
C#中尾递归的使用、优化及编译器优化

递归运用
一个函数直接或间接的调用自身,这个函数即可叫做递归函数。
递归主要功能是把问题转换成较小规模的子问题,以子问题的解去逐渐逼近最终结果。
递归最重要的是边界条件,这个边界是整个递归的终止条件。
static int RecFact(int x)
{
if (x == 0)
return 1;
return x * RecFact(x - 1);
}
RecFact(10);
上面是个经典阶乘函数的实现。这里分2步:
1.转换,把10的阶乘转化成10*9!,10(9*8!)....每次转换规模就变的更小。
2.逼近,转换到最小规模时0!,求解1。开始逆向合并逐渐逼近到10,得出解。
这里的x==0就是我们的边界条件(即终止条件),也有的依赖外部变量为边界。
如果一个递归函数没有边界,也就无法停止(无限循环至内存溢出),当然这样也没什么意义。
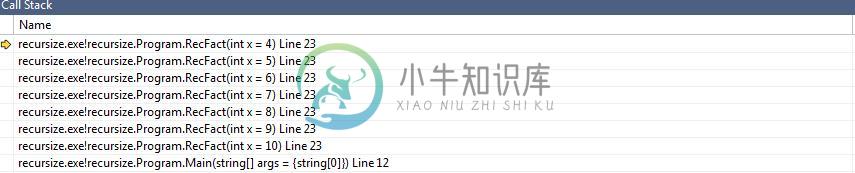
RecFact调用堆栈:
常见使用场景:
1.阶乘/斐波那契数列/汉诺塔
2.遍历硬盘文件
3.InnerExceptions异常扑捉(exception.InnerException==null)
尾递归优化
当边界不明确的时候,递归就很容易出现溢出问题。
在阶乘过程中,堆栈需要保存每次(RecFact)调用的返回地址及当时所有的局部变量状态,期间堆栈空间是无法释放的(即容易出现溢出)。
为了优化堆栈占用问题,从而提出尾递归优化的办法。
static void TailRecursion(int x)
{
Console.WriteLine(x);
if (x == 10)
return;
TailRecursion(x + 1);
}
TailRecursion(0);
使用尾递归堆栈可以不用保存上次的函数返回地址/各种状态值,而方法遗留在堆栈上的数据完全可以释放掉,这是尾递归优化的核心思想。
由于尾递归期间,堆栈是可以释放/再利用的,也就解决递归过深而引起的溢出问题,这也是尾递归的优势所在。
编译器优化
尾递归优化,看起来是蛮美好的,但在net中却有点乱糟糟的感觉。
1.Net在C#语言中是JIT编译成汇编时进行优化的。
2.Net在IL上,有个特殊指令tail去实现尾递归优化的(F#中)。
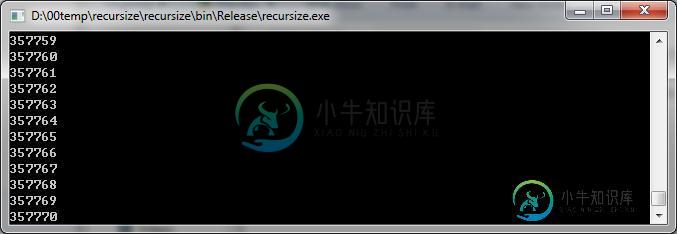
我们执行 TailRecursion(0)(x==1000000) 得出如下结论:
C#/64位/Release是有JIT编译器进行尾递归优化的(非C#编译器优化)。
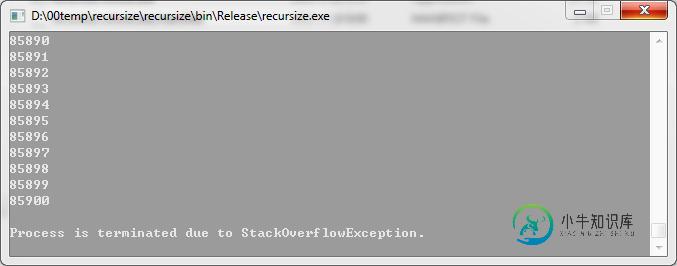
C#/32位或C#/Debug模式中JIT是不进行优化的。
F#在优化尾递归也分2种情况:
1、 简单的尾递归优化成while循环,如下:
let rec TailRecursion(x) = if (x = 1000) then true else TailRecursion(x + 1)
(方便演示C#呈现)编译器优化成:
