《花旗银行》专题
-
火花:IllegalArgumentException:“不受支持的类文件主版本55”
运行时遇到错误,我尝试了Pyspark error-Unsupported class file major version 55和Pyspark.topandas():'Unsupported class file major version 55'中提到的解决方案,但没有成功。 完整错误日志:
-
在Scala火花数据帧DSL API中使用Scal-sql UDF
如何在火花scala数据帧(非文本)api中访问geomesas UDF?即如何转换 如何使sql UDF在scala数据帧DSL中的文本spark sql API中可用?即如何启用而不是此表达式 类似于 如何注册Geomesa UDF,使其不仅适用于sql文本模式<代码>SQLTypes。init(spark.sqlContext)fromhttps://github.com/locationt
-
如何使用orderby()与降序在火花窗口函数?
我需要一个窗口函数,该函数按一些键(=列名)进行分区,按另一个列名排序,并返回排名前x的行。 这适用于升序: 但当我试图在第4行中将其更改为或时,我得到了一个语法错误。这里的正确语法是什么?
-
火花SQL:选择与算术列值和类型转换?
我将Spark SQL用于数据帧。有没有一种方法可以像在SQL中一样,使用一些算术来执行select语句? 例如,我有以下表格: 现在,我想用SELECT语句创建一个新列,并对现有列执行一些算术运算。例如,我想计算比率。我需要先把价值(或年数)转换成双倍。我试过这句话,但无法解析: 我在“如何在Spark SQL的DataFrame中更改列类型?”中看到了类似的问题,但这不是我想要的。
-
火花SQL:如何使用JAVA从DataFrame操作调用UDF
我想知道如何使用JAVA从SparkSQL中的领域特定语言(DSL)函数调用UDF函数。 我有UDF函数(仅举例): 我已经注册到sqlContext了 当我运行下面的查询时,我的UDF被调用,我得到一个结果。 我将使用Spark SQL中特定于域的语言的函数转换此查询,但我不确定如何进行转换。 我发现存在调用 UDF() 函数,其中其参数之一是函数 fnctn 而不是 UDF2。如何使用 UDF
-
如何使用 JAVA 在火花数据帧上调用 UDF?
类似的问题,但没有足够的观点来评论。 根据最新的Spark文档,< code>udf有两种不同的用法,一种用于SQL,另一种用于DataFrame。我找到了许多关于如何在sql中使用< code>udf的例子,但是还没有找到任何关于如何在数据帧中直接使用< code>udf的例子。 o.p.针对上述问题提供的解决方案使用,这是,将根据Spark Java API文档在Spark 2.0中删除。在那
-
错误没有找到值火花导入spark.implicits._导入spark.sql
我使用hadoop 2.7.2,hbase 1.4.9,火花2.2.0,scala 2.11.8和java 1.8的hadoop集群是由一个主和两个从。 当我在启动集群后运行spark shell时,它工作正常。我正试图通过以下教程使用scala连接到hbase:[https://www.youtube.com/watch?v=gGwB0kCcdu0][1] . 但当我试图像他那样通过添加那些类似
-
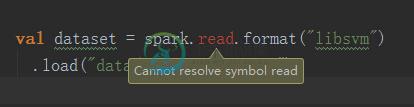 value read不是组织的成员。阿帕奇。火花SparkContext
value read不是组织的成员。阿帕奇。火花SparkContextscala的版本是2.11.8;jdk为1.8;spark是2.0.2 我试图在spark apache的官方网站上运行一个LDA模型的示例,我从以下句子中得到了错误消息: 错误按摩是: 错误:(49,25)读取的值不是组织的成员。阿帕奇。火花SparkContext val dataset=spark。阅读格式(“libsvm”)^ 我不知道怎么解决。
-
如何限制雪花表中重复记录的插入
-
雪花子字符串Concat问题:无法识别数值“|”
有一个财政季度列,我想在同一行中添加一个显示上一个季度的列。我已经成功地用下面的逻辑在画面中做到了这一点。 当我尝试在雪花中这样做时,虽然我不断得到这个“数值”是不被识别的错误。有什么想法如何修复?下面是我尝试的。
-
用数组和对象从多个值插入雪花表
我试图通过SQL语句将多行数组和结构插入到Snowflake中。要在列中插入值数组,我使用函数,要插入结构/字典/对象,我使用函数。 这将导致异常: SQL编译错误:VALUES子句中的表达式[Array_Construct(0,1,2)]无效 使用以下语法插入一行可以工作:
-
 同花顺人工智能产品经理一面面经
同花顺人工智能产品经理一面面经提前进去面试会议室,面试官也提前进,闲聊了差不多10min,正式面试50min 1.疫情、杭州、老家、朋友家人亲戚、有对象吗、年龄、手上有offer吗、你想去那个offer吗 2.自我介绍 3.实习项目的背景、目标、怎么做的、结果如何 4.实习期间获得最大收获 5.低代码你了解的怎么样 6.对网易虚拟人的了解 7.伏羲的组织结构 8.基于网易实习谈谈对AI虚拟人未来的看法 9.对虚拟人技术背景的认
-
 Python:让你完成一次绝美樱花视觉体验
Python:让你完成一次绝美樱花视觉体验看到这你是不是已经开始心动了~但是现在又不是樱花季等到三月份再去估计也有点困难现实生活中大概不大可能看到啦!!但是小编想到了一法子!准备用Python带大家云观赏一场盛世樱花!!
-
2.10 创建自定义图形:绘制扑克牌花色
如果皇家同花顺会让你兴奋不已,本节就是为你而写。本节,我们将创建一个组函数,用来绘制一套扑克牌中的黑桃、红桃、梅花、方块。 图2-11 绘制扑克牌花色 绘制步骤 按照以下步骤,绘制一套扑克牌中的黑桃、红桃、梅花、方块: 1. 定义drawSpade()函数,该函数通过绘制四条贝塞尔曲线、两条二次曲线、一条直线,来绘制黑桃: function drawSpade(context, x, y, wi
-
js实现精美的银灰色竖排折叠菜单
本文向大家介绍js实现精美的银灰色竖排折叠菜单,包括了js实现精美的银灰色竖排折叠菜单的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了js实现精美的银灰色竖排折叠菜单。分享给大家供大家参考。具体实现方法如下: 希望本文所述对大家的javascript程序设计有所帮助。