
【计算机网络】从输入一个 URL 到页面加载完成的过程
更多面试题总结请看:【面试题】技术面试题汇总
前言
从输入一个 URL、按下回车到显示页面,中间发生了什么?这道题既有广度,又有深度,很能考验一个人的知识体系。
无论是前端面试还是后端面试,我都被问过这个问题,然而每次都没能答得很好。究其原因,在于我脑海中有很多零零星星的知识点,什么 DNS、三次握手四次挥手、HTTPS… 却没有一个系统的结构,导致我经常是想到哪里说哪里。因此,即使这个题目已经被写烂了,我还是想写这篇文章,目的是系统地梳理一下自己的知识体系。
网络上有很多资源,非常详细具体地解释了从底层到高层、从硬件到软件的原理。而本文更侧重于在同一个层次讨论浏览器、操作系统、服务器是如何交互的。
整体流程
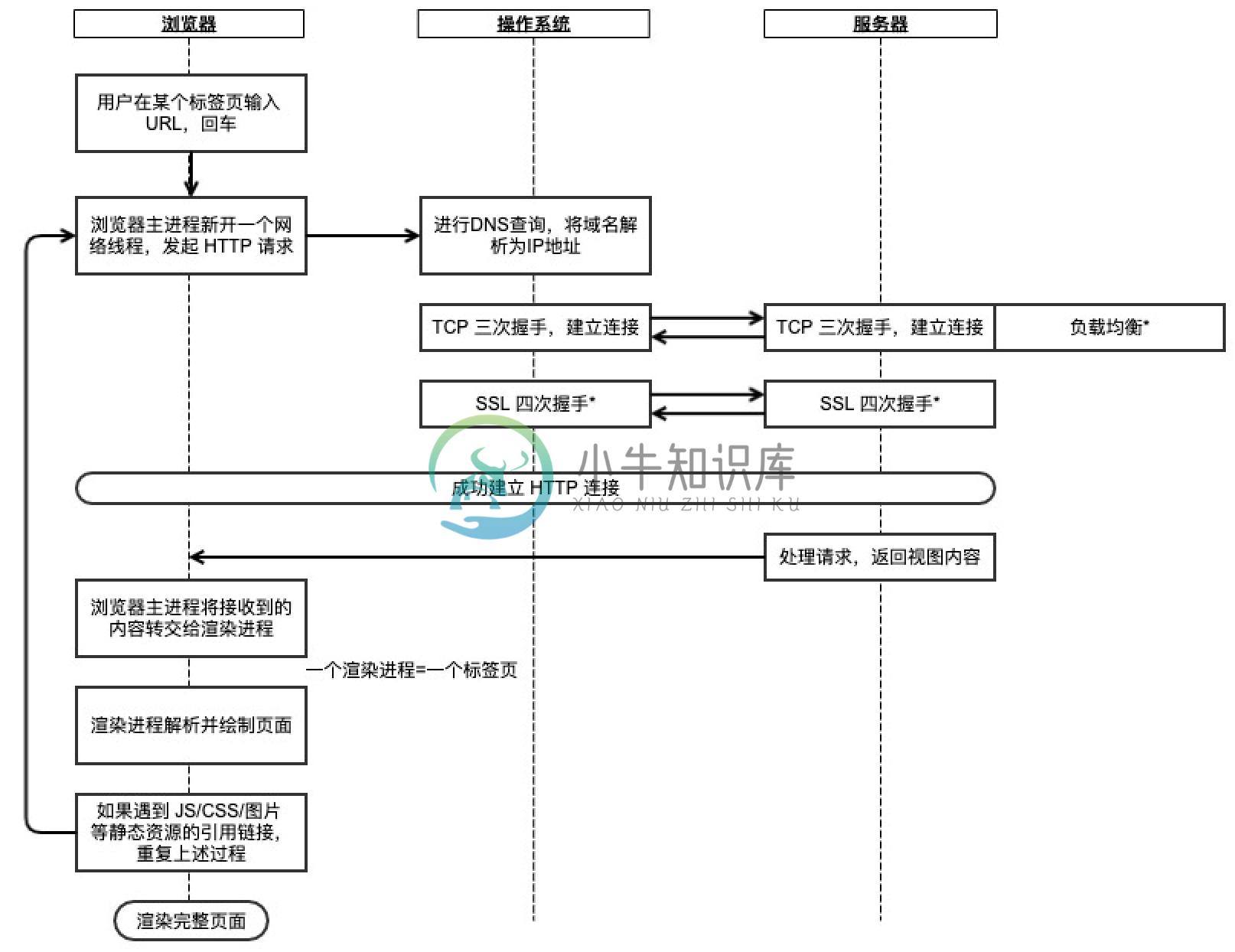
- 用户在某个标签页输入 URL 并回车后,浏览器主进程会新开一个网络线程,发起 HTTP 请求
- 浏览器会进行 DNS 查询,将域名解析为 IP 地址
- 浏览器获得 IP 地址后,向服务器请求建立 TCP 连接
- 浏览器向服务器发起 HTTP 请求
- 服务器处理请求,返回 HTTP 响应
- 浏览器的渲染进程解析并绘制页面
- 如果遇到 JS/CSS/图片 等静态资源的引用链接,重复上述过程,向服务器请求这些资源
深入底层原理之浏览器
浏览器是多进程的。
浏览器只有一个主进程,又称 Browser 进程,负责创建/管理其他进程、显示浏览器主窗口、下载网络资源等。
每打开一个标签页,就创建了一个独立的浏览器渲染进程。浏览器渲染进程又称为浏览器内核、Renderer 进程,其内部是多线程的,负责页面渲染、脚本执行等。