public static bool TailRecursion(int x)
{
while (x != 0x3e8)
{
x++;
}
return true;
}
2、 复杂的尾递归,F#编译器会生成IL指令Tail进行优化,如下:
let TailRecursion2 a cont = cont (a + 1)
优化成:

如何定义复杂的尾递归呢?通常是后继传递模式(CPS)。
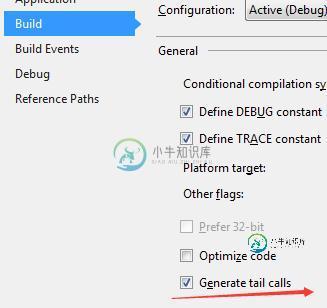
F#中在debug模式下,需要在编译时配置:
总结
在C#语言(过程式/面向对象编程思想)中,优先考虑的是循环,而不是递归/尾递归。 但在函数式编程思想当中,递归/尾递归使用则是主流用法,就像在C#使用循环一样。
-
本文向大家介绍C/C++ 编译器优化介绍,包括了C/C++ 编译器优化介绍的使用技巧和注意事项,需要的朋友参考一下 0. gcc -o gcc -o 的优化仍然是机械的,想当然的。只有做到深入理解计算机系统,加深对编程语言的理解,才能写出最优化的代码。 Linux下gcc 优化级别的介绍 · gcc -o0 ⇒ 不提供任何优化; · gcc -o1 ⇒ 最基本的优化,主要对代码的分支、表达式、
-
问题内容: 我有以下代码失败,并出现以下错误: 超过最大递归深度 我试图重写此代码以允许尾递归优化(TCO)。我相信,如果发生了TCO,则该代码应该会成功。 我是否应该得出结论,Python不执行任何类型的TCO,还是只需要以不同的方式定义它? 问题答案: 你可以通过这样的转换来手动消除递归
-
我有以下代码失败,错误如下: RuntimeError:超出最大递归深度 我试图重写它以允许尾部递归优化(TCO)。我相信,如果发生了TCO,那么这段代码应该是成功的。 我应该得出结论,Python不做任何类型的TCO,还是我只需要以不同的方式定义它?
-
本文向大家介绍Python尾递归优化实现代码及原理详解,包括了Python尾递归优化实现代码及原理详解的使用技巧和注意事项,需要的朋友参考一下 在传统的递归中,典型的模式是,你执行第一个递归调用,然后接着调用下一个递归来计算结果。这种方式中途你是得不到计算结果,知道所有的递归调用都返回。 这样虽然很大程度上简洁了代码编写,但是让人很难它跟高效联系起来。因为随着递归的深入,之前的一些变量需要分配堆栈
-
问题内容: 假设我在C代码中有类似的内容。我知道您可以使用a 代替,以使编译器不对其进行编译,但是出于好奇,我问编译器是否也可以解决此问题。 我认为这对于Java编译器来说更为重要,因为它不支持。 问题答案: 在Java中,if内的代码甚至都不是已编译代码的一部分。它必须编译,但不会写入已编译的字节码。它实际上取决于编译器,但我不知道没有对它进行优化的编译器。规则在JLS中定义: 优化的编译器可能
-
如果关闭了编译器优化(gcc-o0...),那么说'volatile'关键字没有区别是可以的吗? 我制作了一些示例“C”程序,并且仅当打开编译器优化时,才在生成的汇编代码中看到易失性和非易失性之间的区别,即((gcc-o1....)。