
FTRL
Training Logistic Regression with FTRL on Spark on Angel
FTRL (Follow-the-regularized-leader) is an optimization algorithm which is widely deployed by online learning. Employing FTRL is easy in Spark-on-Angel and you can train a model with billions, even ten billions, dimensions once you have enough machines.
If you are not familiar with how to programming on Spark-on-Angel, please first refer to Programming Guide for Spark-on-Angel;
FTRL Optimizer
The FTRL algorithm takes into account the advantages of both FOBOS and RDA algorithms. It not only guarantees high precision with FOBOS, but also produces better sparsity with loss of certain precision. The update formula for the feature weight of the algorithm (Reference 1) is:
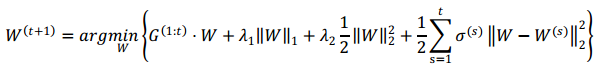
where the represents the gradient of loss function.
The update formula for the feature weight of the algorithm can be decomposed into N independent scalar minimization problems for each dimension of feature weight.
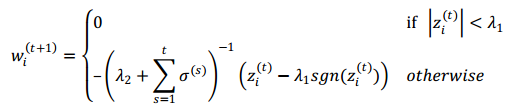
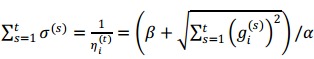
where the val optim = new FTRL(lambda1, lambda2, alpha, beta) // initializing the model optim.init(dim)
There are four hyper-parameters for the FTRL optimizer, which are lambda1, lambda2, alpha and beta. We allocate a FTRL optimizer with these four hyper-parameters. The next step is to initialized a FTRL model. There are three vectors for FTRL, including z, n and w. In the aboving code, we allocate a sparse distributed matrix with 3 rows and dim columns.
set the dimension
In the scenaro of online learning, the index of features can be range from (long.min, long.max), which is usually generated by a hash function. In Spark-on-Angel, you can set the dim=-1 when your feature index range from (long.min, long.max) and rowType is sparse. If the feature index range from [0, n), you can set the dim=n.
Training with Spark
loading data
Using the interface of RDD to load data and parse them to vectors.
val data = sc.textFile(input).repartition(partNum)
.map(s => (DataLoader.parseLongDouble(s, dim), DataLoader.parseLabel(s, false)))
.map {
f =>
f._1.setY(f._2)
f._1
}
training model
val size = data.count()
for (epoch <- 1 to numEpoch) {
val totalLoss = data.mapPartitions {
case iterator =>
// for each partition
val loss = iterator
.sliding(batchSize, batchSize)
.map(f => optim.optimize(f.toArray)).sum
Iterator.single(loss)
}.sum()
println(s"epoch=$epoch loss=${totalLoss / size}")
}
saving model
output = "hdfs://xxx"
optim.weight
optim.saveWeight(output)
optim.save(output + "/back")
The example code can be find at https://github.com/Angel-ML/angel/blob/master/spark-on-angel/examples/src/main/scala/com/tencent/angel/spark/examples/cluster/FTRLExample.scala
References
- H. Brendan McMahan, Gary Holt, D. Sculley, Michael Young. Ad Click Prediction: a View from the Trenches.KDD’13, August 11–14, 2013
项目地址:https://github.com/Angel-ML/angel
官网:https://angelml.ai/