浏览器的每一个网络请求,都需要主进程开辟一个单独的网络线程去处理。输入 URL 相当于一个网络请求,解析 HTML 时遇到 JS/CSS/图片等静态资源的引用链接,也需要分别请求。
浏览器的渲染流程:
- 解析 HTML 文件,构建 DOM 树,同时下载 CSS 等静态资源
- CSS 文件下载完成后,解析 CSS 文件,形成 CSSOM 树
- DOM 与 CSSOM 合并得到渲染树 Render Tree
- 计算渲染树中各个元素的尺寸、位置,这个过程称为回流 Reflow
- 浏览器将各个图层的信息发送给 GPU,GPU 绘制页面
进一步阅读:浏览器运行机制
- 浏览器的多进程模型
- 浏览器内核的多线程模型
- GUI 线程、JS 线程的阻塞关系
- JS 引擎的解析与执行过程
- JS 单线程模型、事件循环 Event-Loop
- …
深入底层原理之服务器
负载均衡:大型的项目,往往是由多台服务器组成一个集群,以此应对庞大的并发访问量。这种情况下,用户的请求都会指向调度服务器,由调度服务器将请求分发给集群中的某台服务器 A,然后调度服务器会将 A 服务器的 HTTP 响应发送给用户。 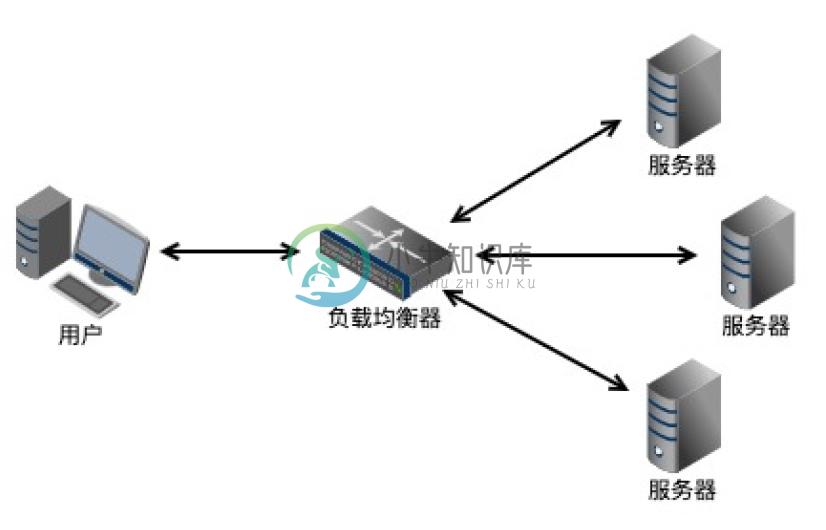
此外,后端还会经过安全认证、参数校验、中间件、执行业务代码、访问数据库等一系列操作,才能向用户返回结果。
进一步阅读:负载均衡的实现
深入底层原理之网络协议
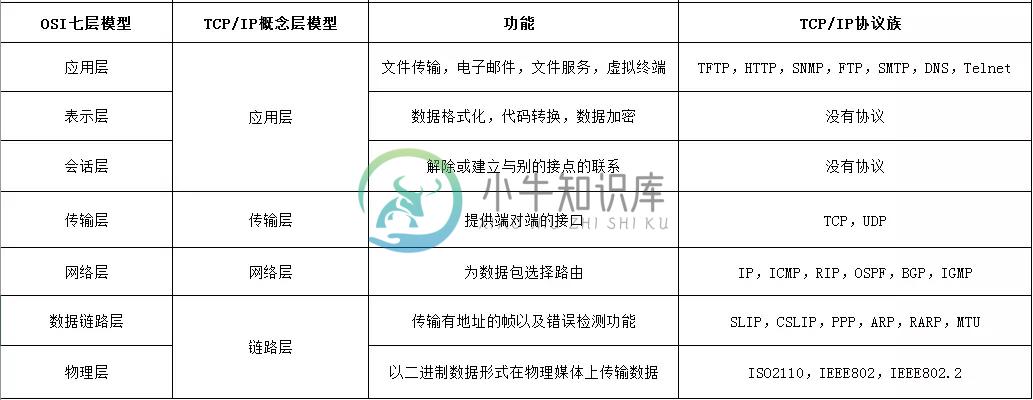
网络协议栈
DNS 查询过程
