
高吞吐、线程安全的LRU缓存详解

本文研究的主要是高吞吐、线程安全的LRU缓存的相关内容,具体介绍如下。
几年以前,我实现了一个LRU缓存用来为关键字来查找它的id。数据结构非常有意思,因为要求的吞吐很大足以消除大量使用locks和synchronized关键字带来的性能问题,应用是用java实现的。
我想到一连串的原子引用分配会在ConcurrentHashMap中保持LRU保持LRU顺序,开始的时候我把value包装到entry中去,entry在双链表的LRU链中有一个节点,链的尾部保持的是最近使用的entry,头节点中存放的是当缓存达到一定的大小的时候可能会清空的entry。每一个节点都指向用来查找的entry。

当你通过key查找值的时候,缓存首先要查找map看看是否有这个value存在,如果不存在的话,它将依赖于加载器将value从数据源中以read-through的方式读出来并且以“如果缺失则添加”的方式添加的map中去。确保高吞吐的挑战是有效的维护LRU链。这个并发的哈希map是分段的而且在线程的水平在一定水平(当你构建map的时候你可以指定并发的水平)情况下的时候不会经历太多的线程竞争。但是LRU链不能以同样的方式被划分吗,为了解决这个问题,我引入了辅助的队列用来清除操作。
在cache中有六个基本的方法。对于缓存命中,查找包含两个基本操作:get和offer,对于换粗丢失包含四个基本的方法get、load、put和offer。在put方法上,我们也许需要追踪清空操作,在缓存命中的情况下get,我们在LRU链上被动的做一些清空叫做净化操作。
get : lookup entry in the map by key
load : load value from a data source
put : create entry and map it to key
offer: append a node at the tail of the LRU list that refers to a recently accessed entry
evict: remove nodes at the head of the list and associated entries from the map (after the cache reaches a certain size)
purge: delete unused nodes in the LRU list -- we refer to these nodes as holes, and the cleanup queue keeps track of these
清空操作和净化操作都是大批量的处理数据,我们来看一下每个操作的细节
get操作是按如下方式工作的:
get(K) -> V lookup entry by key k if cache hit, we have an entry e offer entry e try purge some holes else load value v for key k create entry e <- (k,v) try put entry e end return value e.v
如果key存在,我们在LRU链的尾部提供一个新的节点来表明,这是一个最近使用的值。get和offer的执行并不是原子操作(这里没有lock),所以我们不能说这个offered 节点指向最近使用的实体,但是肯定是当我们并发执行时获得的最近使用的实体。我们没有强制get和offer对在线程间执行的顺序,因为这可能会限制吞吐量。在offer一个节点之后,我们尝试着做一些清除和返回value的操作。下边我们详细看一下这offer和purge操作。
如果缓存丢失发生了,我们将调用加载器为这个key加载value,创建一个新的实体并把它放入到map中去,put操作如下:
put(E) -> E
existing entry ex <- map.putIfAbsent(e.k, e)
if absent
offer entry e;
if size reaches evict-threshold
evict some entries
end
return entry e
else, we have an existing entry ex
return entry ex
end
正如你所见的一样,有两个或这两个以上的线程把一个实体放入map的时候可能存在竞争,但是只允许一个成功并且会调用offer。在LRU链的尾部提供一个节点之后,我们需要检查是否缓存已经达到了它的阙值的大小,阙值是我们用来出发批量清空操作的标识。在这个特定的应用的场景下,阙值的设置要比容量的大小要小。清空操作小批量的发生而不是每一个实体加进来的时候都会发生,多线程或许会参与到清空操作中去,直到缓存的容量达到它的容量。上锁很容易但是线程却能是安全的。清空需要移除LRU链的头节点,这需要依赖细心的原子操作来避免在map中多线程的移除操作。
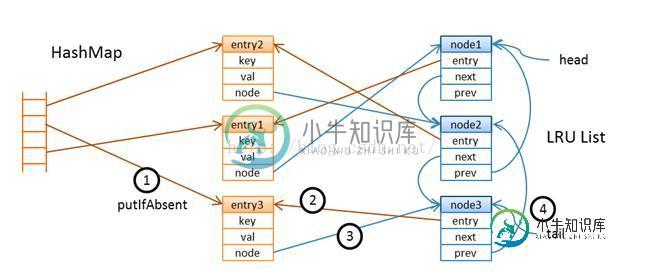
这个offer操作非常有意思,它总是尝试着创建一个节点但是并不试图在LRU中立即移除和删除那些不再使用的节点。
offer(E)
if tail node doesn't refer to entry e
assign current node c <- e.n
create a new node n(e), new node refers to entry e
if atomic compare-and-set node e.n, expect c, assign n
add node n to tail of LRU list
if node c not null
set entry c.e to null, c now has a hole
add node c to cleanup queue
end
end
end
首先它会检查,链中尾部的节点没有指向已经访问的实体,这并没有什么不同除非所有的线程频繁的访问同样的键值对,它将会链部的尾的实体创建一个新的节点当这个实体不同的时候,在提供新的节点之前,它尝试为实体进一个比较和设置的操作,这将阻止多线程做同样的事情。
成功的分配节点的线程在LRU链的尾部提供了一个新的节点,这个操作和ConcurrentLinkedQueue中的find一样,依赖的算法在下边的文章中有描述 Simple, Fast, and Practical Non-Blocking and Blocking Concurrent Queue Algorithms。线程然后会检查实体之前是否和其他的节点有相关连,如果是这样的话,老的节点不会立即删除,但是会被标记为一个hole(它的实体的引用会被设置为空)

