《pandas》专题
-
 如何使Matplotlib / Pandas条形图看起来像历史图?
如何使Matplotlib / Pandas条形图看起来像历史图?问题内容: 由于在一些数据,,之间是有差异 直接调用数据进行绘图 计算直方图结果(用),然后用绘制 示例数据生成 绘图 绘图 如何使情节看起来像情节? 为此,用例仅需保存 直方图 数据以供以后使用(以后通常会比原始数据小)。 问题答案: 条形图差异 要获得类似于该图的图,需要对的默认行为进行一些处理。 通过传递x()和y()强制使用实际x数据绘制范围。默认行为是在任意范围内绘制y数据,并将x数据作
-
Pandas: timestamp to datetime
问题内容: I have dataframe and column with dates looks like I use to convert that, but I’m get strange result Maybe I did anything wrong 问题答案: This looks look epoch timestamps which is number of seconds s
-
Reversed cumulative sum of a column in pandas.DataFrame
问题内容: I’ve got a pandas DataFrame with a boolean column sorted by another column and need to calculate reverse cumulative sum of the boolean column, that is, amount of true values from current row to
-
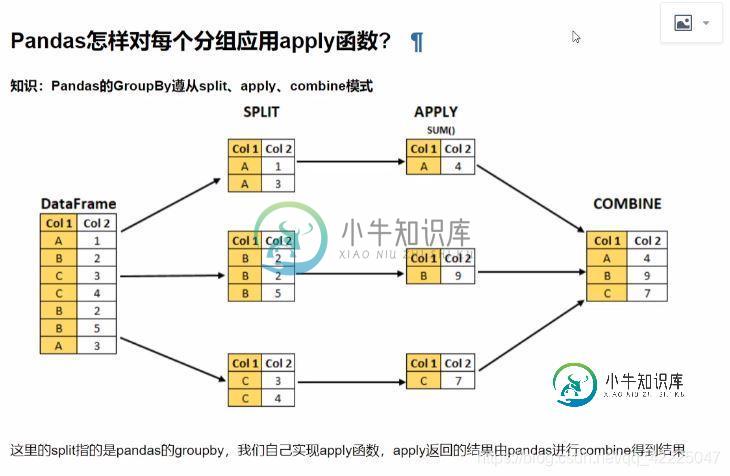 Pandas对每个分组应用apply函数的实现
Pandas对每个分组应用apply函数的实现本文向大家介绍Pandas对每个分组应用apply函数的实现,包括了Pandas对每个分组应用apply函数的实现的使用技巧和注意事项,需要的朋友参考一下 Pandas的apply函数概念(图解) 实例1:怎样对数值按分组的归一化 实例2:怎样取每个分组的TOPN数据 到此这篇关于Pandas对每个分组应用apply函数的实现的文章就介绍到这了,更多相关Pandas 应用apply函数内容请搜索呐
-
pandas groupby与sum()在大型csv文件上?