DNS 是应用层的协议,作用是将域名转化为 IP,以供传输层建立 TCP 连接。
整体流程:浏览器搜索自身的 DNS 缓存、搜索操作系统的 DNS 缓存、读取本地的 Host 文件和向本地 DNS 服务器进行查询等。
进一步阅读:DNS 的递归查询与迭代查询
TCP 三次握手、四次挥手
TCP 是传输层协议,HTTP 协议通过 TCP 协议发送数据。之所以选择 TCP,是因为 HTTP 对数据的准确性要求高,TCP 能够提供可靠的交付。
进一步阅读:
- TCP 三次握手、四次挥手详解
- 三次握手过程,序列号、确认号
- 为什么需要三次握手?为什么不是两次或四次?
- 四次挥手过程,序列号、确认号
- 序列号、确认号的含义到底是什么?
- 如果握手、挥手过程中的包丢失了会怎样?
- …
- TCP 的流量控制与拥塞控制
- TCP 的粘包
SSL 四次握手
SSL 位于传输层和应用层之间,TCP 和 HTTP 之间。SSL 协议的目的是,为通信双方提供一种在不安全的网络环境中,安全地协商一个密钥的方法。
SSL 实现的核心是非对称式密码学。非对称密码包含两个部分:公钥和私钥,一个用作加密,另一个则用作解密。使用其中一个密钥把明文加密后所得的密文,只能用相对应的另一个密钥才能解密得到原本的明文;甚至连最初用来加密的密钥也不能用作解密。
HTTPS 本质上就是 HTTPS + SSL。通过 SSL 四次握手过程,客户端和服务端会商定一个共同的随机密钥,用来对称加密。握手结束后,双方都会使用这个约定的随机密钥来加密、解密会话内容,使用的完全是普通的 HTTP 协议。
进一步阅读:HTTPS 详解
- SSL 四次握手过程
- 数字签名、摘要算法是什么?
