《pandas》专题
-
Python Pandas聚合函数
主要内容:应用聚合函数在《 Python Pandas窗口函数》一节,我们重点介绍了窗口函数。我们知道,窗口函数可以与聚合函数一起使用,聚合函数指的是对一组数据求总和、最大值、最小值以及平均值的操作,本节重点讲解聚合函数的应用。 应用聚合函数 首先让我们创建一个 DataFrame 对象,然后对聚合函数进行应用。 输出结果: 1) 对整体聚合 您可以把一个聚合函数传递给 DataFrame,示例如下: 输出结果: 2)
-
Python Pandas窗口函数
主要内容:rolling(),expanding(),ewm()为了能更好地处理数值型数据,Pandas 提供了几种窗口函数,比如移动函数(rolling)、扩展函数(expanding)和指数加权函数(ewm)。 窗口函数应用场景非常多。举一个简单的例子:现在有 10 天的销售额,而您想每 3 天求一次销售总和,也就说第五天的销售额等于(第三天 + 第四天 + 第五天)的销售额之和,此时窗口函数就派上用场了。 窗口是一种形象化的叫法,这些函数在执行操作时,就
-
Python Pandas统计函数
主要内容:百分比变化(pct_change),协方差(cov),相关系数(corr),排名(rank)Pandas 的本质是统计学原理在计算机领域的一种应用实现,通过编程的方式达到分析、描述数据的目的。而统计函数则是统计学中用于计算和分析数据的一种工具。在数据分析的过程中,使用统计函数有助于我们理解和分析数据。本节将学习几个常见的统计函数,比如百分比函数、协方差函数、相关系数等。 百分比变化(pct_change) Series 和 DatFrames 都可以使用 pct_change() 函数
-
Pandas loc/iloc用法介绍
主要内容:.loc[],.iloc[]在数据分析过程中,很多时候需要从数据表中提取出相应的数据,而这么做的前提是需要先“索引”出这一部分数据。虽然通过 Python 提供的索引操作符 和属性操作符 可以访问 Series 或者 DataFrame 中的数据,但这种方式只适应与少量的数据,为了解决这一问题,Pandas 提供了两种类型的索引方式来实现数据的访问。 本节就来讲解一下,如何在 Pandas 中使用 loc 函数和 iloc
-
Pandas设置数据显示格式
主要内容:get_option(),set_option(),reset_option(),describe_option(),option_context(),常用参数项在用 Pandas 做数据分析的过程中,总需要打印数据分析的结果,如果数据体量较大就会存在输出内容不全(部分内容省略)或者换行错误等问题。Pandas 为了解决上述问题,允许你对数据显示格式进行设置。下面列出了五个用来设置显示格式的函数,分别是: get_option() set_option() reset_option()
-
Python Pandas处理字符串
Pandas 提供了一系列的字符串函数,因此能够很方便地对字符串进行处理。在本节,我们使用 Series 对象对常用的字符串函数进行讲解。 常用的字符串处理函数如下表所示: 函数名称 函数功能和描述 lower() 将的字符串转换为小写。 upper() 将的字符串转换为大写。 len() 得出字符串的长度。 strip() 去除字符串两边的空格(包含换行符)。 split() 用指定的分割符分割
-
Python Pandas去重
主要内容:函数格式,实际应用“去重”通过字面意思不难理解,就是删除重复的数据。在一个数据集中,找出重复的数据删并将其删除,最终只保存一个唯一存在的数据项,这就是数据去重的整个过程。删除重复数据是数据分析中经常会遇到的一个问题。通过数据去重,不仅可以节省内存空间,提高写入性能,还可以提升数据集的精确度,使得数据集不受重复数据的影响。 Panda DataFrame 对象提供了一个数据去重的函数 drop_duplicates(
-
Pandas sorting排序
主要内容:按标签排序,按列标签排序,按值排序,排序算法Pands 提供了两种排序方法,分别是按标签排序和按数值排序。本节讲解 Pandas 的排序操作。 下面创建一组 DataFrame 数据,如下所示: 输出结果: 上述示例,行标签和数值元素均未排序,下面分别使用标签排序、数值排序对其进行操作。 按标签排序 使用 sort_index() 方法对行标签排序,指定轴参数(axis)或者排序顺序。或者可以对 DataFrame 进行排序。默认情况下,按
