
Pandas根据groupby对象的特定条件更新列值

我有一个pandas数据帧,其中3列X、Y和Z用于分组。我想基于代码中显示的条件为每个组更新列B(或将其存储在单独的列中)。但我得到的最后结果是零。我不确定我做错了什么。
下面是供参考的表格和代码:
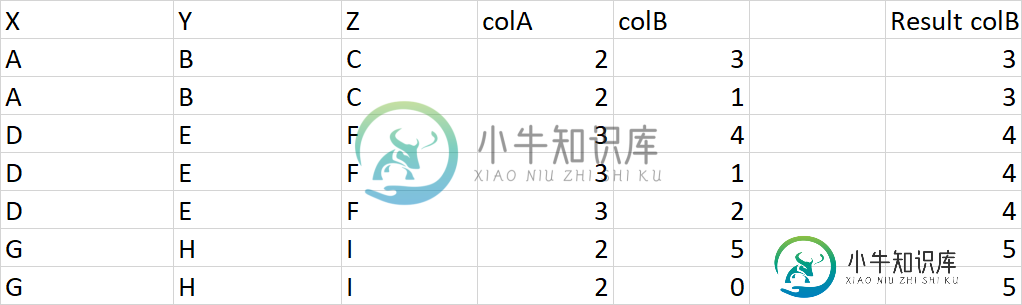
group=df.groupby(['X','Y','Z'])
for a,b in group:
if ((b.colA==2).all()):
df['colB']=b.colB.max()
elif (((b.colA>2).all()) and (b.colB.max() >=2)):
df['colB']=b.colB.max()
else:
df['colB']=np.nan
共有1个答案

使用groupby.transform标识条件,然后使用where掩码:
groups = df.df.groupby(['X','Y','Z'])
min_A = groups['A'].transform('min')
max_A = groups['A'].transform('max')
max_B = groups['B'].transform('max')
df['ret_colB'] = maxB.where( (minA.eq(2) & maxA.eq(2)) | (minA.gt(2) & max_B.ge(2))
-
我有这样的表: 我需要一个更新查询来根据它包含的值更新salary列。 工资需要增加: 10000到15000之间的值为5000 15000到20000之间的值为7000 20000到30000之间的值为8000 40000到60000之间的值为10000
-
问题内容: 从pandas数据框中选择所有行的最简单方法是什么?谁的符号在整个表中恰好出现两次?例如,在下表中,我想选择在[‘b’,’e’]中带有sym的所有行,因为这些符号的value_counts等于2。 问题答案: 我认为您可以按列和值使用: 第二个解决方案使用与布尔索引: 并用最快的解决方案和:
-
问题内容: 我遇到了一个mongo问题。我想知道是否有办法做一个蒙戈控制台命令而不是多个以下和电话。 我想用这个新的数组项更新对象 我使用了此方法,它是有限的,如果它已经存在,它不会将一个项目插入数组,但不会基于标识符更新项目。在这种情况下,我真的很想根据来更新此条目。 这给了我: 当我真正想要的是: 问题答案: 您可以使用位置运算符执行此操作: 的在更新对象充当的第一个元素的占位符到查询选择器相
-
问题内容: 这个问题已经在这里有了答案 : SQL UPDATE SET哪一列等于另一列引用的相关表中的值? (10个答案) 7年前关闭。 我有两张桌子 table1(id,item,price)值: .... table2(id,item,price)值: 现在我要: 我该怎么做? 问题答案: 这样的事情应该做到: 您也可以尝试以下操作:
-
问题内容: 我有一张地图,如下所示: 如您所见,将有一个名为split的最终常量,其值为40 我必须实现逻辑,例如,如果映射的值达到40,那么从计算开始的映射的第一个键以及恰好达到40的键也将被选择为min和max,如上所述。 。 除此之外,如果总和超过40,则需要格外小心。如果是,我们必须忽略它,并且在最小值和最大值相等的情况下,将先前的值本身作为最小值和最大值。 请建议我如何使用Java和。乡
-
问题内容: 我想从Java中删除符合条件的元素。 即: 我能理解为什么这行不通,但是什么是这样做的好方法? 问题答案: 您必须使用和来迭代迭代器(而不是列表)的功能: 注意,迭代器#删除功能被认为是optionnal,但它 是 由ArrayList的迭代器来实现。 这是ArrayList.java中此具体功能的代码: 这行代码就是为什么在迭代时使用它时不会抛出异常。