
火花工作之间的巨大时间间隔

我创建并持久化一个df1,然后在其上执行以下操作:
df1.persist (From the Storage Tab in spark UI it says it is 3Gb)
df2=df1.groupby(col1).pivot(col2) (This is a df with 4.827 columns and 40107 rows)
df2.collect
df3=df1.groupby(col2).pivot(col1) (This is a df with 40.107 columns and 4.827 rows)
-----it hangs here for almost 2 hours-----
df4 = (..Imputer or na.fill on df3..)
df5 = (..VectorAssembler on df4..)
(..PCA on df5..)
df1.unpersist
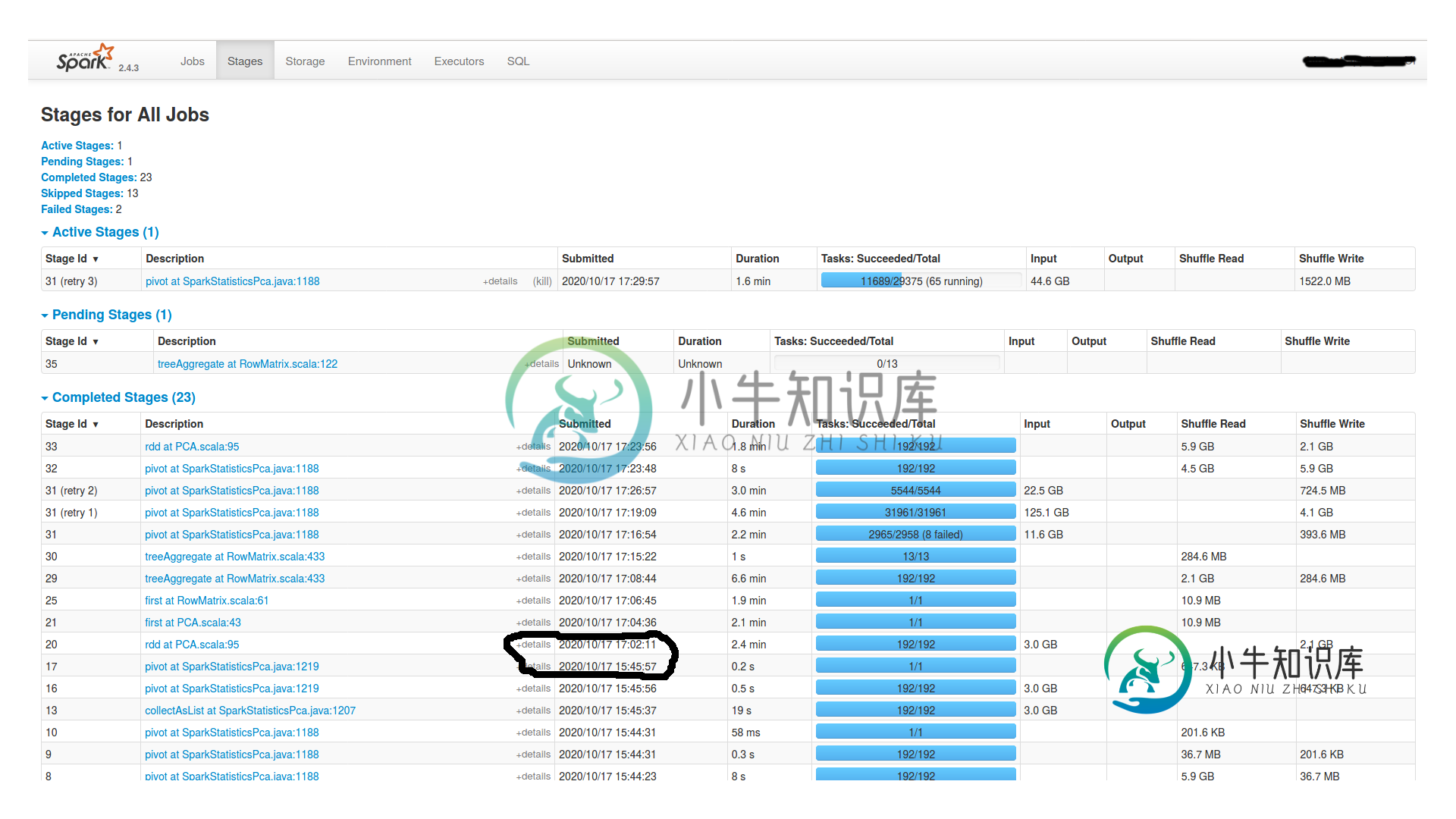
我有一个有16个节点的集群(每个节点有1个worker和1个executor,4个内核和24GB Ram)和一个master(有15GB Ram)。Spark.shuffle.Partitions也是192个。它挂了2个小时,什么也没发生。Spark UI中没有任何活动。为什么挂这么久?是dagscheduler吗?我怎么查?如果你需要更多的信息,请告诉我。
---编辑1---