-
Pandas iteration遍历
主要内容:内置迭代方法,迭代返回副本遍历是众多编程语言中必备的一种操作,比如 Python 语言通过 for 循环来遍历列表结构。那么 Pandas 是如何遍历 Series 和 DataFrame 结构呢?我们应该明确,它们的数据结构类型不同的,遍历的方法必然会存在差异。对于 Series 而言,您可以把它当做一维数组进行遍历操作;而像 DataFrame 这种二维数据表结构,则类似于遍历 Python 字典。 在 Pandas
-
Pandas reindex重置索引
主要内容:重置行列标签,填充元素值,限制填充行数,重命名标签重置索引(reindex)可以更改原 DataFrame 的行标签或列标签,并使更改后的行、列标签与 DataFrame 中的数据逐一匹配。通过重置索引操作,您可以完成对现有数据的重新排序。如果重置的索引标签在原 DataFrame 中不存在,那么该标签对应的元素值将全部填充为 NaN。 重置行列标签 看一组简单示例: 输出结果: 现有 a、b 两个 DataFrame 对象,如果想让 a 的行
-
Pandas使用自定义函数
主要内容:操作整个数据表,操作行或列,操作单一元素如果想要应用自定义的函数,或者把其他库中的函数应用到 Pandas 对象中,有以下三种方法: 1) 操作整个 DataFrame 的函数:pipe() 2) 操作行或者列的函数:apply() 3) 操作单一元素的函数:applymap() 如何从上述函数中选择适合的函数,这取决于函数的操作对象。下面介绍了三种方法的使用。 操作整个数据表 通过给 pipe() 函数传递一个自定义函数和适当数量的参
-
 Pandas描述性统计
Pandas描述性统计主要内容:sum()求和,mean()求均值,std()求标准差,数据汇总描述描述统计学(descriptive statistics)是一门统计学领域的学科,主要研究如何取得反映客观现象的数据,并以图表形式对所搜集的数据进行处理和显示,最终对数据的规律、特征做出综合性的描述分析。Pandas 库正是对描述统计学知识完美应用的体现,可以说如果没有“描述统计学”作为理论基奠,那么 Pandas 是否存在犹未可知。下列表格对 Pandas 常用的统计学函数做了简单的总结: 函数
-
Pandas Panel结构
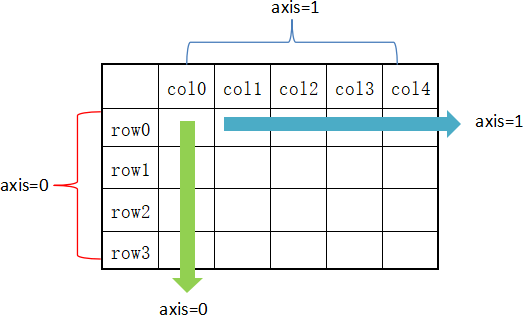
主要内容:pandas.Panel(),创建Panel 对象,Panel中选取数据Panel 结构也称“面板结构”,它源自于 Panel Data 一词,翻译为“面板数据”。如果您使用的是 Pandas 0.25 以前的版本,那么您需要掌握本节内容,否则,作为了解内容即可。 自 Pandas 0.25 版本后, Panel 结构已经被废弃。 Panel 是一个用来承载数据的三维数据结构,它有三个轴,分别是 items(0 轴),major_axis(1 轴),而 minor_a
-
 Pandas DataFrame结构
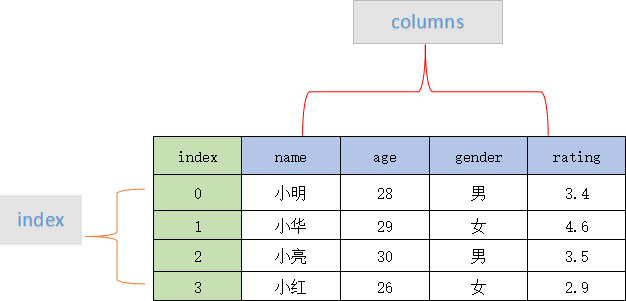
Pandas DataFrame结构主要内容:认识DataFrame结构,创建DataFrame对象,列索引操作DataFrame,行索引操作DataFrame,常用属性和方法汇总DataFrame 是 Pandas 的重要数据结构之一,也是在使用 Pandas 进行数据分析过程中最常用的结构之一,可以这么说,掌握了 DataFrame 的用法,你就拥有了学习数据分析的基本能力。 认识DataFrame结构 DataFrame 一个表格型的数据结构,既有行标签(index),又有列标签(columns),它也被称异构数据表,所谓异
-
 Pandas Series结构
Pandas Series结构主要内容:创建Series对象,访问Series数据,Series常用属性,Series常用方法Series 结构,也称 Series 序列,是 Pandas 常用的数据结构之一,它是一种类似于一维数组的结构,由一组数据值(value)和一组标签组成,其中标签与数据值之间是一一对应的关系。 Series 可以保存任何数据类型,比如整数、字符串、浮点数、Python 对象等,它的标签默认为整数,从 0 开始依次递增。Series 的结构图,如下所示: 通过标签我们可以更加直观地查看数据所在