总结
以上就是本文关于高吞吐、线程安全的LRU缓存详解的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站其他相关专题,如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!
-
本人第一次面试,好多没有答上来,感觉应该过不了,面试问题供大家参考 实习岗位是:安全工程师 面试问题如下: 1.做一下自我介绍: 2.安全技术,主要掌握哪一些技能 一些渗透工具的使用 比如burpsuite、sqlmap、nmap、nessus、awvs等工具,top10漏洞 3.讲一下你最熟悉的两种漏 sql注入和xss,SQL注入的原理和sq
-
本文向大家介绍详解Java实现LRU缓存,包括了详解Java实现LRU缓存的使用技巧和注意事项,需要的朋友参考一下 LRU是Least Recently Used 的缩写,翻译过来就是“最近最少使用”,LRU缓存就是使用这种原理实现,简单的说就是缓存一定量的数据,当超过设定的阈值时就把一些过期的数据删除掉,比如我们缓存10000条数据,当数据小于10000时可以随意添加,当超过10000时就需要把
-
本文向大家介绍Java实现LRU缓存的实例详解,包括了Java实现LRU缓存的实例详解的使用技巧和注意事项,需要的朋友参考一下 Java实现LRU缓存的实例详解 1.Cache Cache对于代码系统的加速与优化具有极大的作用,对于码农来说是一个很熟悉的概念。可以说,你在内存中new 了一个一段空间(比方说数组,list)存放一些冗余的结果数据,并利用这些数据完成了以空间换时间的优化目的,你就已经
-
我正在对ElasticSearch进行基准测试,以实现非常高的索引吞吐量。 我目前的目标是能够在几个小时内索引30亿(3,000,000,000)文档。为此,我目前有3台windows服务器机器,每台16GB内存和8个处理器。插入的文档有一个非常简单的映射,只包含少数数字非分析字段(被禁用)。 使用这个相对适中的钻机,我能够达到每秒大约120,000个索引请求(使用大桌子监控),我相信吞吐量可以进
-
我想通过从CSV文件向服务器发送100个请求来测试10个线程。我想每个线程按顺序发射100个请求,同时允许并行请求。我有我的主要采样器和子采样器的子组件和另一个采样器,我想比较我的结果。这种配置通常会产生7个采样器。问题是,当我尝试绘制吞吐量与线程之间的关系图时,在1个用户中,结果在y轴上显示了100多个事务/秒的值。同样的事情发生在“显示结果表”侦听器(即,对于1个用户,它显示700个样本)如何
-
我需要从很多客户端通过网络套接字连接到java服务器来提取数据。 有很多web套接字实现,我选择了vert。x、 我做了一个简单的演示,在那里我听json的文本帧,用jackson解析它们,然后返回响应。Json解析器对吞吐量没有显著影响。 我的总速度是每秒2.5公里,有2到10个客户。 然后我尝试使用缓冲,客户端不会等待每个响应,而是在服务器确认后发送一批消息(30k-90k),速度提高到每秒8