- CA、证书是什么?
- 如何验证证书是否合法?
- 中间人攻击及如何预防
- …
HTTP 的长连接与短连接
HTTP/1.0 默认使用的是短连接。也就是说,浏览器每请求一个静态资源,就建立一次连接,任务结束就中断连接。
HTTP/1.1 默认使用的是长连接。长连接是指在一个网页打开期间,所有网络请求都使用同一条已经建立的连接。当没有数据发送时,双方需要发检测包以维持此连接。长连接不会永久保持连接,而是有一个保持时间。实现长连接要客户端和服务端都支持长连接。
长连接的优点:TCP 三次握手时会有 1.5 RTT 的延迟,以及建立连接后慢启动(slow-start)特性,当请求频繁时,建立和关闭 TCP 连接会浪费时间和带宽,而重用一条已有的连接性能更好。
长连接的缺点:长连接会占用服务器的资源。
进一步阅读:HTTP 长连接和短连接
HTTP 2.0
HTTP 2.0 的三大特性是头部压缩、服务端推送、多路复用。
HTTP 1.1 允许通过同一个连接发起多个请求。但是由于 HTTP 1.X 使用文本格式传输数据,服务端必须按照客户端请求到来的顺序,串行返回数据。此外,HTTP 1.1 中浏览器会限制同时发起的最大连接数,超过该数量的连接会被阻塞。
HTTP 2 引入了多路复用,允许通过同一个连接发起多个请求,并且可以并行传输数据。HTTP 2 使用二进制数据帧作为传输的最小单位,每个帧标识了自己属于哪个流,每个流对应一个请求。服务端可以并行地传输数据,而接收端可以根据帧中的顺序标识,自行合并数据。
在 HTTP 1.1 中,由于浏览器限制每个域名下最多同时有 6 个请求,其余请求会被阻塞,因此我们通常使用多个域名(比如 CDN)来提高浏览器的下载速度。HTTP 2 就不再需要这样优化了。
同理,在 HTTP 1.1 中,我们会将多个 JS 文件、CSS 文件等打包成一个文件,将多个小图片合并为雪碧图,目的是减少 HTTP 请求数。HTTP 2 也不需要这样优化了。
进一步阅读:
HTTP 缓存
浏览器可以将已经请求过的资源(如图片、JS 文件)缓存下来,下次再次请求相同的资源时,直接从缓存读取。
浏览器采用的缓存策略有两种:强制缓存、协商缓存。浏览器根据第一次请求资源时返回的 HTTP 响应头来选择缓存策略。
强制缓存:为资源设置一个过期时间,只要资源没有过期,就读取浏览器的缓存。强制缓存不需要向服务器发起请求,浏览器直接返回 200(from cache)。
协商缓存:浏览器携带缓存资源的元信息,向服务器发起请求,由服务器决定是否使用缓存。如果协商缓存生效,服务器返回 304 和 Not Modified;如果协商缓存失效,服务器返回 200 和请求结果。
协商缓存的原理是:服务端根据资源的元信息,判断浏览器缓存的资源在服务器上是否有改动。元信息有两种,一种是资源的上次修改时间,另一种是资源 Hash 值。前者实现简单,但是精确度低,文件修改时间只能以秒记;后者精确度高,但是性能低,需要计算哈希值。
优先级:
- 强制缓存 > 协商缓存
- 在协商缓存中,Hash 值 > 上次修改时间
进一步阅读:浏览器的缓存机制
网络层、数据链路层
扩展阅读
- 撒网要见鱼的文章 - segmentfault - 前端的视角
- skyline75489 的文章 - github - 前端的视角
- nwind 的文章 - 硬件的视角
技术面试题汇总
TODO:“进一步阅读”是某个专题的更详细具体的笔记。这些链接还无法点击,我在后期会整理补充。