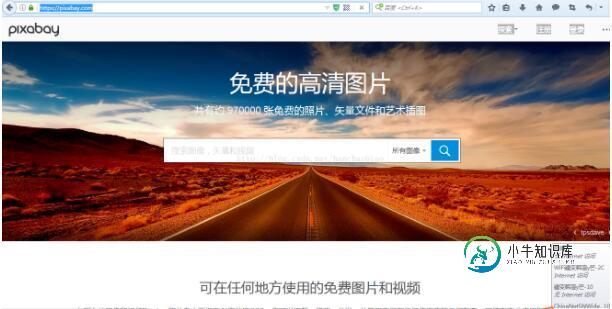
本次我们选取pixabay图片网站
url=https://pixabay.com/
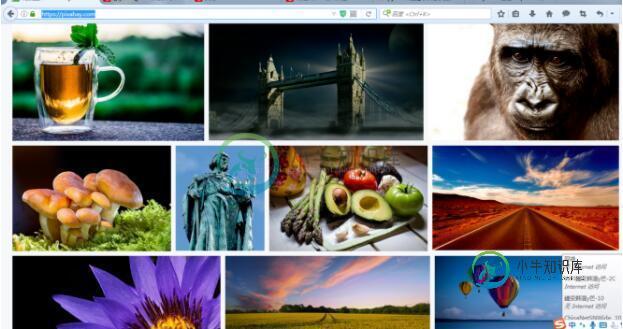
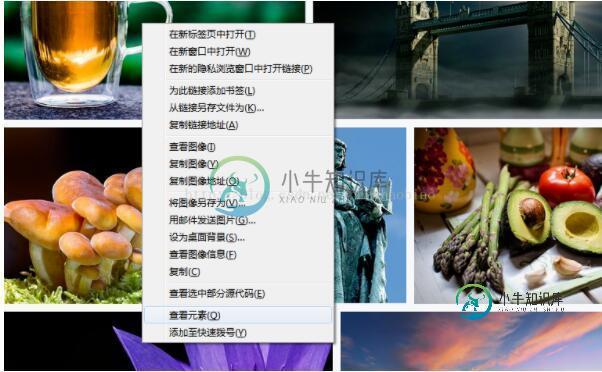
二、选择图片右键选择查看元素来寻找图片链接的规则
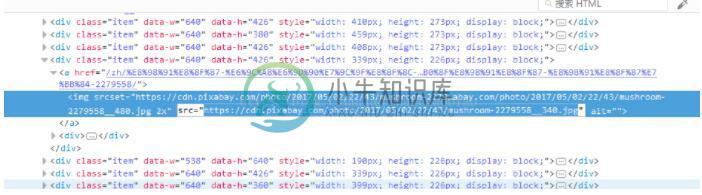
通过查看多个图片路径我们发现取src路径都含有 https://cdn.pixabay.com/photo/ 公共部分且图片格式都为.jpg 因此正则表达式为
re.compile(r'^https://cdn.pixabay.com/photo/.*?jpg$')
通过以上的分析我们可以开始写程序了
#-*- coding:utf-8 -*-
import re
import requests
import os
from bs4 import BeautifulSoup
url = 'https://pixabay.com/'
html = requests.get(url).text #获取网页内容
print(html)
# 这里由于有些图片可能存在网址打不开的情况,加个5秒超时控制。
#data-objurl="http://pic38.nipic.com/20140218/17995031_091821599000_2.jpg"获取这种类型链接
soup = BeautifulSoup(html,'html.parser',from_encoding='utf-8')
#^abc.*?qwe$
pic_url = soup.find_all('img',src=re.compile(r'^https://cdn.pixabay.com/photo/.*?jpg$'))
#pic_url = pic_node.get_text()
#pic_url = re.findall('"https://cdn.pixabay.com/photo/""(.*?)",',html,re.S)
print(pic_url)
i = 0
#判断image文件夹是否存在,不存在则创建
if not os.path.exists('image'):
os.makedirs('image')
for url in pic_url:
img = url['src']
try:
pic = requests.get(img,timeout=5) #超时异常判断 5秒超时
except requests.exceptions.ConnectionError:
print('当前图片无法下载')
continue
file_name = "image/"+str(i)+".jpg" #拼接图片名
print(file_name)
#将图片存入本地
fp = open(file_name,'wb')
fp.write(pic.content) #写入图片
fp.close()
i+=1
代码是不是很简单呢 如果你想修改地址 取爬取别的网站 请注意分析下载图片路径的共性 并设计合理的正则表达式,否则是无法获取到图片路径的
