《花旗银行》专题
-
工件下载花费大量时间却没有结果
> 我有两个Nexus存储库 我在C:\users\login.m2中有两个settings.xml文件: 发布开发人员快照 在C:\apache-maven-3.2.3\conf: [信息]下载:http://30.30.20.40:8085/nexus/content/repositories/releases/org/apache/httpcomponents/project/4.1.1/p
-
使用 MLib 的阿帕奇火花中的分类变量
我对Apache Spark的世界比较陌生。我正在尝试使用LinearRegressionWithSGD()来估计一个大规模模型,我希望在不需要创建庞大的设计矩阵的情况下估计固定效果和交互项。 我注意到在决策树中有一个支持分类变量的实现 https://github.com/apache/spark/blob/master/mllib/src/main/scala/org/apache/spark
-
修复火花结构化流中的检查点[重复]
我在生产中遇到检查点问题,当 spark 无法从_spark_metadata文件夹中找到文件时 已经提出了一个问题,但目前还没有解决方案。 在检查点文件夹中,我看到批次29尚未提交,所以我可以从检查点的、和/或中删除一些内容,以防止火花因缺少文件而失败?
-
Spark是否在读取时维护拼花地板分区?
我很难找到这个问题的答案。假设我为拼花地板编写了一个数据框,并且我使用与相结合来获得一个分区良好的拼花地板文件。请参阅下面: 现在,稍后我想读取拼花文件,所以我这样做: 数据帧是否由分区?换句话说,如果拼花地板文件被分区,火花在将其读入火花数据帧时是否会维护该分区。还是随机分区? 同样,这个答案的“为什么”和“为什么不”也会有所帮助。
-
如何理解拼花文件名称的每个部分
案例: 我在代码中找不到镶木地板文件的一些规则。有人可以解释吗? 代码: https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileFormatWriter.scala https://github.com/apache/spa
-
火花读取来自 SAS 国际移民组织的 JDBC
我正在尝试使用火花 JDBC 从 SAS IOM 读取数据。问题是SAS JDBC驱动程序有点奇怪,所以我需要创建自己的方言: 然而,这还不够。SAS区分了列标签(=人类可读的名称)和列名称(=您在SQL查询中使用的名称),但似乎Spark在模式发现中使用列标签而不是名称,请参阅下面的JdbcUtils摘录: https://github.com/apache/spark/blob/master/
-
火花流:无状态重叠窗口与保持状态
选择无状态滑动窗口操作的一些注意事项是什么(例如,通过updateStateByKey或新mapStateByKey)选择保持状态(例如通过updateStateByKey或新mapStateByKey)时,使用火花流处理连续的有限事件会话流? 例如,考虑以下场景: 一种可穿戴设备跟踪由穿戴者进行的体育锻炼。该装置自动检测何时开始锻炼,并发出信息;在锻炼过程中发出附加信息(如心率);最后,当练习完
-
只从单元格中获取数字的查询-雪花
我在Snowflake中有一个名为“年龄”的大列,5%的行具有“>80”之类的值。 null
-
复制到雪花表不加载数据-没有错误
文件格式定义: 阶段定义:
-
向雪花表[snowflake-cloud-data-platform]写入pyspark dataframe时出错
错误: 由:java.io.InvalidClassException:net.snowflake.spark.snowflake.io.internals3Storage引起;本地类不兼容:stream classdesc serialVersionUID=-7958783596366368645,本地类serialVersionUID=-6090755107217034776
-
将字符串列转换为向量列火花数据
我有一个Spark dataframe,如下所示: 在此数据Frame中,features列是一个稀疏向量。在我的脚本,我必须保存这个DF文件在磁盘上。这样做时,features列被保存为文本列:示例。如您所料,在Spark中再次导入时,该列将保持字符串。如何将列转换回(稀疏)向量格式?
-
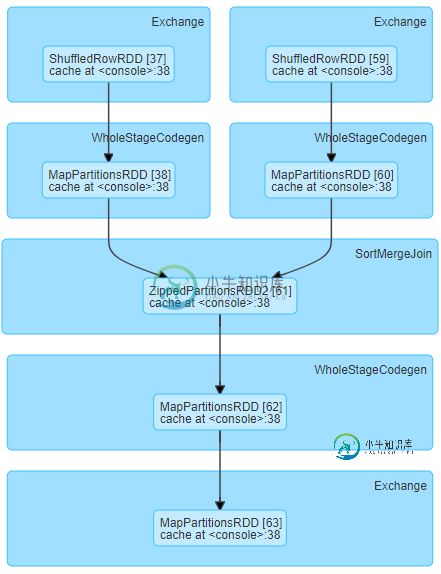 火花洗牌读取小数据需要大量时间
火花洗牌读取小数据需要大量时间我们正在运行以下阶段DAG,对于相对较小的洗牌数据大小(每个任务约19MB),我们经历了较长的洗牌读取时间 一个有趣的方面是,每个执行器/服务器中的等待任务具有等效的洗牌读取时间。这里有一个例子说明了它的含义:对于下面的服务器,一组任务等待大约7.7分钟,另一组等待大约26秒。 这是同一阶段运行的另一个例子。该图显示了3个执行器/服务器,每个执行器/服务器具有相同的洗牌读取时间的统一任务组。蓝色组
-
如何用scala火花从Blob存储中读取文件
-
司机命令停车后,火花工人停了下来
-
如何设置默认的火花日志记录级别?
我将pyspark应用程序从我自己的工作站上的pycharm启动到一个8节点集群。这个群集还有编码在spark-defaults.conf和spark-env.sh中的设置 显示未来的信息消息,但到那时已经太晚了。 如何设置spark开始时的默认日志记录级别?