《花旗银行》专题
-
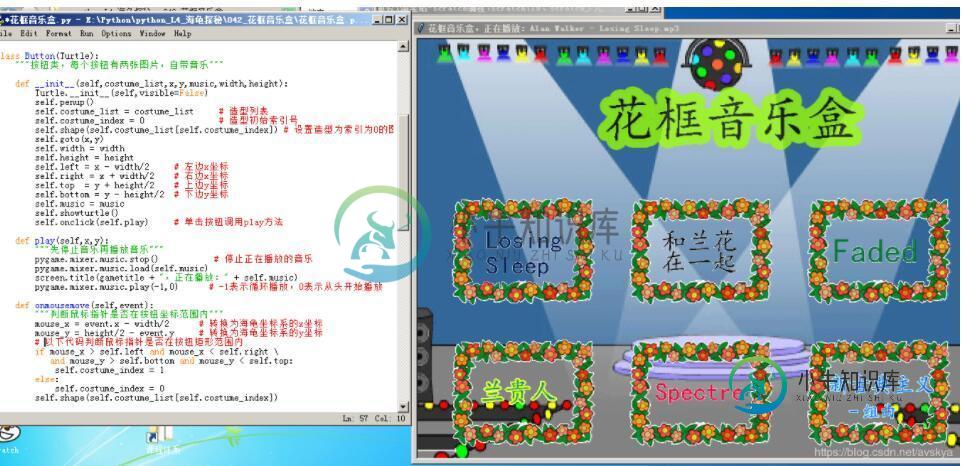 python实现音乐播放器 python实现花框音乐盒子
python实现音乐播放器 python实现花框音乐盒子本文向大家介绍python实现音乐播放器 python实现花框音乐盒子,包括了python实现音乐播放器 python实现花框音乐盒子的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了python实现音乐播放器的具体代码,供大家参考,具体内容如下 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
ImportError:在火花工作程序上没有名为numpy的模块
问题内容: 在客户端模式下启动pyspark。外壳上的导入numpy可以正常运行,但在kmeans中失败。我觉得执行者不知道是否安装了numpy。我没有在任何地方找到任何好的解决方案来让工人了解numpy。我尝试设置PYSPARK_PYTHON,但是那也不起作用。 堆栈跟踪 问题答案: 要在Yarn客户端模式下使用Spark,您需要将所有依赖项安装到Yarn启动执行程序的机器上。这是使这项工作唯一
-
在业力/茉莉花测试中模拟角度服务/承诺
问题内容: 我正在尝试编写业力/茉莉花测试,我想对模拟如何在正在返回诺言的服务上工作进行一些解释。我解释一下我的情况: 我有一个控制器,在其中执行以下调用: 这是我的服务方式: 最后,这是我的单元测试: 我真正想做的是将响应对象({“ elements:…})作为fillMapDatas函数的datas参数。我不了解如何模拟所有服务内容(服务,承诺,然后) 问题答案: 因此,如果您的服务是否按预期
-
React的JSX语法中的双花括号的目的是什么?
问题内容: 从react.js教程中,我们可以看到双花括号的用法: 然后在第二个教程“ Thinking in react”中: 但是,React JSX文档没有描述或提及双花括号。此语法(双curies)有什么用?还有另一种方法可以在jsx中表达相同的内容,或者这仅仅是文档中的遗漏? 问题答案: 它只是在prop值中内联的对象文字。和…一样
-
提取花括号正则表达式php之间的所有值
问题内容: 我有这种形式的内容 我需要数组中花括号之间的所有值,如下所示: 我尝试使用以下代码: 但是我从这里的第一个大括号到内容中找到的最后一个大括号都进入了这里。如何获得上述格式的数组?我知道我使用的模式是错误的。为了得到上面所示的期望输出,应该给出什么? 问题答案: 像这样… 输出:
-
为什么在Alpine Linux上安装Pandas会花费很多时间
问题内容: 我注意到,使用基本操作系统Alpine与CentOS或Debian在Docker容器中安装Pandas和Numpy(它的依赖项)需要花费更长的时间。我在下面创建了一个小测试来演示时差。除了Alpine用来更新和下载构建依赖项以安装Pandas和Numpy的几秒钟之外,为什么setup.py所需的时间比Debian的安装要多70倍? 是否有任何方法可以使用Alpine作为基础映像来加快安
-
从Spark读取拼花地板数据时有多少个分区
我正在使用Spark 1.6.0。以及用于读取分区拼花数据的DataFrame API。 我想知道将使用多少个分区。 以下是我的一些数据: 2182个文件 Spark似乎使用了2182个分区,因为当我执行计数时,作业被拆分为2182个任务。 这似乎得到了的证实 对吗?在所有情况下? 如果是,数据量是否过高(即我是否应该使用df重新分区来减少数据量)?
