
连接后在各阶段之间卡住的火花作业

我有一个spark作业,它连接2个数据集,执行一些转换,并减少数据以给出输出。现在的输入大小相当小(每个200MB数据集),但是在join之后,正如您在DAG中所看到的,作业会被卡住,并且不会继续进行第4阶段。我试着等了几个小时,它给了OOM并显示了第四阶段的失败任务。
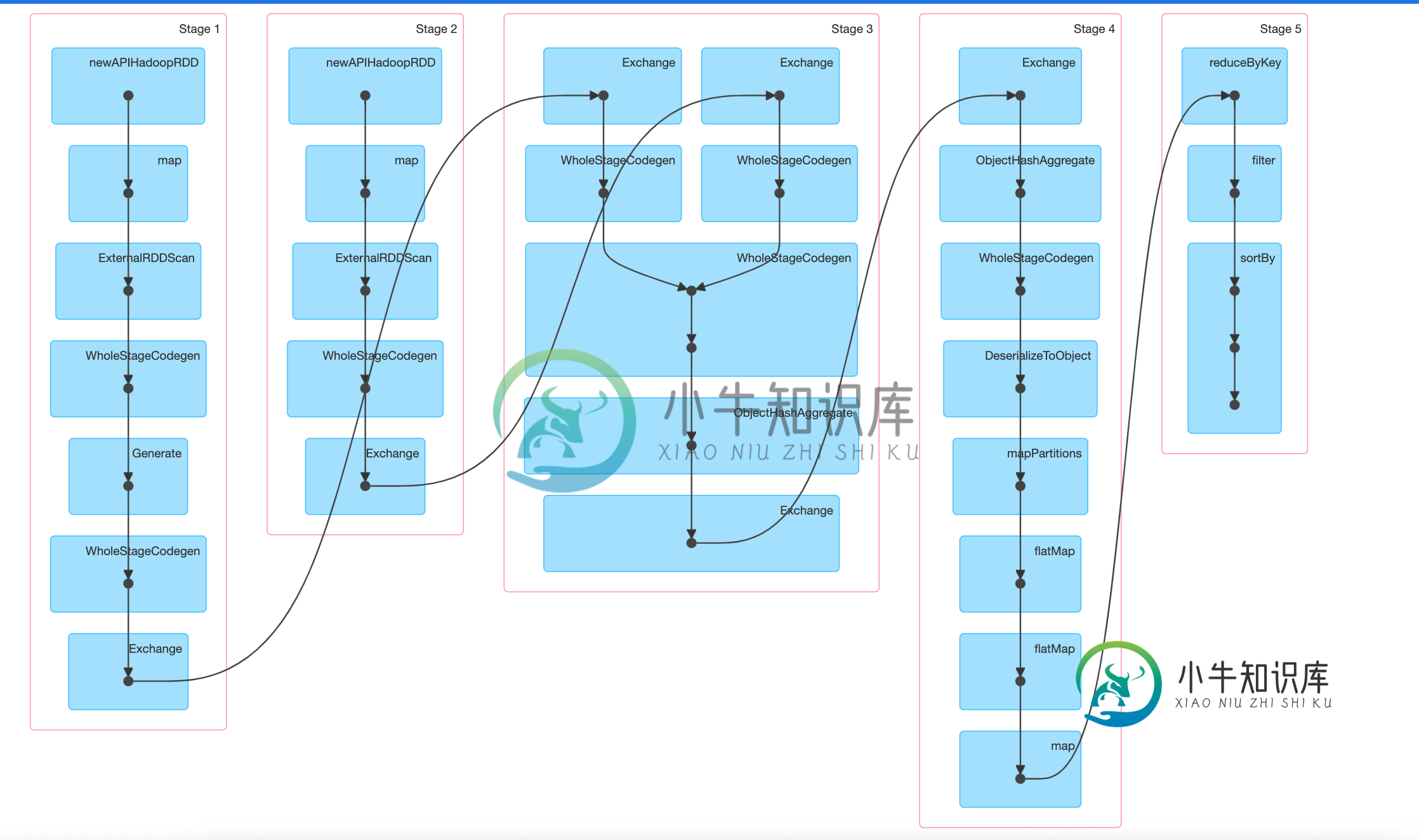
- 为什么spark在stage-3(连接阶段)之后不显示stage-4(数据转换阶段)为活动的?它是不是在第3阶段和第4阶段之间徘徊?
