《花旗银行》专题
-
 9.17 同花顺一面 40min & 联影电话面和视频面
9.17 同花顺一面 40min & 联影电话面和视频面同花顺 C++ 更新:过了三个半小时,发来一面通过(大无语事件...) 9.19更新: 约二面,但是我拒了,虽然没有offer也不想受这种气!拒掉拒掉! 面的稀巴烂,被摁在地上摩擦... 自我介绍完了之后,第一个问题:你这个抄的webserver和其他的有什么不一样... udp和ip的区别 静态库和动态库 动态库和可执行程序 10000行代码,如果输入和输出不一致怎么查(我回答打日志,调试。 感
-
 【同花顺】2023春招前端【一面+二面+HR面】面经
【同花顺】2023春招前端【一面+二面+HR面】面经一面 自我介绍, 讲实习项目 你在实习中的这些项目都是你自己做的吗? 有人带你吗? 你在实习中做的事情基本都是业界比较成熟的, 你在做的时候有参考哪些已有的成果? 你在实习中做的最有挑战的事情是什么? 你是怎么解决的? 你在实习过程中的最大收获 有没有了解 Vue? Vue 中父子组件传值 有没有了解手机端前端开发 , , 的应用场景 写一个 js 正则表达式, 实现对邮箱字符串的校验 --> 反
-
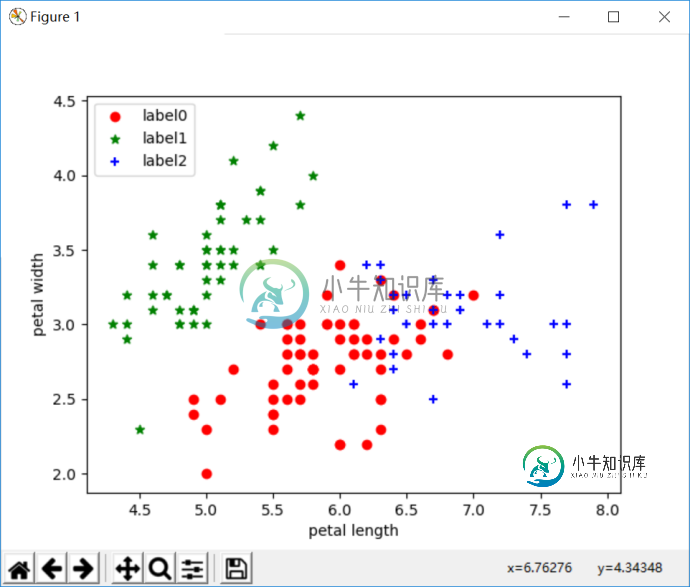 python实现鸢尾花三种聚类算法(K-means,AGNES,DBScan)
python实现鸢尾花三种聚类算法(K-means,AGNES,DBScan)本文向大家介绍python实现鸢尾花三种聚类算法(K-means,AGNES,DBScan),包括了python实现鸢尾花三种聚类算法(K-means,AGNES,DBScan)的使用技巧和注意事项,需要的朋友参考一下 一.分散性聚类(kmeans) 算法流程: 1.选择聚类的个数k. 2.任意产生k个聚类,然后确定聚类中心,或者直接生成k个中心。 3.对每个点确定其聚类中心点。 4.再计算其聚类
-
 Android自定义View新年烟花、祝福语横幅动画
Android自定义View新年烟花、祝福语横幅动画本文向大家介绍Android自定义View新年烟花、祝福语横幅动画,包括了Android自定义View新年烟花、祝福语横幅动画的使用技巧和注意事项,需要的朋友参考一下 新年了,项目中要作个动画,整体要求实现彩带乱飞,烟花冲天而起,烟花缩放,小鸡换图,小鸡飘移,横幅裁剪、展开等动画效果,全局大量使用了属性动画来实现。 如下效果图: 我在实现过程中,横幅的裁剪计算,捣腾了比较久的时间,初版采用属性动画
-
在角量角器茉莉花测试中查看console.log输出
问题内容: 如何在angularjs量角器茉莉花测试中查看console.log输出?截至目前,浏览器自身关闭速度过快。 更多信息-我正在使用angularjs教程,步骤8。我试图将e2e测试更改为量角器。我正在使用的量角器配置文件基于%appdata%\ npm \ node_modules \ protractor \ referenceConf.js。在配置文件引用的js规范文件中,我有co
-
 Java求10到100000之间的水仙花数算法示例
Java求10到100000之间的水仙花数算法示例本文向大家介绍Java求10到100000之间的水仙花数算法示例,包括了Java求10到100000之间的水仙花数算法示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Java求10到100000之间的水仙花数算法。分享给大家供大家参考,具体如下: 水仙花数: 概念:水仙花数是指一个 n 位数 ( n≥3 ),它的每个位上的数字的 n 次幂之和等于它本身。(例如:1^3 + 5^3+ 3
-
在iPad上显示视图控制器仅允许。爆米花
我有一个iPhone应用程序,我正试图使其通用化。我有以下代码: 只是传递到类中的视图控制器。 每次执行此代码时,都会发生以下错误: 您的应用程序提供了一个UIDocumentMenuViewController()。在当前的trait环境中,具有此样式的UIDocumentMenuViewController的modalPresentationStyle是UIModalPresentationP
-
如何在茉莉花单元测试中解决$ q.all承诺?
