《pandas》专题
-
在pandas dataframe中选择行[重复]
我需要选择满足以下条件的行: 如果(X为真,Z为假)(X为假,Z为真),则将True作为值赋给新列。 我试过这个: 但是我得到了以下错误: ValueError:序列的真值不明确。使用a.empty、a.bool()、a.item()、a.any()或a.all()。 我尝试使用任何(),如下所示
-
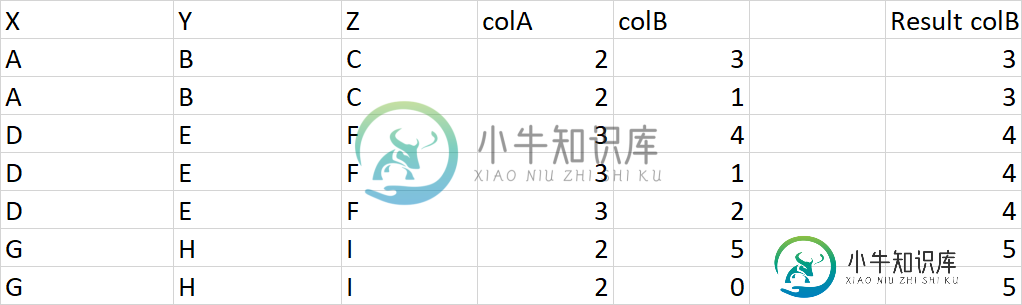 Pandas根据groupby对象的特定条件更新列值
Pandas根据groupby对象的特定条件更新列值我有一个pandas数据帧,其中3列X、Y和Z用于分组。我想基于代码中显示的条件为每个组更新列B(或将其存储在单独的列中)。但我得到的最后结果是零。我不确定我做错了什么。 下面是供参考的表格和代码:
-
Python-如何用pandas读取6gb csv文件
问题内容: 我正在尝试在pandas中读取较大的csv文件(大约6 GB),并且遇到以下内存错误: 任何帮助吗? 问题答案: 该错误表明机器没有足够的内存来一次将整个CSV读入。假设你一次也不需要整个数据集都在内存中,那么避免该问题的一种方法是分批处理CSV(通过指定chunksize参数): 该参数指定每个块的行数。(当然,最后一块可能少于行。)
-
Python-Pandas分组和总和
问题内容: 我正在使用此数据框: 我想按名称然后按水果进行汇总,以获得每个名称的水果总数。 我尝试按名称和水果分组,但如何获取水果总数。 问题答案: 使用方法
-
Pandas条件创建series/dataframe列
问题内容: 我有下面的数据框: 我想向数据框添加另一列(或生成一系列),该列与数据框的长度相同,如果Set =’Z’则将颜色设置为green ,如果. 最好的方法是什么? 问题答案: 如果你只有两种选择: 例如, 输出 如果你有两个以上的条件,请使用。例如,如果你想成为 when otherwise when otherwise when otherwise , 然后使用 输出:
-
如何在SQL中使用'in'和'not in'过滤Pandas数据帧
问题内容: 怎样才能达到和的等效? 我有一个包含所需值的列表。这是案例: 我目前的做法如下: 但这似乎是一个可怕的冲突。有人可以改进吗? 问题答案: 您可以使用。 对于”IN”使用: 或对于”NOT IN”: 作为一个工作示例:
-
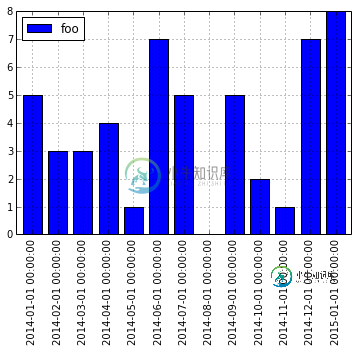 在matplotlib中格式化日期时间xlabel(pandas df.plot()方法)
在matplotlib中格式化日期时间xlabel(pandas df.plot()方法)问题内容: 我不知道如何更改这些x标签的格式。理想情况下,我想请他们。我已经尝试过类似的操作,但是没有成功。 问题答案: 在对象DF的对象。调用每个对象: 与截断ticklabel字符串相比,这提供了更通用的格式设置选项。
-
使用pandas的“大数据”工作流
几个月来,我在学习熊猫的过程中,一直在努力想出这个问题的答案。我在日常工作中使用SAS,它的核心支持很棒。然而,SAS作为一个软件是可怕的,还有许多其他原因。 有一天我希望用python和pandas取代我对SAS的使用,但我目前缺少一个用于大型数据集的非核心工作流。我说的不是需要分布式网络的“大数据”,而是大到内存放不下但小到硬盘驱动器放不下的文件。 我的第一个想法是使用在磁盘上保存大型数据集,