OpenJDK 64-Bit Server VM warning: INFO: os::commit_memory(0x00000003fe900000, 6434586624, 0) failed; error='Cannot allocate memory' (errno=12)
---编辑2---
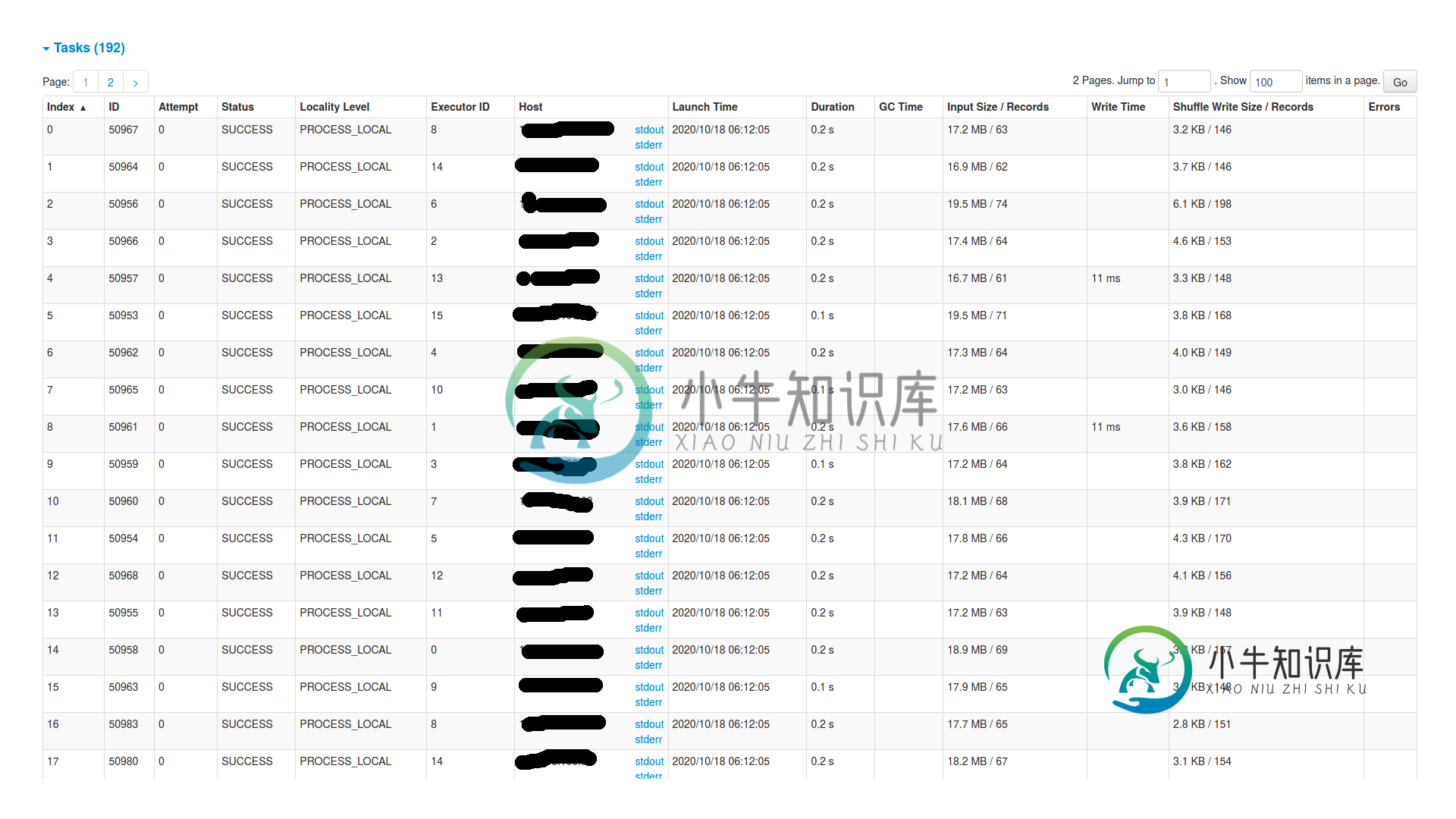
这里是最后一个枢轴的任务部分(舞台图片中id为16的舞台)..就在绞刑之前。似乎所有192个分区都有相当数量的数据,从15到20MB不等。
共有1个答案

Spark中的pivot生成一个额外的阶段来获取pivot值,这在水下发生,可能需要一些时间,并且取决于资源的分配方式,等等。
-
我正在使用的,并将其调用为 。 的方差非常高,以至于大约1%的对集(用百分位数方法验证)使得集合中的值总数的20%。如果Spark随机使用shuffle进行分区,那么很有可能会有1%的数据落入同一分区,从而导致工作人员之间的负载不平衡。 有没有办法确保“重”元组在分区中正常分布?我实际上将分成两个分区,和,基于) 给出的 阈值,以便分离这组元组,然后重新分区。 但获得几乎相同的运行时间。负载可能已
-
全能的开发者们。我在Spark中运行一些基本的分析,在这里我查询多节点Cassandra。我正在运行的代码以及我正在处理的一些非链接代码是: Spark的版本是1.6.0,Cassandra v3。0.10,连接器也是1.6.0。键空间有,表有5列,实际上只有一行。如您所见,有两个节点(OracleVM中制作的虚拟Macine)。 我的问题是,当我测量从spark到cassandra的查询时间时,
