《pandas》专题
-
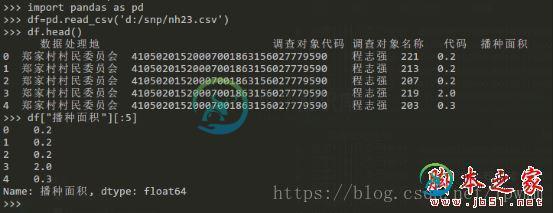 Python使用Pandas对csv文件进行数据处理的方法
Python使用Pandas对csv文件进行数据处理的方法本文向大家介绍Python使用Pandas对csv文件进行数据处理的方法,包括了Python使用Pandas对csv文件进行数据处理的方法的使用技巧和注意事项,需要的朋友参考一下 今天接到一个新的任务,要对一个140多M的csv文件进行数据处理,总共有170多万行,尝试了导入本地的MySQL数据库进行查询,结果用Navicat导入直接卡死....估计是XAMPP套装里面全默认配置的MySQL性能不
-
从Pandas数据框中填充QTableView的最快方法
问题内容: 我是PyQt的新手,正在努力填充QTableView控件。 我的代码如下: 实际上,在代码中,我成功地填充了QListView,但是未显示我设置为QTableView的值,您还可以看到我将行截断为10,因为它永远需要显示数据帧的数百行。 那么,从熊猫数据框中填充表模型的最快方法是什么? 提前致谢。 问题答案: 就我个人而言,我将创建自己的模型类以使其处理起来更加容易。 例如:
-
在pandas.DataFrame的对角线上设置值
问题内容: 我有一个熊猫数据框,我想将对角线设置为0 现在我想将对角线设置为0: 但是必须有比这更Python化的方式!? 问题答案: 请注意,这仅在行数与列数相同时起作用。适用于任意形状的另一种方法是使用np.fill_diagonal:
-
Python和Pandas:如何查询列表类型列是否包含某些内容?
问题内容: 我有一个数据框,其中包含有关电影的信息。它有一个名为的列,其中包含它所属的流派列表。例如: 我想知道如何查询数据框,以便它返回属于某个类型的电影? 例如,可能会返回0或1。 我知道列表,可以做以下事情: 但是,在大熊猫中,我找不到类似的东西,我唯一知道的是,但它不适用于列表类型。 问题答案: 您可以使用create ,然后:
-
 Pandas读取并修改excel的示例代码
Pandas读取并修改excel的示例代码本文向大家介绍Pandas读取并修改excel的示例代码,包括了Pandas读取并修改excel的示例代码的使用技巧和注意事项,需要的朋友参考一下 一、前言 最近总是和excel打交道,由于数据量较大,人工来修改某些数据可能会有点浪费时间,这时候就使用到了Python数据处理的神器—–Pandas库,话不多说,直接上Pandas。 二、安装 这次使用的python版本是python2.7,安装py
-
如何在前瞻性的基础上使用Pandas rolling_ *函数
问题内容: 假设我有一个时间序列: 如果使用rolling_ *函数之一,例如rolling_sum,则可以得到想要的行为,用于向后看的滚动计算: 但是,如果我想做一笔前瞻性的款项怎么办?我已经尝试过这样的事情: 但这不完全是我想要的行为。我正在寻找的输出是: 即-我想要“当前”天加上接下来的两天的总和。我目前的解决方案还不够,因为我担心边缘会发生什么。我知道我可以通过设置两个分别移动1天和2天的
-
如何在Pandas数据框中查找哪些列包含任何NaN值
问题内容: 给定一个熊猫数据框,其中包含可能在此处和附近散布的NaN值: 问题: 如何确定哪些列包含NaN值?特别是,我可以获取包含NaN的列名称的列表吗? 问题答案: 更新: 使用熊猫0.22.0 较新的Pandas版本具有新的方法‘DataFrame.isna()’和‘DataFrame.notna()’ 作为列列表: 选择这些列(至少包含一个值): 旧答案: 尝试使用isnull(): 或作
-
在pandas的DataFrame中搜索“不包含”
问题内容: 我已经进行了一些搜索,无法弄清楚如何通过过滤数据帧,但是我想知道是否有一种方法可以反向执行:通过该集合的补充来过滤数据帧。例如:达到的效果。 可以通过一种方法来完成吗? 问题答案: 您可以使用invert(〜)运算符(其作用类似于非布尔数据): ,RHS返回的副本在哪里。 包含还接受正则表达式… 如果以上方法引发ValueError,则可能是由于您混合使用了数据类型,所以请使用: 要么
-
如何使用iPython中的pandas库读取.xlsx文件?