执行过程截图:
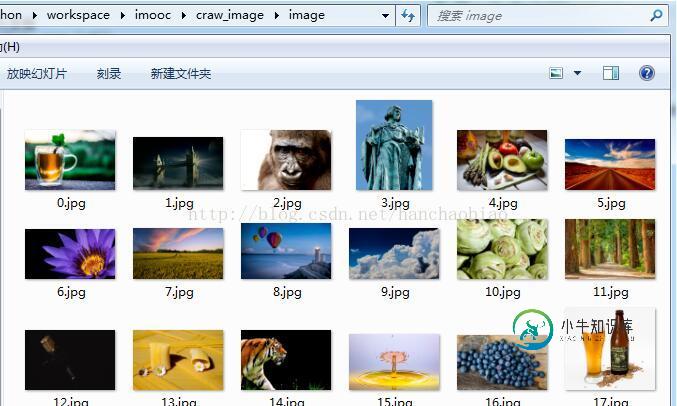
以上这篇Python3.x爬虫下载网页图片的实例讲解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
本文向大家介绍python3之微信文章爬虫实例讲解,包括了python3之微信文章爬虫实例讲解的使用技巧和注意事项,需要的朋友参考一下 前提: python3.4 windows 作用:通过搜狗的微信搜索接口http://weixin.sogou.com/来搜索相关微信文章,并将标题及相关链接导入Excel表格中 说明:需xlsxwriter模块,另程序编写时间为2017/7/11,以免之后程序无
-
本文向大家介绍python3 下载网络图片代码实例,包括了python3 下载网络图片代码实例的使用技巧和注意事项,需要的朋友参考一下 说明:这里仅展示在已经获取图片链接后的下载方式,对于爬虫获取链接部分参考前面的文章 1、利用文件读写的方式下载图片 2、urlretrieve()方法 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
本文向大家介绍python实现爬虫下载美女图片,包括了python实现爬虫下载美女图片的使用技巧和注意事项,需要的朋友参考一下 本次爬取的贴吧是百度的美女吧,给广大男同胞们一些激励 在爬取之前需要在浏览器先登录百度贴吧的帐号,各位也可以在代码中使用post提交或者加入cookie 爬行地址:http://tieba.baidu.com/f?kw=%E7%BE%8E%E5%A5%B3&ie=utf-
-
主要内容:导入所需模块,拼接URL地址,向URL发送请求,保存为本地文件,函数式编程修改程序本节讲解第一个 Python 爬虫实战案例:抓取您想要的网页,并将其保存至本地计算机。 首先我们对要编写的爬虫程序进行简单地分析,该程序可分为以下三个部分: 拼接 url 地址 发送请求 将照片保存至本地 明确逻辑后,我们就可以正式编写爬虫程序了。 导入所需模块 本节内容使用 urllib 库来编写爬虫,下面导入程序所用模块: 拼接URL地址 定义 URL 变量,拼接 url 地址。代码如下所示:
-
本文向大家介绍Python爬虫抓取指定网页图片代码实例,包括了Python爬虫抓取指定网页图片代码实例的使用技巧和注意事项,需要的朋友参考一下 想要爬取指定网页中的图片主要需要以下三个步骤: (1)指定网站链接,抓取该网站的源代码(如果使用google浏览器就是按下鼠标右键 -> Inspect-> Elements 中的 html 内容) (2)根据你要抓取的内容设置正则表达式以匹配要抓取的内容
-
主要内容:案例简单分析,编写爬虫程序本节通过具体的爬虫程序,演示 BS4 解析库的实际应用。爬虫程序目标:下载诗词名句网( https://www.shicimingju.com/book/)《 两晋演义》小说。 关于分析网页分过程,这里不再做详细介绍了,只要通读了前面的文章,那么关于如何分析网页,此时您应该了然于胸了。其实,无论您爬取什么类型的网站,分析过程总是相似的。 案例简单分析 首先判网站属于静态网站,因此您的主要任务是分析