《花旗银行》专题
-
Flutter firebase存储插件花费大量时间上传文件
我正在使用Flutter开发一个Android应用程序。在我的应用程序中,有一个功能,用户可以从他们的设备上传图片。为了存储图像,我使用firebase云存储&下面是我用于将文件上传到firebase云存储的部分代码。 这里有3个相关的flutter插件,我正在使用,上面的帮助代码上传文件。 一切正常。不过,文件上传要花很多时间。几乎需要40-50秒才能完成步骤3()。有时也是1-半分钟。关于我的
-
使用AWS胶水将AWS Redshift转换为S3拼花文件
我们有一个以红移方式处理数据的用例。但我想在S3中创建这些表的备份,以便使用Spectrum查询这些表。 为了将表从Redshift移动到S3,我使用了一个胶水ETL。我已经为AWS红移创建了一个爬虫程序。胶水作业将数据转换为拼花地板,并将其存储在S3中,按日期进行分区。然后,另一个爬虫会对S3文件进行爬行,以再次对数据进行编目。 如何消除第二个爬虫并在作业本身中执行此操作?
-
PySpark火花与库伯内特斯大师会话生成器
我最近看到一个pull请求被合并到Apache/Spark存储库中,该存储库显然为K8s上的PySpark添加了初始Python绑定。我在公关上发表了一条评论,问了一个关于如何在Python Jupyter笔记本中使用spark-on-k8s的问题,并被告知在这里问我的问题。 我的问题是: 有没有办法使用PySpark的主控设置为
-
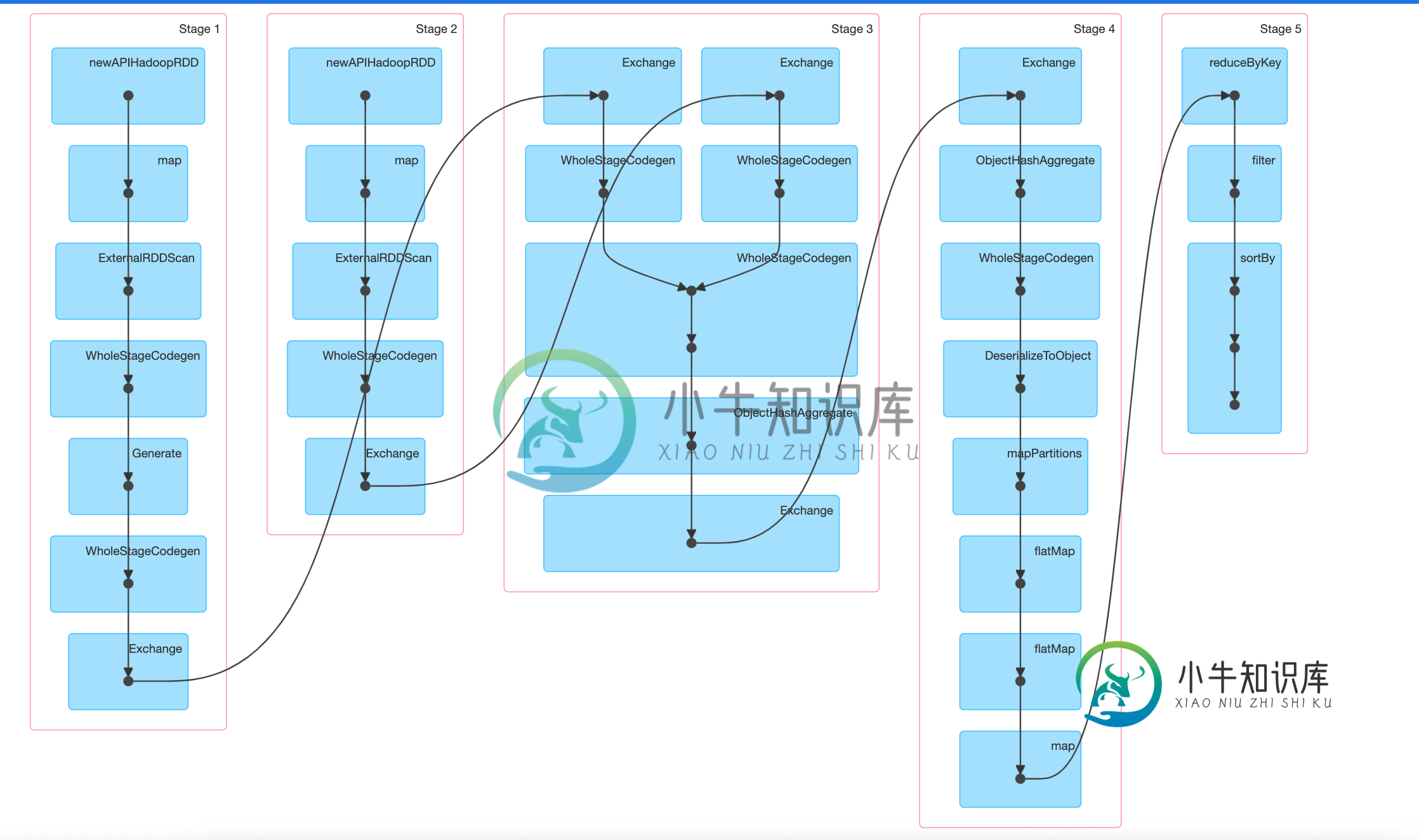 连接后在各阶段之间卡住的火花作业
连接后在各阶段之间卡住的火花作业我有一个spark作业,它连接2个数据集,执行一些转换,并减少数据以给出输出。现在的输入大小相当小(每个200MB数据集),但是在join之后,正如您在DAG中所看到的,作业会被卡住,并且不会继续进行第4阶段。我试着等了几个小时,它给了OOM并显示了第四阶段的失败任务。 为什么spark在stage-3(连接阶段)之后不显示stage-4(数据转换阶段)为活动的?它是不是在第3阶段和第4阶段之间徘
-
Windows 7上的伊斯坦布尔茉莉花节点问题
试图用茉莉花节点运行伊斯坦布尔 运行:节点C:\myproject\project 1\ " ( ^ \__filename测试没有收集覆盖信息,退出而不写入覆盖信息C:\myproject\project ect1\merg\__dirname\_compile: 1(函数(导出、要求、模块、jasmine-node.CMD、node_modules.bin){@IF EXIST"%~dp0\_
-
将新数据追加到已分区的拼花文件中
我正在编写一个ETL进程,在该进程中,我需要每小时读取日志文件,对数据进行分区,并保存它。我正在使用Spark(在数据库中)。日志文件是CSV,所以我读取它们并应用模式,然后执行转换。 我的问题是,如何将每个小时的数据保存为拼花板格式,但添加到现有的数据集?保存时,我需要按DataFrame中存在的4列进行分区。 下面是我的保存行: 我使用parquet是因为分区大大增加了以后的查询。此外,我必须
