
LR公式

参考回答:
逻辑回归本质上是线性回归,只是在特征到结果的映射中加入了一层逻辑函数g(z),即先把特征线性求和,然后使用函数g(z)作为假设函数来预测。g(z)可以将连续值映射到0 和1。g(z)为sigmoid function.
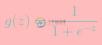

sigmoid function 的导数如下:
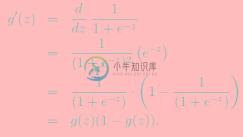
逻辑回归用来分类0/1 问题,也就是预测结果属于0 或者1 的二值分类问题。这里假设了二值满足伯努利分布,也就是

其也可以写成如下的形式:

对于训练数据集,特征数据x={x1, x2, … , xm}和对应的分类标签y={y1, y2, … , ym},假设m个样本是相互独立的,那么,极大似然函数为:
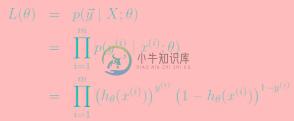
log似然为:

如何使其最大呢?与线性回归类似,我们使用梯度上升的方法(求最小使用梯度下降),那么
。
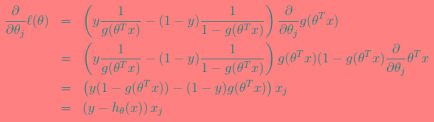
如果只用一个训练样例(x,y),采用随机梯度上升规则,那么随机梯度上升更新规则为:

-
本文向大家介绍LR推导相关面试题,主要包含被问及LR推导时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 逻辑回归本质上是线性回归,只是在特征到结果的映射中加入了一层逻辑函数g(z),即先把特征线性求和,然后使用函数g(z)作为假设函数来预测。g(z)可以将连续值映射到0 和1。g(z)为sigmoid function. 则 逻辑回归用来分类0/1 问题,也就是预测结果属于0 或者1 的二
-
本文向大家介绍关于LR?相关面试题,主要包含被问及关于LR?时的应答技巧和注意事项,需要的朋友参考一下 把LR从头到脚都给讲一遍。建模,现场数学推导,每种解法的原理,正则化,LR和maxent模型啥关系,LR为啥比线性回归好。有不少会背答案的人,问逻辑细节就糊涂了。原理都会? 那就问工程,并行化怎么做,有几种并行化方式,读过哪些开源的实现。还会,那就准备收了吧,顺便逼问LR模型发展历史。
-
[Spark on Angel] LR 数据、特征和数值优化算法是机器学习的核心,Spark on Angel的LR算法,借助Spark本身的MLLib,支持更加完善的优化算法,包括梯度下降、牛顿法,以及二者的各种变种。 1. 算法介绍 Spark MLLib中Logistic Regression算法,适合于低维度稠密型的特征,并可以用不同的优化算法求解,如SGD、L-BFGS、OWL-QN……
-
LogisticRegression 逻辑回归模型(logistic regression model)是一种分类模型。它是最常见和常用的一种分类方法,在传统的广告推荐中被大量使用,朴实但有效。 1. 算法介绍 Logistic Regression 逻辑回归模型(logistic regression model)是一种分类模型。样本x属于类别y的概率P(y|x)服从logistic分布: 综合
-
本文向大家介绍LR和SVM 区别相关面试题,主要包含被问及LR和SVM 区别时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 1)LR是参数模型,SVM是非参数模型。2)从目标函数来看,区别在于逻辑回归采用的是logistical loss,SVM采用的是hinge loss.这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。3)SVM的处理方法是只
-
本文向大家介绍LR的损失函数相关面试题,主要包含被问及LR的损失函数时的应答技巧和注意事项,需要的朋友参考一下 参考回答: M为样本个数,为模型对样本i的预测结果,为样本i的真实标签。