- 我可以做什么来提高我的火花工作的绩效?我尝试增加洗牌分区,但结果还是一样。
职务代码:
joinedDataset.groupBy("group_field")
.agg(collect_set("name").as("names")).select("names").as[List[String]]
.rdd. //converting to rdd since I need to use reduceByKey
.flatMap(entry => generatePairs(entry)) // this line generates pairs of words out of input text, so data size increases here
.map(pair => ((pair._1, pair._2), 1))
.reduceByKey(_+_)
.sortBy(entry => entry._2, ascending = false)
.coalesce(1)
共有1个答案

在executor上尝试初始排序,然后reduce+排序
joinedDataset.groupBy("group_field")
.agg(collect_set("name").as("names")).select("names").as[List[String]]
.rdd. //converting to rdd since I need to use reduceByKey
.flatMap(entry => generatePairs(entry)) // this line generates pairs of words out of input text, so data size increases here
.map(pair => ((pair._1, pair._2), 1))
.sortBy(entry => entry._2, ascending = false) // Do a initial sort on executors
.reduceByKey(_+_)
.sortBy(entry => entry._2, ascending = false)
.coalesce(1)
-
我在Dataproc上使用Spark集群,但我的作业在处理结束时失败了。 我的数据源是Google Cloud Storage上csv格式的文本日志文件(总量为3.5TB,5000个文件)。 处理逻辑如下: 将文件读到DataFrame(模式[“timestamp”,“message”]); 将所有邮件分组到1秒的窗口中; 对每个分组消息应用管道[tokenizer->HashingTF]以提取单
-
我正在研究建立一个JDBC Spark连接,以便从r/Python使用。我知道和都是可用的,但它们似乎更适合交互式分析,特别是因为它们为用户保留了集群资源。我在考虑一些更类似于Tableau ODBC Spark connection的东西--一些更轻量级的东西(据我所知),用于支持简单的随机访问。虽然这似乎是可能的,而且有一些文档,但(对我来说)JDBC驱动程序的需求是什么并不清楚。 既然Hiv
-
我使用的是datastax提供的spark-cassandra-connector 1.1.0。我注意到了interining问题,我不知道为什么会发生这样的事情:当我广播cassandra connector并试图在执行程序上使用它时,我重复了异常,这表明我的配置无效,无法在0.0.0连接到cassandra。 示例StackTrace:
-
我创建并持久化一个df1,然后在其上执行以下操作: 我有一个有16个节点的集群(每个节点有1个worker和1个executor,4个内核和24GB Ram)和一个master(有15GB Ram)。Spark.shuffle.Partitions也是192个。它挂了2个小时,什么也没发生。Spark UI中没有任何活动。为什么挂这么久?是dagscheduler吗?我怎么查?如果你需要更多的信息
-
刚才,我们使用datastax spark连接器计算了一些统计数据。重复的查询在每次执行时返回不同的结果。 这可能是卡桑德拉、火花或连接器的问题吗?在每一种情况下,是否存在一些配置方法来防止这种情况?
-
我有一个运行sql联接的火花作业。 我可视化的DAG和它创建+5阶段的每个加入。无论如何,在DAG有大约40个阶段的阶段之后,下一个步骤总是以异常失败,即在8次迭代之后,每个迭代有5个阶段。 每个节点3个实例(R3.2xLarge)=>12个执行器实例