
value read不是组织的成员。阿帕奇。火花SparkContext

scala的版本是2.11.8;jdk为1.8;spark是2.0.2
我试图在spark apache的官方网站上运行一个LDA模型的示例,我从以下句子中得到了错误消息:
val dataset = spark.read.format("libsvm")
.load("data/libsvm_data.txt")
错误按摩是:
错误:(49,25)读取的值不是组织的成员。阿帕奇。火花SparkContext val dataset=spark。阅读格式(“libsvm”)^
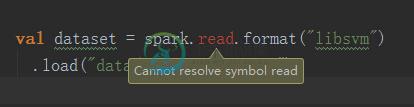
我不知道怎么解决。
共有3个答案

下面是sql上下文函数的完整语法
val df = sqlContext
.read()
.format("com.databricks.spark.csv")
.option("inferScheme","true")
.option("header","true")
.load("path to/data.csv");
如果你正在读/写csv文件

添加以下行:
import org.apache.spark.sql.SparkSession
val session = SparkSession.builder().appName("app_name").master("local").getOrCreate()
val training = session.read.format("format_name").load("path_to_file")

看起来您试图在SparkContext上调用read,而不是SQLContext或SparkSession:
// New 2.0.+ API: create SparkSession and use it for all purposes:
val session = SparkSession.builder().appName("test").master("local").getOrCreate()
session.read.load("/file") // OK
// Old <= 1.6.* API: create SparkContext, then create a SQLContext for DataFrame API usage:
val sc = new SparkContext("local", "test") // used for RDD operations only
val sqlContext = new SQLContext(sc) // used for DataFrame / DataSet APIs
sqlContext.read.load("/file") // OK
sc.read.load("/file") // NOT OK
-
我附加了错误的代码片段“值toDF不是org.apache.spark.rdd.RDD的成员”。我正在使用scala 2.11.8和火花2.0.0。你能帮我解决API toDF()的这个问题吗? }
-
将现有应用程序从Spark 1.6移动到Spark 2.2*(最终)会导致错误“org.apache.spark.SparkExctive:任务不可序列化”。我过于简化了我的代码,以演示同样的错误。代码查询拼花文件以返回以下数据类型:“org.apache.spark.sql.数据集[org.apache.spark.sql.行]”我应用一个函数来提取字符串和整数,返回字符串。一个固有的问题与Sp
-
我在尝试将spark数据帧的一列从十六进制字符串转换为双精度字符串时遇到了一个问题。我有以下代码: 我无法共享txs数据帧的内容,但以下是元数据: 但当我运行这个程序时,我得到了一个错误: 错误:类型不匹配;找到:MsgRow需要:org.apache.spark.sql.行MsgRow(row.getLong(0),row.getString(1),row.getString(2),hex2in
-
目前我正在研究Apache spark和Apache ignite框架。 这篇文章介绍了它们之间的一些原则差异,但我意识到我仍然不理解它们的目的。 我的意思是,哪一个问题更容易产生火花而不是点燃,反之亦然?
-
我处理了像这样存储的双精度列表: 我想计算这个列表的平均值。根据文档,: MLlib的所有方法都使用Java友好类型,因此您可以像在Scala中一样导入和调用它们。唯一的警告是,这些方法采用Scala RDD对象,而Spark Java API使用单独的JavaRDD类。您可以通过对JavaRDD对象调用.RDD()将JavaRDD转换为Scala RDD。 在同一页面上,我看到以下代码: 根据我