问题内容: 我有一个大文件(约19GB),我想加载到内存中以对某些列执行聚合。 该文件如下所示: 请注意,在加载到数据帧后,我正在使用列(id,col1)进行聚合,还请注意,这些键可能会连续重复几次,例如: 对于小文件,以下脚本可以完成此工作 但是,对于大文件,我在读取csv文件时需要使用chunksize来限制加载到内存中的行数: 在后一种情况下,如果将(id,col1)相似的行拆分到不同的文件
-
Pandas:合并multiIndex DataFrame的标题行
问题内容: 可以说我有一个DataFrame如下: 我想创建一个新的DataFrame像这样: 可能的代码是什么? 问题答案: 1.使用Python 3.6+更新,使用带有列表理解功能的f字符串格式: 2.使用和: 3.如果您的列具有数字数据类型,请使用和: 输出:
-
计算pandas连续两行之间的时差
问题内容: 我有一个熊猫数据框如下 上面的数据帧有83000行。我想获取两个连续行之间的时间差,并将其保存在单独的列中。理想的结果是 我已经尝试过但出现错误,如下所示 如何解决这个问题 问题答案: 问题是功能需要s或s ,因此首先要转换为,然后得到并除以: 如果需要或每分钟:
-
在pandas DataFrame中将非空单元格移到左侧
问题内容: 假设我有以下形式的数据 我想将所有非南单元格移到左侧(或在新列中收集所有非南数据),同时保留从左到右的顺序, 我当然可以逐行这样做。但是我希望知道是否还有其他方法可以改善性能。 问题答案: 这是我所做的: 我将您的数据框拆开成更长的格式,然后按名称列分组。在每个组中,我放下NaN,然后重新索引到以h4为底的完整h1,从而在右侧重新创建NaN。 所以我得到:
-
为什么在pandas数据框列中应用更改dtype
问题内容: 我有以下数据框: 对于列: 但是使用它们之后,所有更改都变为对象: 为什么要反对?我认为应该只考虑列。 问题答案: 您可以在此处使用参数和更多信息: 在较新版本的熊猫中可以使用:
-
哪个是有效的,使用sql联接查询或使用pandas合并查询?
问题内容: 我想使用中的多个表中的数据。我有两种从服务器下载数据的想法,一种方法是使用联接和检索数据,一种方法是分别下载数据帧并使用pandas.merge合并它们。 当我想将数据下载到。 熊猫合并 哪一个更快?假设我要对2个以上的表和2个列执行此操作。有什么更好的主意吗?如果有必要知道我使用。 问题答案: 前者比后者快。前者仅需对数据库进行一次调用,并返回已加入并已过滤的结果。但是,后者对数据库
-
如何在字符串包含上合并pandas?
问题内容: 我有2个数据框,我想将它们合并到一个公共列上。但是,我要合并的列不是同一字符串,而是另一个中包含一个字符串,如下所示: 我想要的结果如下: 问题答案: 新答案 这是一种基于pandas / numpy的方法。 旧答案 这是左联接行为的一种解决方案,因为它不会保留不匹配任何值的值。这比上面的numpy / pandas解决方案要慢,因为它使用两个嵌套循环来构建python列表。
-
Pandas从字符串中替换(擦除)不同的字符
问题内容: 我有一份高中清单。我想从字符串中删除某些字符,单词和符号。 我目前有: 不过,我想用一个列表,以便我能快捷地更换,,,等。 有什么建议? 不起作用 问题答案: 使用正则表达式(用分隔字符串):
-
不区分大小写的pandas dataframe.merge
问题内容: 我正在用最简单的方法在熊猫中进行不区分大小写的合并。有没有一种方法可以正确地在合并?我是否需要使用(?i)或带有ignorecase的正则表达式?在下面的代码段中,我加入了一些国家,其中一个文件中可能是“美国”,另一个文件中可能是“美国”,我只是想把这种情况排除在外。谢谢! 问题答案: 将用于合并的两列中的值小写,然后在小写列中合并
-
通过pandas数据框按pandas ID中的两个日期之间的行数进行计数
问题内容: 我有以下测试DataFrame: 它给出了如下所示的数据框,其中包含公司ID列“ cid”,唯一ID列“ jid”,开始日期“ stdt”和enddt“ enddt”。 我需要做的是: 计算min(stdt)和max(enddt)之间每个date(newdate)的cid发生的jid数目,其中newdate在stdt和enddt之间。 结果数据集应为每个cid具有一个数据帧,该数据帧的
-
pandas to_datetime解析错误的年份
问题内容: 我遇到的事情几乎可以肯定是我自己的一个愚蠢的错误,但是我似乎无法弄清楚发生了什么。 本质上,我有一系列日期,例如格式的字符串。当我将其转换为日期时间时,年份有时是正确的,但有时并非如此。 例如: 最后两个条目错误,这些年份返回的年份分别为2061和2055。但这对于入门来说效果很好。这里发生了什么? 问题答案: 这似乎是Python库datetime的行为,我做了一个测试,以了解临界点