-
Spark streaming以微批量处理数据。 使用RDD并行处理每个间隔数据,每个间隔之间没有任何数据共享。 但我的用例需要在间隔之间共享数据。 > 单词“hadoop”和“spark”与前一个间隔计数的相对计数 所有其他单词的正常字数。 注意:UpdateStateByKey执行有状态处理,但这将对每个记录而不是特定记录应用函数。 间隔-1 输入: 输出: 火花发生3次,但输出应为2(3-1
-
如何在2.1.1中存档相同的行为? 谢谢你。
-
我正在尝试从这个Scala代码写入csv文件。我使用HDFS作为临时目录,然后writer.write在现有子文件夹中创建一个新文件。我收到以下错误消息: java.io./tfsdl-ghd-wb/raidnd/Incte_19 如果我选择新建文件或退出文件,也会发生同样的情况,我已经检查了路径是否正确,只想在其中创建一个新文件。 问题是,为了使用基于文件系统的源写入数据,您需要一个临时目录,这
-
我有一个spark作业,它连接2个数据集,执行一些转换,并减少数据以给出输出。现在的输入大小相当小(每个200MB数据集),但是在join之后,正如您在DAG中所看到的,作业会被卡住,并且不会继续进行第4阶段。我试着等了几个小时,它给了OOM并显示了第四阶段的失败任务。 为什么spark在stage-3(连接阶段)之后不显示stage-4(数据转换阶段)为活动的?它是不是在第3阶段和第4阶段之间徘