
火花洗牌读取小数据需要大量时间

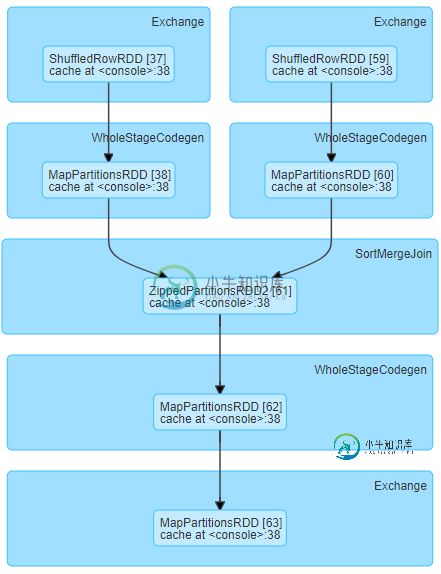
我们正在运行以下阶段DAG,对于相对较小的洗牌数据大小(每个任务约19MB),我们经历了较长的洗牌读取时间
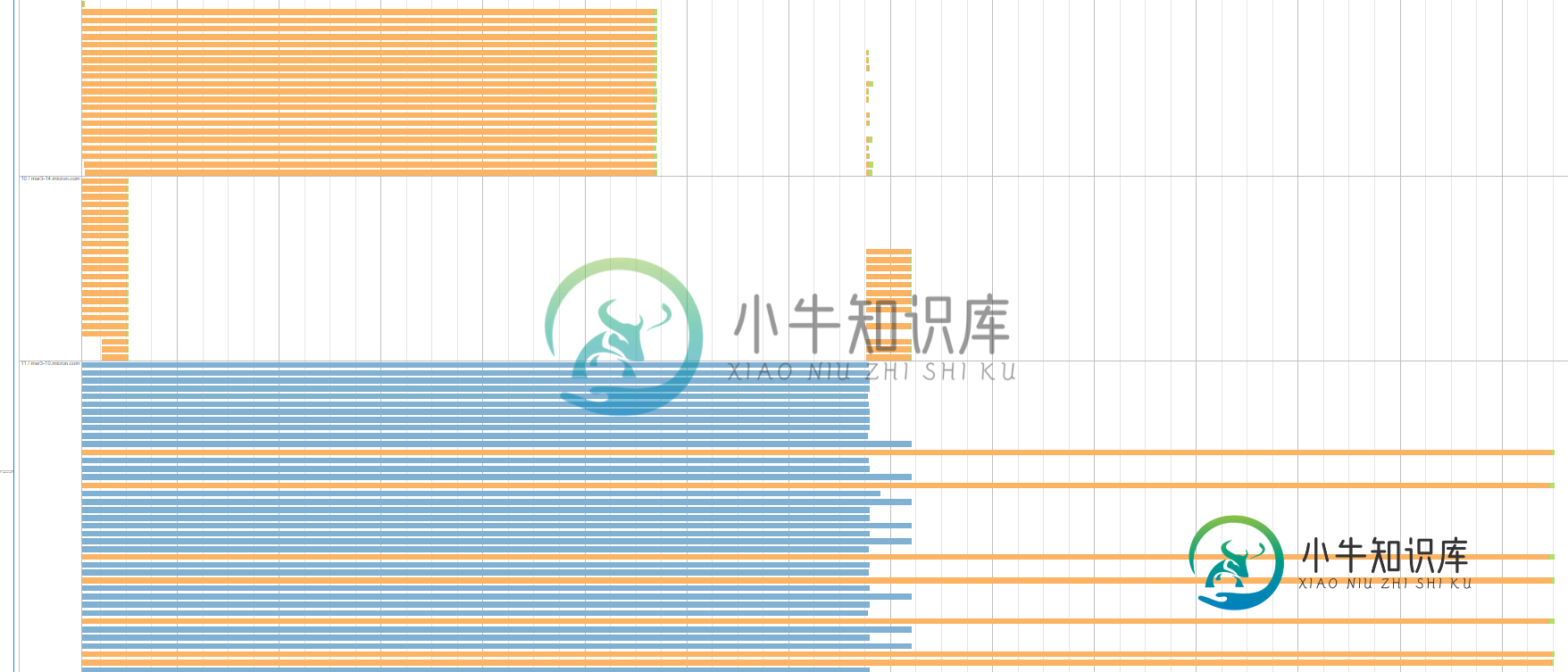
一个有趣的方面是,每个执行器/服务器中的等待任务具有等效的洗牌读取时间。这里有一个例子说明了它的含义:对于下面的服务器,一组任务等待大约7.7分钟,另一组等待大约26秒。

