《pandas》专题
-
pandas:SettingWithCopy警告:
问题内容: 我尝试了以下代码将列转换为“日期”: 要么 但出现以下错误: /Users/xyz/anaconda3/envs/sensor/lib/python3.6/site- packages/pandas/core/indexing.py:517:SettingWithCopyWarning:试图在DataFrame的切片副本上设置一个值。尝试改用.loc [row_indexer,col_
-
在没有elasticsearch-py的情况下将pandas数据框索引到Elasticsearch
问题内容: 我想将一堆pandas数据框(大约一百万行和50列)索引到Elasticsearch中。 当寻找有关如何执行此操作的示例时,大多数人会使用elasticsearch-py的bulk helper方法 ,并向其传递处理连接的Elasticsearch类的实例以及使用pandas的dataframe创建的字典列表。orient =’records’)方法 。可以预先将元数据作为新列插入数据
-
汇总作为现有Pandas数据中的新列
问题内容: 我有一个定义为的熊猫数据框: 我想做一个SUM_C的累加和,并将其作为新列添加到同一数据帧。换句话说,我的最终目标是拥有一个如下所示的数据框: 在group()上的熊猫中使用cumsum显示了生成新数据帧的可能性,其中列名SUM_C被替换为累积和。但是,我的要求是将累加总和作为新列添加到现有数据框中。 谢谢 问题答案: 刚申请的 ,并将其分配给一个新的列: 结果:
-
pandas,groupby和count
问题内容: 我有一个这样的数据框说 和会话和收入的每个值代表了一种类型的,我要统计每个种类的数量表示的数量和的为1。 在无法输出所需结果后,我发现简单的调用函数。 我怎样才能做到这一点? 问题答案: 您似乎想一次按几列分组: 应该给你你想要的
-
Python:Dictionary系列的Pandas数据框
问题内容: 我有一个熊猫数据框: 其中包括系列对象: 指出了一些命令: 每个字典具有相同的键: 上面是tweeter API的tweet中字段的命令之一(一部分)。我想根据这些命令构建数据框架。 当我尝试直接制作数据框时,每行仅获得一列,并且此列包含整个字典: 当我尝试使用from_dict()创建数据框时,得到相同的结果: 接下来,我尝试了列表理解,但返回了错误: 当我从单行创建数据框时,它几乎
-
Pandas DataFrame将多列值堆叠到单列中
问题内容: 假设以下DataFrame: 如何将所有key。列的值组合到一个单独的列“ key”中,该列与与key。列对应的主题值相关联?这是我想要的结果: 请注意,key.N列的数量在某些外部N上是可变的。 问题答案: 您可以融化数据框: 它还为您提供了密钥的来源。 从,是第一类功能类:
-
比较两个pandas数据框的差异
问题内容: 我有一个脚本可以更新5-10列的数据,但有时起始csv与结束csv相同,因此我不想写相同的csvfile,而是希望它不执行任何操作… 如何比较两个数据框以检查它们是否相同? 有任何想法吗? 问题答案: 您还需要小心创建DataFrame的副本,否则csvdata_old将使用csvdata更新(因为它指向相同的对象): 要检查它们是否相等,可以在此答案中使用assert_frame_e
-
如何将SQL查询结果转换为PANDAS数据结构?
问题内容: 在这个问题上的任何帮助将不胜感激。 所以基本上我想对我的SQL数据库运行查询并将返回的数据存储为Pandas数据结构。 我已附上查询代码。 我正在阅读有关Pandas的文档,但是在识别查询的返回类型时遇到了问题。 我试图打印查询结果,但没有提供任何有用的信息。 谢谢!!!! 因此,我有点想了解变量“ resoverall”的格式/数据类型是什么,以及如何将其与PANDAS数据结构一起使
-
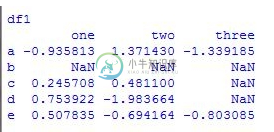 详解pandas删除缺失数据(pd.dropna()方法)
详解pandas删除缺失数据(pd.dropna()方法)本文向大家介绍详解pandas删除缺失数据(pd.dropna()方法),包括了详解pandas删除缺失数据(pd.dropna()方法)的使用技巧和注意事项,需要的朋友参考一下 1.创建带有缺失值的数据库: 查看数据内容: 2.通常情况下删除行,使用参数axis = 0,删除列的参数axis = 1,通常不会这么做,那样会删除一个变量。 删除后结果: 以上就是本文的全部内容,希望对大家的学习有所
-
pandas的行动设置了复制警告
问题内容: 我试图“删除”某列并用 我得到的这条线 有什么问题吗? 问题答案: 你的“df2”是另一个数据帧的一部分。你需要显式地复制它 在尝试“drop”之前使用`df2=df2.copy()`` 考虑以下数据帧: 让我把“df1”的一部分分配给 `df2现在是df1的一部分,应该会触发那些讨厌的东西 `如果我们试图更改“df2”中的内容,请使用copywarning设置。我们来一杯 No pr
-
Pandas之MultiIndex对象的示例详解
本文向大家介绍Pandas之MultiIndex对象的示例详解,包括了Pandas之MultiIndex对象的示例详解的使用技巧和注意事项,需要的朋友参考一下 约定 MultiIndex MultiIndex表示多级索引,它是从Index继承过来的,其中多级标签用元组对象来表示。 一、创建MultiIndex对象 创建方式一:元组列表 代码结果: 代码结果: 0 1 2 class1 class2
-
Pandas之ReIndex重新索引的实现
本文向大家介绍Pandas之ReIndex重新索引的实现,包括了Pandas之ReIndex重新索引的实现的使用技巧和注意事项,需要的朋友参考一下 约定: ReIndex重新索引 reindex()是pandas对象的一个重要方法,其作用是创建一个新索引的新对象。 一、对Series对象重新索引 代码结果: d 1 c 7 a 3 f 9 dtype: int64 调用re
-
Pandas使用的注意事项
主要内容:if语句使用,布尔运算,isin()操作,reindex()操作Pandas 基于 NumPy 构建,它遵循 NumPy 设定的一些规则。因此,当您在使用 Pandas 时,需要额外留意一些事项,避免出现一些不必要的错误。 if语句使用 在 if 语句中,如果您需要将 Pandas 对象转换为布尔值时,需要格外留意,这种操作会引起 ValueError 异常, 下面通过一组示例做简单说明: 输出结果: 从输出结果可以看出,上述代码引发了 ValueError
-
Pandas和NumPy的比较
主要内容:创建数组,布尔索引,重塑数组形状,Pdans与NumPy区别,转换ndarray数组我们知道 Pandas 是在 NumPy 的基础构建而来,因此,熟悉 NumPy 可以更加有效的帮助我们使用 Pandas。 NumPy 主要用 C语言编写,因此,在计算还和处理一维或多维数组方面,它要比 Python 数组快得多。关于 NumPy 的学习,可以参考《 Python NumPy教程》。 创建数组 数组的主要作用是在一个变量中存储多个值。NumPy 可以轻松地处理多维数组,示例如下:
-
Pandas执行SQL操作
主要内容:SELECT,WHERE,GroupBy,LIMIT我们知道,使用 SQL 语句能够完成对 table 的增删改查操作,Pandas 同样也可以实现 SQL 语句的基本功能。本节主要讲解 Pandas 如何执行 SQL 操作。 首先加载一个某连锁咖啡厅地址分布的数据集,通过该数据集对本节内容进行讲解。 输出结果如下: SELECT 在 SQL 中,SELECT 查询语句使用 把要查询的每个字段分开,当然您也可以使用 来选择所有的字段。如下所示: 对