-
Google Cloud Dataproc最后阶段作业失败引发的火花
我在Dataproc上使用Spark集群,但我的作业在处理结束时失败了。 我的数据源是Google Cloud Storage上csv格式的文本日志文件(总量为3.5TB,5000个文件)。 处理逻辑如下: 将文件读到DataFrame(模式[“timestamp”,“message”]); 将所有邮件分组到1秒的窗口中; 对每个分组消息应用管道[tokenizer->HashingTF]以提取单
-
如何用Python从拼花文件创建CSV文件?[重复]
我有一些代码可以读取一个拼花文件,然后显示它,就像这样: 这工作正常,但我想从输出创建一个CSV文件,即: 我希望创建一个CSV文件,其中包含列标题、逗号分隔的数据和数据。这样地: 我纠结于如何将拼花文件中的结果转换为CSV文件。你能帮助我吗?
-
阿帕奇火花-卡桑德拉番石榴不亲和性
我正在用SparkMaster api 7077执行JettyRun和ClusterMode。我将cassandra驱动程序和spark-cassandra连接器的jar传递给spark conf(setjar) 有些时候,如果我重新启动,它是有效的,但有几次,我不得不尝试和尝试,从来没有工作。 我尝试了一些答案,比如将Spark番石榴罐子重命名为19版本,但总是遇到同样的问题。 怎么回事?
-
雪花存储过程中的最大JavaScript字符串大小
Snowflake文档指出,VARCHAR列仅限于16 MB未压缩的https://docs.Snowflake.net/manuals/sql-reference/data-types-text.html#data-types-for-text-strings Snowflake文档指出,VARCHAR数据会自动转换为JavaScript字符串数据类型。 https://docs.Snowfla
-
如何使用 Java UDF 向火花数据帧添加新列
我有一个 功能,请告诉我是否有任何解决方法。 谢谢你。!
-
火花数据帧保存AsTable不截断数据从Hive表
我正在使用Spark 2.1.0和Java SparkSession来运行我的SparkSQL。我正在尝试保存一个
-
雪花创建或替换表作为无法识别的值
为什么我会得到这个错误消息,尤其是在中唯一的列是varchar数据类型的情况下?
-
我们可以在程序中使用雪花表函数吗?
专家们, 我正在尝试使用tables函数内的雪花程序。然而,它给我带来了一个错误。
-
使用Jmeter连接雪花JDBC连接器时收到错误
我对雪花+JMeter是新手。当我尝试使用以下配置来配置和运行Jmeter时,我收到以下错误。 null 我不确定,我在这里遗漏了什么。请帮帮我。 *来自Jemter结果视图的错误信息**响应消息:java.sql.sqlException:无法创建PoolableConnectionFactory(JDBC驱动程序遇到通信错误。消息:HTTP请求遇到异常:连接到