《pandas》专题
-
正确的方法来反转pandas.DataFrame?
问题内容: 这是我的代码: 当我运行此代码时,出现以下错误: 为什么会出现此错误? 我该如何解决? 正确的逆转方法是什么? 问题答案: 或者简单地: 将反转您的数据帧,如果您想使循环从下到上,则可以执行以下操作: 要么 因为你得到一个错误首先调用返回6,然后试图调用用于在和第一个电话会; 但在pandas数据框中表示第5列,而没有第5列,因此它将引发异常。(请参阅文档)
-
Python,Pandas:将DataFrame的内容写入文本文件
问题内容: 我有这样的熊猫DataFrame 我想将此数据写入如下所示的文本文件: 我已经尝试过类似的东西 但它不起作用。这该怎么做? 问题答案: 您可以只使用和访问np属性: 产量: 或: 请注意,您必须传递通过追加模式创建的文件句柄。
-
pandas apply多线程实现代码
本文向大家介绍pandas apply多线程实现代码,包括了pandas apply多线程实现代码的使用技巧和注意事项,需要的朋友参考一下 一、多线程化选择 并行化一个代码有两大选择:multithread 和 multiprocess。 Multithread,多线程,同一个进程(process)可以开启多个线程执行计算。每个线程代表了一个 CPU 核心,这么多线程可以访问同
-
pandas使用apply多列生成一列数据的实例
本文向大家介绍pandas使用apply多列生成一列数据的实例,包括了pandas使用apply多列生成一列数据的实例的使用技巧和注意事项,需要的朋友参考一下 如下所示: 以上这篇pandas使用apply多列生成一列数据的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊教程。
-
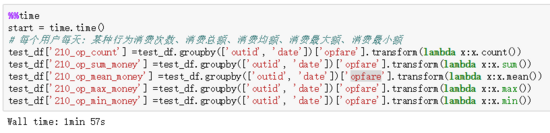 pandas中apply和transform方法的性能比较及区别介绍
pandas中apply和transform方法的性能比较及区别介绍本文向大家介绍pandas中apply和transform方法的性能比较及区别介绍,包括了pandas中apply和transform方法的性能比较及区别介绍的使用技巧和注意事项,需要的朋友参考一下 1. apply与transform 首先讲一下apply() 与transform()的相同点与不同点 相同点: 都能针对dataframe完成特征的计算,并且常常与groupby()方法一起使用。
-
 pandas apply 函数 实现多进程的示例讲解
pandas apply 函数 实现多进程的示例讲解本文向大家介绍pandas apply 函数 实现多进程的示例讲解,包括了pandas apply 函数 实现多进程的示例讲解的使用技巧和注意事项,需要的朋友参考一下 前言: 在进行数据处理的时候,我们经常会用到 pandas 。但是 pandas 本身好像并没有提供多进程的机制。本文将介绍如何来自己实现 pandas (apply 函数)的多进程执行。其中,我们主要借助 joblib 库,这个库
-
pandas 使用apply同时处理两列数据的方法
本文向大家介绍pandas 使用apply同时处理两列数据的方法,包括了pandas 使用apply同时处理两列数据的方法的使用技巧和注意事项,需要的朋友参考一下 多的不说,看了代码就懂了! 以上这篇pandas 使用apply同时处理两列数据的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊教程。
-
在Pandas DataFrame中选择多个列范围