-
新年快乐! javascript实现超级炫酷的3D烟花特效
本文向大家介绍新年快乐! javascript实现超级炫酷的3D烟花特效,包括了新年快乐! javascript实现超级炫酷的3D烟花特效的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了javascript实现3D烟花特效的具体代码,供大家参考,具体内容如下 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
如何传递-d参数或环境变量到火花作业?
我想在dev/prod环境中更改Spark作业的类型安全配置。在我看来,实现这一点的最简单方法是将传递给作业。那么Typesafe配置库将为我完成这项工作。 将选项添加到spark-submit命令时,不会发生任何情况。 我收到。
-
配置单元外部表无法看到分区拼花文件
我正在使用Spark生成拼花文件(通过分区,使用Snappy压缩),并将它们存储在HDFS位置。 拼花数据文件存储在下 然后为其创建配置单元表,如下所示:
-
带有拼花文件的配置单元中的内存问题
如有任何建议/暗示,不胜感激。
-
用于kafka主题再处理的火花流批处理间隔
当前设置:Spark流作业处理timeseries数据的Kafka主题。大约每秒就有不同传感器的新数据进来。另外,批处理间隔为1秒。通过,有状态数据被计算为一个新流。一旦这个有状态的数据穿过一个treshold,就会生成一个关于Kafka主题的事件。当该值后来降至treshhold以下时,再次触发该主题的事件。 问题:我该如何避免这种情况?最好不要切换框架。在我看来,我正在寻找一个真正的流式(一个
-
AWS Glue ETL作业失败,“删除键失败:拼花输出/_temporary”
我正在由Glue Crawler生成的CSV可数据上运行Glue ETL作业。爬虫点击具有以下结构的目录 这些文件被聚合到一个“聚合输出”表中,该表可以在athena中成功查询。 我正在尝试使用AWS Glue ETL作业将其转换为拼花地板文件。作业失败 我很难找到根本原因 我尝试了多种方式修改Glue作业。我确保分配给该作业的IAM角色有权删除相关存储桶上的文件夹。现在我正在使用AWS提供的默认
-
如何解析CSV字符串到火花数据帧使用scala?
我想将包含字符串记录的RDD转换为Spark数据帧,如下所示。 模式行不在同一个中,而是在另一个变量中: 所以现在我的问题是,我如何使用上面两个,在Spark中创建一个数据帧?我使用的是Spark 2.2版。 我确实搜索并看到了一篇帖子:我可以使用spack-csv将表示为字符串的CSV读取到Apache Spark中吗?然而,这并不是我所需要的,我也无法找到一种方法来修改这段代码以在我的情况下工
-
Spark:将大型数据帧写入拼花文件时出现LeaseExpiredException
我有一个很大的数据框,我正在HDFS中写入拼花文件。从日志中获取以下异常: 谷歌对此进行了搜索,但找不到任何具体的解决方案。将推测设置为false:conf.Set(“spark.投机”,“false”) 但仍然没有帮助。它只完成了几个任务,生成了几个零件文件,然后突然因此错误而停止。 详细信息:Spark版本:2.3.1(这在1.6x中没有发生) 只有一个会话正在运行,这排除了不同会话访问同一位