
零基础写python爬虫之打包生成exe文件

1.下载pyinstaller并解压(可以去官网下载最新版):
https://github.com/pyinstaller/pyinstaller/
2.下载pywin32并安装(注意版本,我的是python2.7):
https://pypi.python.org/pypi/pywin32
3.将项目文件放到pyinstaller文件夹下面(我的是baidu.py):
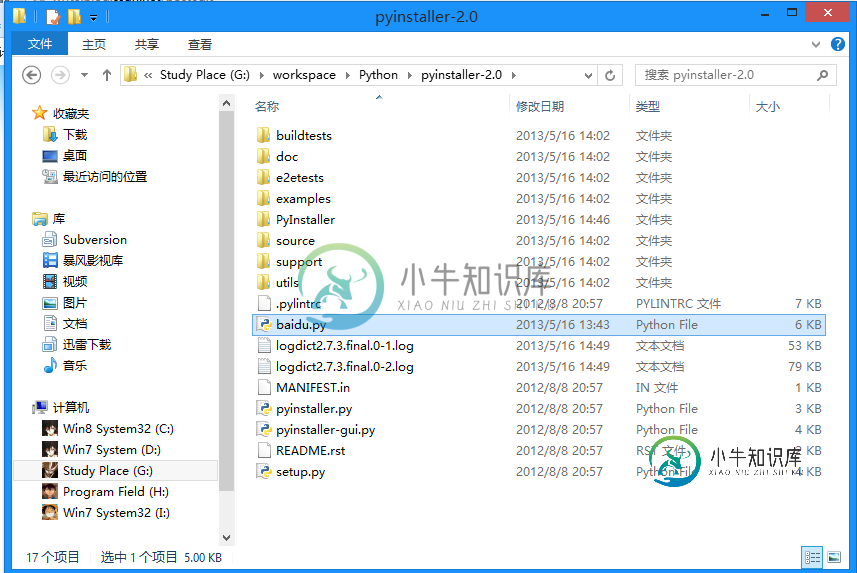
4.按住shift键右击,在当前路径打开命令提示行,输入以下内容(最后的是文件名):
python pyinstaller.py -F baidu.py
5.生成的exe文件,在baidu文件夹下的dist文件夹中,双击即可运行:
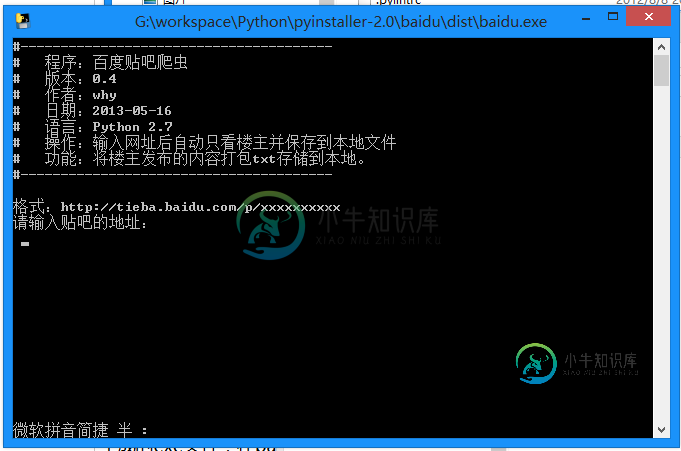
-
本文向大家介绍零基础写python爬虫之爬虫的定义及URL构成,包括了零基础写python爬虫之爬虫的定义及URL构成的使用技巧和注意事项,需要的朋友参考一下 一、网络爬虫的定义 网络爬虫,即Web Spider,是一个很形象的名字。 把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。 网络蜘蛛是通过网页的链接地址来寻找网页的。 从网站某一个页面(通常是首页)开始,读取网页的内容
-
本文向大家介绍零基础写python爬虫之urllib2使用指南,包括了零基础写python爬虫之urllib2使用指南的使用技巧和注意事项,需要的朋友参考一下 前面说到了urllib2的简单入门,下面整理了一部分urllib2的使用细节。 1.Proxy 的设置 urllib2 默认会使用环境变量 http_proxy 来设置 HTTP Proxy。 如果想在程序中明确控制 Proxy 而不受环境
-
本文向大家介绍零基础写python爬虫之神器正则表达式,包括了零基础写python爬虫之神器正则表达式的使用技巧和注意事项,需要的朋友参考一下 接下来准备用糗百做一个爬虫的小例子。 但是在这之前,先详细的整理一下Python中的正则表达式的相关内容。 正则表达式在Python爬虫中的作用就像是老师点名时用的花名册一样,是必不可少的神兵利器。 一、 正则表达式基础 1.1.概念介绍 正则表达式是用于
-
本文向大家介绍零基础写python爬虫之使用urllib2组件抓取网页内容,包括了零基础写python爬虫之使用urllib2组件抓取网页内容的使用技巧和注意事项,需要的朋友参考一下 版本号:Python2.7.5,Python3改动较大,各位另寻教程。 所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地。 类似于使用程序模拟IE浏览器的功能,把URL作为HTTP请求的
-
本文向大家介绍零基础写python爬虫之抓取百度贴吧代码分享,包括了零基础写python爬虫之抓取百度贴吧代码分享的使用技巧和注意事项,需要的朋友参考一下 这里就不给大家废话了,直接上代码,代码的解释都在注释里面,看不懂的也别来问我,好好学学基础知识去! 以上就是python抓取百度贴吧的一段简单的代码,非常的实用吧,各位可以自行扩展下。
-
本文向大家介绍零基础写python爬虫之urllib2中的两个重要概念:Openers和Handlers,包括了零基础写python爬虫之urllib2中的两个重要概念:Openers和Handlers的使用技巧和注意事项,需要的朋友参考一下 在开始后面的内容之前,先来解释一下urllib2中的两个个方法:info / geturl urlopen返回的应答对象response(或者HTTPErr