问题内容: 我的控制器具有如下代码: 在我的单元测试中,我正在做这样的事情: 现在在测试中,我正在检查是否调用了服务,并且data1,data2是否未定义。 我的问题是,这是工作的罚款,直到我取代与q.all控制器和测试我个人的服务电话与。使用q.all和(也尝试使用),两个测试均失败,并显示以下错误: 达到10个$ digest()迭代。流产! 如果我删除了,那么承诺永远不会得到解决,而测试失败
-
 JavaScript+html5 canvas制作的百花齐放效果完整实例
JavaScript+html5 canvas制作的百花齐放效果完整实例本文向大家介绍JavaScript+html5 canvas制作的百花齐放效果完整实例,包括了JavaScript+html5 canvas制作的百花齐放效果完整实例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JavaScript+html5 canvas制作的百花齐放效果。分享给大家供大家参考,具体如下: 运行效果截图如下: 具体代码如下: 更多关于js特效相关内容感兴趣的读者可查看
-
配置火花应用参数的最佳开端是什么?
我很困惑我应该使用哪种方法来配置火花应用程序参数。 让我们考虑以下集群配置:10个节点、每个节点16个内核和每个节点64GB RAM(例如https://spoddutur.github.io/spark-notes/distribution_of_executors_cores_and_memory_for_spark_application.html0 根据上述建议,让我们为每个执行器分配5个
-
 如何在HDFS中附加到相同的文件(火花2.11)
如何在HDFS中附加到相同的文件(火花2.11)我正在尝试使用SparkStreaming将流数据存储到HDFS中,但它会继续在新文件中创建附加到一个文件或几个多个文件中 如果它一直创建n个文件,我觉得效率不会很高 代码 在我的pom中,我使用了各自的依赖项: 火花-core_2.11 火花-sql_2.11 火花-streaming_2.11 火花流-kafka-0-10_2.11
-
新年快乐! python实现绚烂的烟花绽放效果
本文向大家介绍新年快乐! python实现绚烂的烟花绽放效果,包括了新年快乐! python实现绚烂的烟花绽放效果的使用技巧和注意事项,需要的朋友参考一下 做了一个Python的小项目。利用了一点python的可视化技巧,做出烟花绽放的效果,文章的灵感来自网络上一位大神。 一.编译环境 Pycharm 二.模块 1.tkinter:这个小项目的主角,是一个python图形模块。且Python3已经
-
使用AngularJS时如何转花括号显示在页面上?
问题内容: 我希望用户看到双大括号,但是Angular会自动将其绑定。这是与该问题相反的情况,即他们不希望在加载页面时看到用于绑定的花括号。 我希望用户看到以下内容: 但是Angular会替换为值。我认为这可能有效,但是angular仍然将其替换为值: plnkr:http://plnkr.co/edit/XBJjr6uR1rMAg3Ng7DiJ 问题答案: 文档@ ngNonBindable
-
将Kafka中的Avro直接转换为拼花地板到S3
我有以Avro格式存储的Kafka主题。我想使用整个主题(在收到时不会更改任何消息)并将其转换为Parket,直接保存在S3上。 我目前正在这样做,但它要求我每次消费一条来自Kafka的消息,并在本地机器上处理,将其转换为拼花文件,一旦整个主题被消费,拼花文件完全写入,关闭写入过程,然后启动S3多部分文件上传。或《Kafka》中的阿夫罗- 我想做的是《Kafka》中的阿夫罗- 注意事项之一是Kaf
-
如何通过apache火花图形获取SSSP实际路径?
我在火花站点上运行了单源最短路径(SSSP)示例,如下所示: Grax-SSSP预凝胶实例 代码(scala): sourceId:0获取结果: (0,0.0) (4,2.0) (2,1.0) (3,1.0) (1,2.0) 但是我需要如下实际路径: = 如何通过spark graphX获得SSSP实际路径<有人给我一些提示吗<谢谢你的帮助