
Angel 中优化器
Angel中的优化器
机器学习的优化方法多种多样, 但在大数据场景下, 使用最多的还是基于SGD的一系列方法. 在Angel中目前只实现了少量的最优化方法, 如下:
- 基于随机梯度下降的方法
- SDG: 这里指mini-batch SGD (小批量随机梯度下降)
- Momentum: 带动量的SGD
- AdaGrad: 带Hessian对角近似的SGD
- AdaDelta:
- Adam: 带动量与对角Hessian近似的SGD
- 在线学习方法
- FTRL: Follow The Regularized Leader, 一种在线学习方法
1. SGD
SGD的更新公式如下:
其中, .
json方式表达有两种, 如下:
"optimizer": "sgd",
"optimizer": {
"type": "sgd",
"reg1": 0.01,
"reg2": 0.02
}
2. Momentum
Momentum的更新公式如下:
其中, 的更新公式如下:
其中, 是一个初值为1, 极限为1的函数, 中间过程先减后增, 如下图所示: 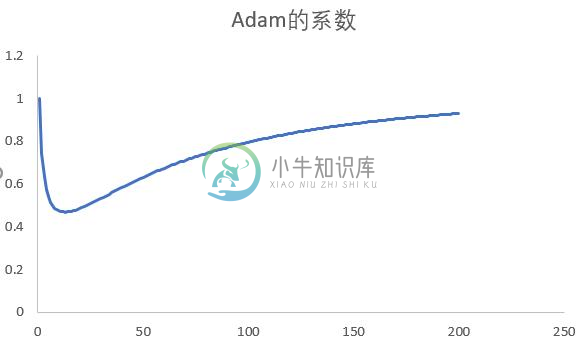
即在优化的初始阶段, 梯度较大, 适当地减小学习率, 让梯度下降缓和平滑; 在优化的最后阶段, 梯度很小, 适当地增加学习率有助于跳出局部最优.
json方式表达有两种, 如下:
"optimizer": "adam",
"optimizer": {
"type": "adam",
"beta": 0.9,
"gamma": 0.99,
"reg2": 0.01
}
4. FTRL
FTRL是一种在线学习算法, 它的目标是优化regret bound, 在一定的学习率衰减条件下, 可以证明它是有效的.
FTRL的另一个特点是可以得到非常稀疏的解, 表现上比PGD(proximal gradient descent)好, 也优于其它在线学习算法, 如FOBOS, RDA等.
FTRL的算法流程如下:

json方式表达有两种, 如下:
"optimizer": "ftrl",
"optimizer": {
"type": "ftrl",
"alpha": 0.1,
"beta": 1.0,
"reg1": 0.01,
"reg2": 0.01
}
注: < BatchSize(SGD) < BatchSize(Momentum) < BatchSize(AdaGrad) ~ BatchSize(AdaDelta) < BatchSize(Adam)
关于学习率, 可以从1.0开始, 以指数的方式(2或0.5为底)增加或减少. 可以用learning curve进行early stop. 但有如下原则: SGD, Momentum可以用相对较大的学习率, AdaGrad, AdaDelta, Adam对学习率较敏感, 一般讲比SGD, Momentum小, 可从SGD, Momentum学习率的一半开始调
关于Decay, 如果epoch较少, decay不宜过大. 一般用标准的decay, AdaGrad, AdaDelta, Adam用WarnRestarts
关于正则化. 目前FTRL, SGD, AdaGrad, AdaDelta支持L1/L2正则, Momentum, Adam只支持L2正则. 推荐从不用正则开始, 然后再加正则.
关于加L1正则的推导, 请参考optimizer
项目地址:https://github.com/Angel-ML/angel
官网:https://angelml.ai/