《pandas》专题
-
Pandas库下载和安装
主要内容:Windows系统安装,Linux系统安装,MacOSX系统安装Python 官方标准发行版并没有自带 Pandas 库,因此需要另行安装。除了标准发行版外,还有一些第三方机构发布的 Python 免费发行版, 它们在官方版本的基础上开发而来,并有针对性的提前安装了一些 Python 模块,从而满足某些特定领域的需求,比如专门适应于科学计算领域的 Anaconda,它就提前安装了多款适用于科学计算的软件包。 对于第三方发行版而言,它们已经自带 Pandas 库
-
 Pandas是什么
Pandas是什么主要内容:Pandas主要特点,Pandas主要优势,Pandas内置数据结构Pandas 是一个开源的第三方 Python 库,从 Numpy 和 Matplotlib 的基础上构建而来,享有数据分析“三剑客之一”的盛名(NumPy、Matplotlib、Pandas)。Pandas 已经成为 Python 数据分析的必备高级工具,它的目标是成为强大、灵活、可以支持任何编程语言的数据分析工具。 图1:Pandas Logo Pandas 这个名字来源于面板数据(Panel
-
Pandas创建一个列,该列计算前一列条目的长度,而没有得到设置复制警告
当我看一个类似问题的答案时,如这个链接所示:pandas:以其他列的长度作为值添加列 我遇到了一个问题,它的解决方案是 抛出以下警告 我的问题是:如何做到这一点,以防止出现这种警告?在这个命令中,我希望在原始数据帧中添加一个新列,而不是创建一个片的某种副本。
-
 如何根据特定行的颜色值查询pandas数据帧
如何根据特定行的颜色值查询pandas数据帧并且我想选择所有具有相同值的行作为第一行,我知道我可以查询数据帧后,我得到了x1和x2的值,这段代码。然而,我想要更一般的方式,如果我有更多的功能比x1和x2,说我想做同样的100功能。有没有办法让我接受相似的值? 我也考虑过分组,然后选择包含这一行的组,但我认为有其他更好的方法
-
Pandas:使用循环和分层索引将多个csv文件导入dataframe
我已经找到了许多相关的链接,但我仍然无法得到这个工作: 将多个CSV文件读取到Python Pandas DataFrame中 将多个不同列数的数据帧合并为一个大数据帧 将多个csv文件导入到pandas中并连接到一个Dataframe中
-
在pandas数据框架中转换带有多张表(shett名称中有空格)的excel文件
这些床单是进口的,但我不知道它们的名字。在此之后,我想使用另一个'for',并使用一个pd.merge()来创建一个唯一的dataframe
-
python高效地将多个excel中的所有工作表追加到pandas dataframe中
我有大约20++个xlsx文件,每个xlsx文件中可能包含不同数量的工作表。但是感谢上帝,所有的列都是所有工作表和所有xlsx文件中的一些列。通过参考这里“,我有了一些想法。我一直在尝试几种方法将所有excel文件(所有工作表)导入和追加到一个数据表(大约400万行记录)中。 注意:我也检查了这里“,但它只包括文件级别,我的同意文件和工作表级别。 我的方法是,首先读取每一个excel文件,并在其中
-
使用Pandas DataFrame计算百分比
这5个国家在所有奥运会上获得的奖牌中,每个国家获得的奖牌比例是多少?
-
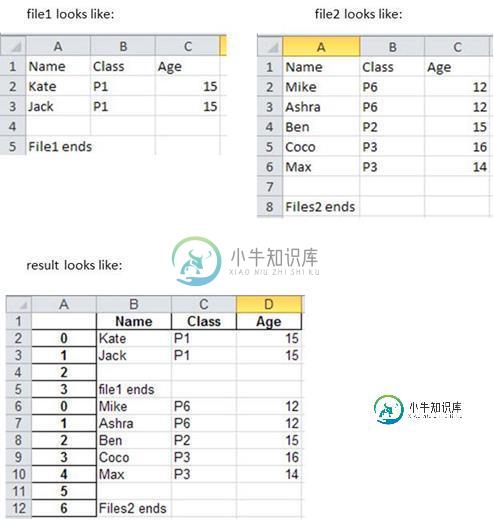 使用pandas组合/合并2个不同的Excel文件/表
使用pandas组合/合并2个不同的Excel文件/表我试图结合2个不同的Excel文件。(多亏了post导入多个excel文件到python pandas中,并将它们连接到一个dataframe中) 到目前为止,我得出的结论是: 下面是他们的样子。 null
-
如何将pandas数据表的索引转换为列
-
使用Pandas递归编辑CSV到子目录
有什么想法吗?
-
如何在pandas中保存每个循环后的。csv中的输出而不重写?
此外,我希望在打印输出时跳过零值行。 这是我的代码:
-
如何使用Pandas从.txt文件解析表
null 我现在的代码: 此代码返回。我知道这是因为对于表行,我使用的是,默认情况下它在空格上拆分。由于有些列缺少值,因此对于第二个和htird表,表头中的元素数和表行中的元素数不匹配。我正在努力解决这个问题,因为表示缺失值的空格字符的数量对于每个表来说是不同的。 我的问题是:是否有一种方法可以解释某些列中丢失的值,以便在丢失值为null或NaN的情况下获得一个DataFrame作为输出?
-
如何从Pandas DataFrame而不是索引和对象类型获取值
我怎样才能只得到值C,而不是整个两行输出?
-
从Numpy数组创建一个Pandas DataFrame:如何指定索引、列和列头?
我有一个Numpy数组,由一系列列表组成,表示一个二维数组,其中包含行标签和列名,如下所示: 但是,我不确定如何最好地分配列标题。