问题内容: 我必须阅读一些文件,其中一些文件采用Excel格式,有些文件采用CSV格式。一些文件具有数百列。 有没有一种方法可以选择多个列范围而不指定所有列名或位置?例如,选择第1 -10、15、17和50-100列: 从Excel文件和CSV文件创建数据框时以及创建数据框框程序后,我都需要知道如何执行此操作。 问题答案: 采用 所以你可以做
-
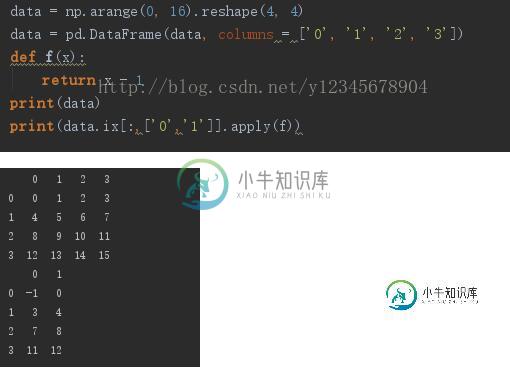 对pandas中apply函数的用法详解
对pandas中apply函数的用法详解本文向大家介绍对pandas中apply函数的用法详解,包括了对pandas中apply函数的用法详解的使用技巧和注意事项,需要的朋友参考一下 最近在使用apply函数,总结一下用法。 apply函数可以对DataFrame对象进行操作,既可以作用于一行或者一列的元素,也可以作用于单个元素。 例:列元素 行元素 列 行 以上这篇对pandas中apply函数的用法详解就是小编分享给大家的全部内容了
-
Python Pandas-在groupby之后过滤行
问题内容: 例如,我有下表: 分组后: 我需要的是删除每个组中的行,其中列中的数量小于组中column的所有行中的最大值。好吧,我在将这个问题翻译和表达为英语时遇到了问题,因此这里是示例: 组中列中的行的最大值: 8 所以我想删除带有索引的行,并保留带有索引的行, 组中列中的行的最大值: 5 所以我想删除带有索引的行并保留带有索引的行 我尝试使用熊猫过滤器功能,但是问题是它一次在组中的所有行上运行
-
比较Pandas DataFrame中的上一行值
问题内容: 我有以下Pandas DataFrame,我想创建另一列来比较col1的前一行,以查看它们是否相等。最好的方法是什么?就像下面的DataFrame。谢谢 问题答案: 您需要使用: 或改为使用,但是在大型DataFrame中,它会稍微慢一些: 时间 :
-
找到月底的Pandas DataFrame系列
问题内容: 我在DataFrame中有一个系列,最初是作为对象读取的,然后需要将其转换为yyyy-mm-dd形式的日期,其中dd是月末。 举例来说,我将DataFrame df的Date列作为对象: 全部说完之后我想要的是一个日期对象: 这样df [‘Date’]。item()返回 我使用以下代码几乎可以到达那里,但是我所有的日期都是在月初,而不是月底。请指教。 注意:我已经导入了Pandas a
-
比较Python Pandas DataFrames以匹配行
问题内容: 我在Pandas中有这个DataFrame(): 我想检查中是否存在来自另一个数据框()的任何行(所有列)。这里是: 我尝试使用一次搜索一行。我这样做是这样的: 但我收到此错误消息: 我也尝试使用: 但我收到此错误消息: 我也这样尝试过: 但是我到处都是,这是不正确的: 通过将其与另一个数据框的行进行比较,是否有可能在数据框中搜索一组行? 编辑:如果这些行中也存在行,是否可以删除行?
-
检查Pandas DataFrame列中的字符串是否在字符串列表中
问题内容: 如果我有这样的框架 我想检查这些行中是否包含某个单词,我只需要这样做。 输出: 如果我决定列出一个清单 如何检查列表中的行是否包含某个单词? 问题答案: 该方法接受正则表达式模式: 由于支持正则表达式模式,因此您还可以嵌入标志:
-
 使用pandas库对csv文件进行筛选保存
使用pandas库对csv文件进行筛选保存本文向大家介绍使用pandas库对csv文件进行筛选保存,包括了使用pandas库对csv文件进行筛选保存的使用技巧和注意事项,需要的朋友参考一下 这个操作现在看来真没啥难的,但是我找相关的资料真的找了好久。 多数大佬都是直接pandas官网甩我脸上,然后举一个入门级的例子。 https://pandas.pydata.org/docs/reference/index.html 首先导入panda