
使用pandas库对csv文件进行筛选保存

这个操作现在看来真没啥难的,但是我找相关的资料真的找了好久。
多数大佬都是直接pandas官网甩我脸上,然后举一个入门级的例子。
https://pandas.pydata.org/docs/reference/index.html
首先导入pandas库
import pandas as pd
然后使用read_csv来打开指定的csv文件
df = pd.read_csv('./IP2LOCATION.csv',encoding= 'utf-8')
这个函数里面需要写入csv文件的路径,如果是把csv文件保存到了python的工程文件夹下,则只需要./文件名即可,然后encoding='utf-8'是使用utf-8方式编码,有时候需要换成gbk。
虽然我们读取的是csv文件,但其实由于我们使用的是pandas库,所以我们实际获得的是一个DataFrame的数据结构。
可以使用print(type(df))进行检验
print(type(df))

DataFrame 是表格型的数据结构。因此,我们可以将其当做表格。DataFrame 是以表格类似展示,而且还包含行标签、列标签。
我们可以添加一个列标签,使用方法为pandas.DataFrame.columns
在我们的例子中DataFrame类型的变量为df,因此使用方法为df.columns,我们添加的列标签为a、b、c、d、e、f
df.columns = ['a','b','c','d','e','f']
然后,我们想把某一列中等于特定值的那些行提取出来
可以将读出来的内容当做一个列表,然后这个列表的html" target="_blank">元素是表中的每一行,然后这每一行也是一个列表,也就是列表中的列表。
比如,我想将表中第5列中值为Andhra Pradesh的行提取出来,并且由于我们之前定义了第五列的列标签为e
因此代码为:
data = df[df['e'] == 'Andhra Pradesh']
最后我们可以通过pandas中的to_csv,来将筛选出来的数据保存到新的csv文件中。
data.to_csv('my_IP2LOCATION.csv')
用法为表名.to_csv('所要保存地方的路径/表名.csv')
最后总结一下我们的代码
import pandas as pd
df = pd.read_csv('./IP2LOCATION.csv',encoding= 'utf-8')
# print(type(df))
df.columns = ['a','b','c','d','e','f']
data = df[df['e'] == 'Andhra Pradesh']
data.to_csv('my_IP2LOCATION.csv')
IP2LOCATION.csv内容如下:
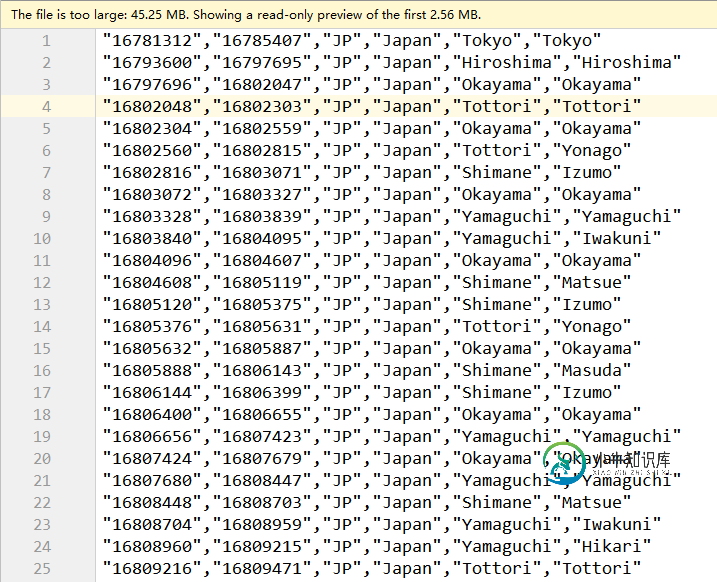