问题内容: 我想使用python的Pandas库读取.xlsx文件,并将数据移植到postgreSQL表中。 到目前为止,我所能做的就是: 现在,我知道该步骤已成功执行,但是我想知道如何解析已读取的excel文件,以便可以了解excel中的数据如何映射到变量数据中的数据。 我没弄错,数据就是Dataframe对象。因此,我如何解析此dataframe对象以逐行提取每一行。 问题答案: 我通常会为每
-
将多个列值合并到python pandas的一列中
问题内容: 我有一个这样的熊猫数据框: 我现在想做的是获取一个包含Column1和新columnA的新数据框。此columnA应该包含第2列-(to)n的所有值(其中n是从Column2到行尾的列数),如下所示: 我如何最好地解决这个问题?任何意见将是有益的。提前致谢! 问题答案: 您可以按行调用pass ,然后将dtype转换为和: 在这里,我呼吁摆脱,但是我们需要再次强制转换为,这样我们才不会
-
在DataFrame Pandas中添加带有日期之间的天数的列
问题内容: 我想从“ B”中的日期中减去“ A”中的日期,并添加一个具有差异的新列。 我尝试了以下操作,但是在尝试将其包含在for循环中时出现错误… 我该怎么办? 问题答案: 假设这些是datetime列(如果不适用),则可以减去它们: 注意:请确保您使用的是新熊猫(例如0.13.1),这可能在较旧的版本中不起作用。
-
Pandas / Python:根据另一列中的值设置一列的值
问题内容: 我需要基于Pandas数据框中的另一列的值来设置一列的值。这是逻辑: 我无法做到这一点,我想要做的就是简单地创建一个具有新值的列(或更改现有列的值:任何一个都对我有用)。 如果我尝试运行上面的代码,或者将其编写为函数并使用apply方法,则会得到以下信息: 问题答案: 一种方法是将索引与配合使用。 例 在没有示例数据框的情况下,我将在此处进行补充: 假设您想 创建一个新列 ,除wher
-
Pandas数据框中的值的向量化查找
问题内容: 我有两个熊猫数据框,一个叫做“ orders”,另一个叫做“ daily_prices”。daily_prices如下: 订单如下: 两个数据帧的索引均为datetime.date。通过使用列表解析来遍历所有订单并在“ daily_prices”数据框中查找特定日期的特定报价,然后将该列表作为列添加到“订单”数据框中的“价格”列。 “订单”数据框。我想使用数组操作而不是循环执行此操作。
-
 详解pandas.DataFrame中删除包涵特定字符串所在的行
详解pandas.DataFrame中删除包涵特定字符串所在的行本文向大家介绍详解pandas.DataFrame中删除包涵特定字符串所在的行,包括了详解pandas.DataFrame中删除包涵特定字符串所在的行的使用技巧和注意事项,需要的朋友参考一下 你在使用pandas处理DataFrame中是否遇到过如下这类问题?我们需要删除某一列所有元素中含有固定字符元素所在的行,比如下面的例子: 以上所述是小编给大家介绍的pandas.DataFrame中删除
-
pandas 数据结构之Series的使用方法
本文向大家介绍pandas 数据结构之Series的使用方法,包括了pandas 数据结构之Series的使用方法的使用技巧和注意事项,需要的朋友参考一下 1. Series Series 是一个类数组的数据结构,同时带有标签(lable)或者说索引(index)。 1.1 下边生成一个最简单的Series对象,因为没有给Series指定索引,所以此时会使用默认索引(从0到N-1)。 1.2 当要