
Logistic Regression(LR)
LogisticRegression
逻辑回归模型(logistic regression model)是一种分类模型。它是最常见和常用的一种分类方法,在传统的广告推荐中被大量使用,朴实但有效。
1. 算法介绍
Logistic Regression
逻辑回归模型(logistic regression model)是一种分类模型。样本x属于类别y的概率P(y|x)服从logistic分布:

综合两种情况,有:
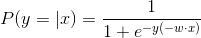
逻辑回归模型使用log损失函数,带L2惩罚项的目标函数如下所示:
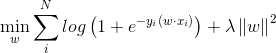
其中: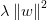 为L2正则项。
为L2正则项。
2. Logistic Regression on Angel
- angel提供了用mini-batch gradient descent优化方法求解的Logistic Regression算法,算法逻辑如下

逻辑回归算法的模型仅由单个输入层组成,该输入层可为“dense”或“sparse”,该层的输出即为模型的输出结果,即分类结果。
logistic regression训练过程 Angel实现了用梯度下降方法优化,迭代训练得到LR模型,每次迭代worker和PS上的逻辑如下:
- worker:每次迭代从PS上拉取矩阵对应的权重向量到本地,计算出对应的梯度更新值,push到PS对应的梯度向量上。注意,此处的会根据worker端每个样本对应的特征索引拉取对应的模型权重,这样做可减小通信成本同时节约内存以提高计算效率
- PS:PS汇总所有worker推送的梯度更新值,取平均,通过优化器计算新的模型权重并进行相应更新
LR预测结果:
- 格式:rowID,pred,prob,label
- 说明:rowID表示样本所在的行ID,从0开始计数;pred:样本的预测结果值;prob:样本相对该预测结果的概率;label:预测样本被分到的类别,当预测结果pred大于0时,label为1,小于0为-1
3. 运行 & 性能
输入格式
LR on Angel支持“dense”、“libsvm”、“dummy”三种数据格式。其中“dense”即为一般的数据表格式,每列表示相应的特征,各特征之间用空格或逗号隔开,此处不再详述。下面重点说下“dummy”和“libsvm”格式:
- dummy格式
每行文本表示一个样本,每个样本的格式为"y index1 index2 index3 ..."。其中:index特征的ID;训练数据的y为样本的类别,可以取1、-1两个值;预测数据的y为样本的ID值。比如,属于正类的样本[2.0, 3.1, 0.0, 0.0, -1, 2.2]的文本表示为“1 0 1 4 5”,其中“1”为类别,“0 1 4 5”表示特征向量的第0、1、4、5个维度的值不为0。同理,属于负类的样本[2.0, 0.0, 0.1, 0.0, 0.0, 0.0]被表示为“-1 0 2”。
- libsvm格式
每行文本表示一个样本,每个样本的格式为"y index1:value1 index2:value1 index3:value3 ..."。其中:index为特征的ID,value为对应的特征值;训练数据的y为样本的类别,可以取1、-1两个值;预测数据的y为样本的ID值。比如,属于正类的样本[2.0, 3.1, 0.0, 0.0, -1, 2.2]的文本表示为“1 0:2.0 1:3.1 4:-1 5:2.2”,其中“1”为类别,"0:2.0"表示第0个特征的值为2.0。同理,属于负类的样本[2.0, 0.0, 0.1, 0.0, 0.0, 0.0]被表示为“-1 0:2.0 2:0.1”。
参数
参数说明
- ml.epoch.num:迭代轮数
- ml.feature.index.range:特征索引范围
- ml.model.size:特征维数
- ml.data.validate.ratio:验证集采样率
- ml.data.type:数据类型,分“libsvm”和“dummy”两种
- ml.learn.rate:学习率
- ml.opt.decay.class.name:学习率衰减系类
- ml.opt.decay.on.batch: 是否对每个mini batch衰减
- ml.opt.decay.alpha: 学习率衰减参数alpha
- ml.opt.decay.beta: 学习率衰减参数beta
- ml.opt.decay.intervals: 学习率衰减参数intervals
- ml.reg.l2: l2正则项系数
- action.type:任务类型,训练用"train",预测用"predict"
- ml.inputlayer.optimizer:优化器类型,可选"adam","ftrl"和"momentum"
- ml.data.label.trans.class: 是否要对标签进行转换, 默认为"NoTrans", 可选项为"ZeroOneTrans"(转为0-1), "PosNegTrans"(转为正负1), "AddOneTrans"(加1), "SubOneTrans"(减1).
- ml.data.label.trans.threshold: "ZeroOneTrans"(转为0-1), "PosNegTrans"(转为正负1)这两种转还要以设一个阈值, 大于阈值的为1, 阈值默认为0
- ml.data.posneg.ratio: 正负样本重采样比例, 对于正负样本相差较大的情况有用(如5倍以上)
提交命令 你可以通过下面命令向Yarn集群提交LR算法训练任务:
../../bin/angel-submit \ -Dml.epoch.num=20 \ -Dangel.app.submit.class=com.tencent.angel.ml.core.graphsubmit.GraphRunner \ -Dml.model.class.name=com.tencent.angel.ml.classification.LogisticRegression \ -Dml.feature.index.range=$featureNum \ -Dml.model.size=$featureNum \ -Dml.data.validate.ratio=0.1 \ -Dml.data.type=libsvm \ -Dml.learn.rate=0.1 \ -Dml.reg.l2=0.03 \ -Daction.type=train \ -Dml.inputlayer.optimizer=ftrl \ -Dangel.train.data.path=$input_path \ -Dangel.workergroup.number=20 \ -Dangel.worker.memory.mb=20000 \ -Dangel.worker.task.number=1 \ -Dangel.ps.number=20 \ -Dangel.ps.memory.mb=10000 \ -Dangel.task.data.storage.level=memory \ -Dangel.job.name=angel_l1
项目地址:https://github.com/Angel-ML/angel
官网:https://angelml.ai/