这是同一阶段运行的另一个例子。该图显示了3个执行器/服务器,每个执行器/服务器具有相同的洗牌读取时间的统一任务组。蓝色组表示由于推测执行而被杀死的任务:

output.write.parquet("output.parquet")
comparison.write.parquet("comparison.parquet")
output.union(comparison).write.parquet("output_comparison.parquet")
val comparison = data.union(output).except(data.intersect(output)).cache()
comparison.filter(_.abc != "M").count()
我们将非常感谢你对此的想法。
共有1个答案

显然,问题出在JVM垃圾回收(GC)上。这些任务必须等待GC在远程执行器上完成。相同的洗牌读取时间是由于在执行GC的单个远程主机上有几个任务在等待。我们遵循了这里张贴的建议,问题减少了一个数量级。远程主机上的GC时间与本地洗牌读取时间之间的相关性仍然很小。未来我们想尝试洗牌服务。
-
如果有人能用简单的术语回答这些与火花洗牌相关的问题,我将不胜感激。 在spark中,当加载一个数据集时,我们指定分区的数量,这表示输入数据(RDD)应该被划分为多少个块,并且根据分区的数量启动相等数量的任务(如果假设错误,请纠正我)。对于工作节点中的X个核心数。一次运行相应的X个任务。 沿着类似的思路,这里有几个问题。 因为,所有byKey操作以及联合、重新分区、连接和共组都会导致数据混乱。 >
-
试图读取一个空的镶木地板目录,得到这个错误 无法指定拼花地板的架构。必须手动指定 我的代码 尝试处理scala尝试和定期检查空目录 任何想法
-
我在火花变换函数中有一个简单的问题。 coalesce(numPartitions) - 将 RDD 中的分区数减少到 numPartitions。可用于在筛选大型数据集后更有效地运行操作。 我的问题是 > < Li > < p > coalesce(num partitions)真的会从filterRDD中删除空分区吗? coalesce(numPartitions)是否经历了洗牌?
-
由于,我检查了一个spark作业的输出拼花文件,该作业总是会发出声音。我在Cloudera 5.13.1上使用了 我注意到拼花地板排的大小是不均匀的。第一排和最后一排的人很多。剩下的真的很小。。。 拼花地板工具的缩短输出,: 这是已知的臭虫吗?如何在Spark中设置拼花地板块大小(行组大小)? 编辑: Spark应用程序的作用是:它读取一个大的AVRO文件,然后通过两个分区键(使用
-
我有以下数据帧: 数据帧是从csv文件中读取的。所有类型为1的行都位于顶部,后面是类型为2的行,后面是类型为3的行,以此类推。 我想改变数据帧行的顺序,这样所有的都是混合的。一个可能的结果可能是: 我怎样才能做到这一点?
-
我在一个Spark项目上工作,这里我有一个文件是在parquet格式,当我试图用java加载这个文件时,它给了我下面的错误。但是,当我用相同的路径在hive中加载相同的文件并编写查询select*from table_name时,它工作得很好,数据也很正常。关于这个问题,请帮助我。 java.io.ioException:无法读取页脚:java.lang.runtimeException:损坏的文