总共有759727行
然后经过我们的筛选后的my_IP2LOCATION.csv
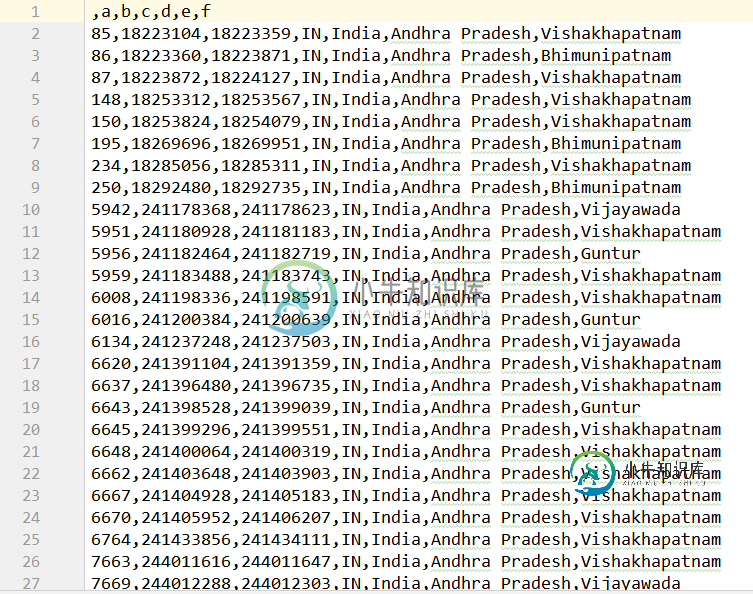
只有3461行
PS:可以使用print(len(df.values))来查看行数
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
本文向大家介绍Python使用Pandas对csv文件进行数据处理的方法,包括了Python使用Pandas对csv文件进行数据处理的方法的使用技巧和注意事项,需要的朋友参考一下 今天接到一个新的任务,要对一个140多M的csv文件进行数据处理,总共有170多万行,尝试了导入本地的MySQL数据库进行查询,结果用Navicat导入直接卡死....估计是XAMPP套装里面全默认配置的MySQL性能不
-
本文向大家介绍使用NumPy和pandas对CSV文件进行写操作的实例,包括了使用NumPy和pandas对CSV文件进行写操作的实例的使用技巧和注意事项,需要的朋友参考一下 数组存储成CSV之类的区隔型文件: 下面代码给随机数生成器指定种子,并生成一个3*4的NumPy数组 将一个数组元素的值设为NaN: NumPy的savetxt()函数是与loadtxt()相对应的一个函数,它能以诸如CSV
-
我有以下pom.xml: 注意,上的元素被注释掉了 在中还有以下内容 因此,我希望Maven做的只是用替换,除非开发配置文件被激活,否则我希望Maven用替换 当我运行时,它将值设置为。很好,资源筛选工作正常。 但是,当我运行时,它将值设置为 如果取消对配置文件上的元素的注释并运行,则会将设置为 我甚至运行了让它输出活动的配置文件名称,并且在上面的两种情况下,它都表示开发配置文件是活动的,但是如果
-
我有一个文档索引。我想过滤公共文档或由我的组成员(用户1和3)共享给组的文档。 隐私="公共"或(1,3)中的隐私="组"和user_id) 我可以分开做,但是如何将它们与OR结合起来? 文件: {“id”:1,“user_id”:1, “隐私”:“公共”,“标题”:“为一个人做饭”,} {“id”:3,“user_id”:1, “隐私”:“组”,“标题”:“三的公司”} {“id”:4,“use
-
对理解这一差异的任何帮助都是感激的。
-
主要内容:read_csv(),to_csv()在《 Python Pandas读取文件》中,我们讲解了多种用 Pandas 读写文件的方法。本节我们讲解如何应用这些方法 。 我们知道,文件的读写操作属于计算机的 IO 操作,Pandas IO 操作提供了一些读取器函数,比如 pd.read_csv()、pd.read_json 等,它们都返回一个 Pandas 对象。 在 Pandas 中用于读取文本的函数有两个,分别是: read_csv(