-
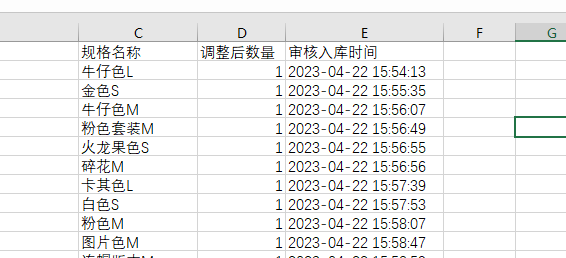 python - 求助,pandas 把csv文件另存为xlsx文件后 为什么再次读取xlsx里面的时间值就变成NaN了?
python - 求助,pandas 把csv文件另存为xlsx文件后 为什么再次读取xlsx里面的时间值就变成NaN了?这是csv文件 这是另存为的xlsx文件 为什么审核入库时间列的值全变成NaN了?
-
5. Pandas 数据结构
本节介绍 Pandas 基础数据结构,包括各类对象的数据类型、索引、轴标记、对齐等基础操作。首先,导入 NumPy 和 Pandas: In [1]: import numpy as np In [2]: import pandas as pd “数据对齐是内在的”,这一原则是根本。除非显式指定,Pandas 不会断开标签和数据之间的连接。 下文先简单介绍数据结构,然后再分门别类介绍每种功能与
-
4. Pandas 10大新功能
4.1. 四个置顶的警告! 从 0.25 起,pandas 只支持 Python 3.53 及以上版本了,不再支持 Python 2.7,还在使用 Python 2 的朋友可要注意了,享受不了新功能了,不过,貌似用 Python 2 做数据分析这事儿估计已经绝迹了吧! 下一版 pandas 将只支持 Python 3.6 及以上版本了,这是因为 f-strings 的缘故吗?嘿嘿。 彻底去掉了 P
-
3. Pandas 25 式
Kevin Markham,数据科学讲师,2002 年,毕业于范德堡大学,计算机工程学士,2014 年,创建了 Data School,在线教授 Python 数据科学课程,他的课程主要包括 Pandas、Scikit-learn、Kaggle 竞赛数据科学、机器学习、自然语言处理等内容,迄今为止,浏览量在油管上已经超过 500 万次。 Kevin 还是 PyCon 培训讲师,主要培训课程如下:
-
2. Pandas 基础用法
本节介绍 Pandas 数据结构的基础用法。下列代码创建上一节用过的示例数据对象: In [1]: index = pd.date_range('1/1/2000', periods=8) In [2]: s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e']) In [3]: df = pd.DataFrame(np
-
1. Pandas 概览
Pandas 是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。Pandas 的目标是成为 Python 数据分析实践与实战的必备高级工具,其长远目标是成为最强大、最灵活、可以支持任何语言的开源数据分析工具。经过多年不懈的努力,Pandas 离这个目标已经越来越近了。 Pandas 适用于处理以下类型的数据: 与 SQL 或 Exce
-
Pandas 教程
本专题主要介绍 Pandas0.25+ 库的内容: 1. Pandas 概览 1.1. 数据结构 1.2. 大小可变与数据复制 1.3. 获得支持 1.4. 社区 1.5. 项目监管 1.6. 开发团队 1.7. 机构合作伙伴 1.8. 许可协议 2. Pandas 基础用法 2.1. Head 与 Tail 2.2. 属性与底层数据 2.3. 加速操作 2.4. 二进制操作 2.5. 描述性统计