《花旗银行》专题
-
 11.0《2015最新Android基础入门教程》完结散花~
11.0《2015最新Android基础入门教程》完结散花~主要内容:引言:,1.此套教程的由来,2.扒一扒我的一些情况,3.一些自学心得以及资源分享,4)一些答疑,致谢:引言: 从六月底就开始编写这套教程,历时将近五个多月,今天终于写完了,全套教程正文部分148篇, 十大章,从基本UI控件到四大组件,Intent,Fragment,事件处理,数据存储,网络编程,绘图与动画, 多媒体,系统服务等都进行了详细的讲解!代码都是都是在Android Studio上进行编写的,全文 采用Markdown,行文结构清晰,还结合了实际开发中一些常见的问题进行了剖析.
-
火花作业错误超出GC开销限制[重复]
我正在运行一个火花作业,我在spark-defaults.sh.设置了以下配置,我在名称节点中有以下更改。我有1个数据节点。我正在处理2GB的数据。 但我得到一个错误,说GC限制超过。 这是我正在编写的代码。 我甚至尝试了GroupByKey而不是也。但是我得到了同样的错误。但是,当我试图删除还原ByKey或GroupByKey我得到的输出。有人能帮我解决这个错误吗? 我是否也应该在hadoop中
-
茉莉花-如何监视函数内的函数调用?
问题内容: 以下是我的控制器中的内容: 而且我想监视,以便在被调用时是: 如何才能做到这一点? 问题答案: 默认情况下,当您与 jasmine一起 使用时,它将模拟该函数,并且实际上不执行其中的任何操作。如果要在其中测试其他函数调用,则需要调用,如下所示: 应该这样做。
-
在Node.js中循环使用findOne会花费很长时间
问题内容: 我将Node.js与MongoDB结合使用,也将Monk用于数据库访问。我有以下代码: 关于此代码,我有两个问题: 我看到执行时间,并且“文件已保存!” 首先输入字符串,然后在控制台中看到朋友的名字。这是为什么?我不应该先看名字然后再看执行时间吗?是否因为Node.js的异步特性? 名称在控制台中的打印速度非常慢,速度就像两秒钟内出现一个名称一样。为什么这么慢?有没有办法使过程更快?
-
错误:com。液火花沃拉。VoraConfigurationException:未找到ZooKeeper主机
运行命令vc时。sql(testsql),出现以下错误 通用域名格式。液火花沃拉。VoraConfigurationException:未找到ZooKeeper主机 动物园管理员在所有三个节点上启动并运行服务。 错误日志显示以下内容: 2016-09-14 15:14:32418-信息[NIOServerCxn.工厂:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactor
-
优化从s3 bucket中分区拼花文件的读取
我有一个拼花格式的大数据集(大小约1TB),分为2个层次:
-
Kafka Conenct HDFS接收器以拼花格式保存数据
使用Kafka Connect HDFS Sink,我能够将avro数据写入Kafka主题并将数据保存在hive/hdfs中。 我正在尝试使用格式类以拼花文件格式保存数据 快速启动hdfs。属性如下 当我将数据发布到Kafka时,表在hive中创建,test\u hdfs\u parquet目录在hdfs中创建,但由于以下异常,Sink无法以parquet格式保存数据
-
Kafka分区是如何在火花流与Kafka共享的?
我想知道Kafka分区是如何在从executor进程内部运行的SimpleConsumer之间共享的。我知道高水平的Kafka消费者是如何在消费者群体中的不同消费者之间分享利益的。但是,当Spark使用简单消费者时,这是如何发生的呢?跨计算机的流作业将有多个执行程序。
-
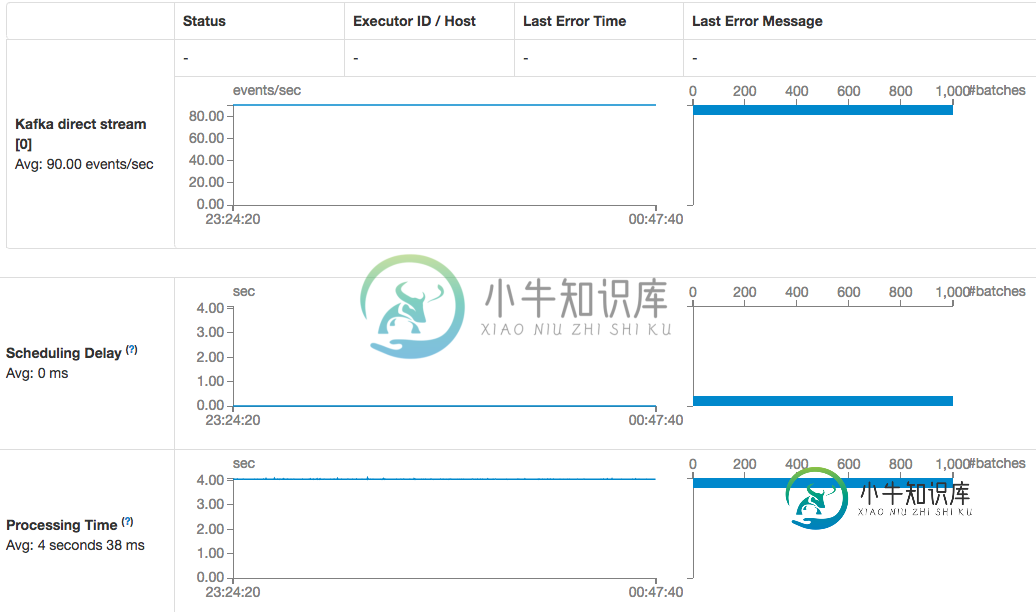 火花流Kafka直接消费者消费速度下降
火花流Kafka直接消费者消费速度下降我使用的是运行在AWS中的spark独立集群(spark and spark-streaming-kafka version 1.6.1),并对检查点目录使用S3桶,每个工作节点上没有调度延迟和足够的磁盘空间。 没有更改任何Kafka客户端初始化参数,非常肯定Kafka的结构没有更改: 也不明白为什么当直接使用者描述说时,我仍然需要在创建流上下文时使用检查点目录?
-
火花流从Kafka源返回到检查点或重绕
当streaming Spark DStreams作为来自Kafka源的消费者时,可以检查Spark上下文,因此当应用程序崩溃(或受到的影响)时,应用程序可以从上下文检查点恢复。但如果应用程序“意外地部署了错误的逻辑”,您可能想要倒回到最后一个主题+分区+偏移量,以重播某个Kafka主题的分区偏移量位置的事件,这些位置在“错误逻辑”之前正常工作。当检查点生效时,流式应用程序如何被重绕到最后的“好点
-
镶木地板文件大小,消防软管与火花
我通过两种方法生成拼花地板文件:动弹消防软管和火花作业。它们都被写入S3上相同的分区结构中。两组数据都可以使用相同的Athena表定义进行查询。两者都使用gzip压缩。 然而,我注意到Spark生成的拼花地板文件大约是Firehose生成的拼花地板文件的3倍大。有什么理由会这样吗?在使用Pyarrow加载模式和元数据时,我确实注意到了一些差异: 模式差异可能是罪魁祸首吗?还有别的原因吗? 这两个特
-
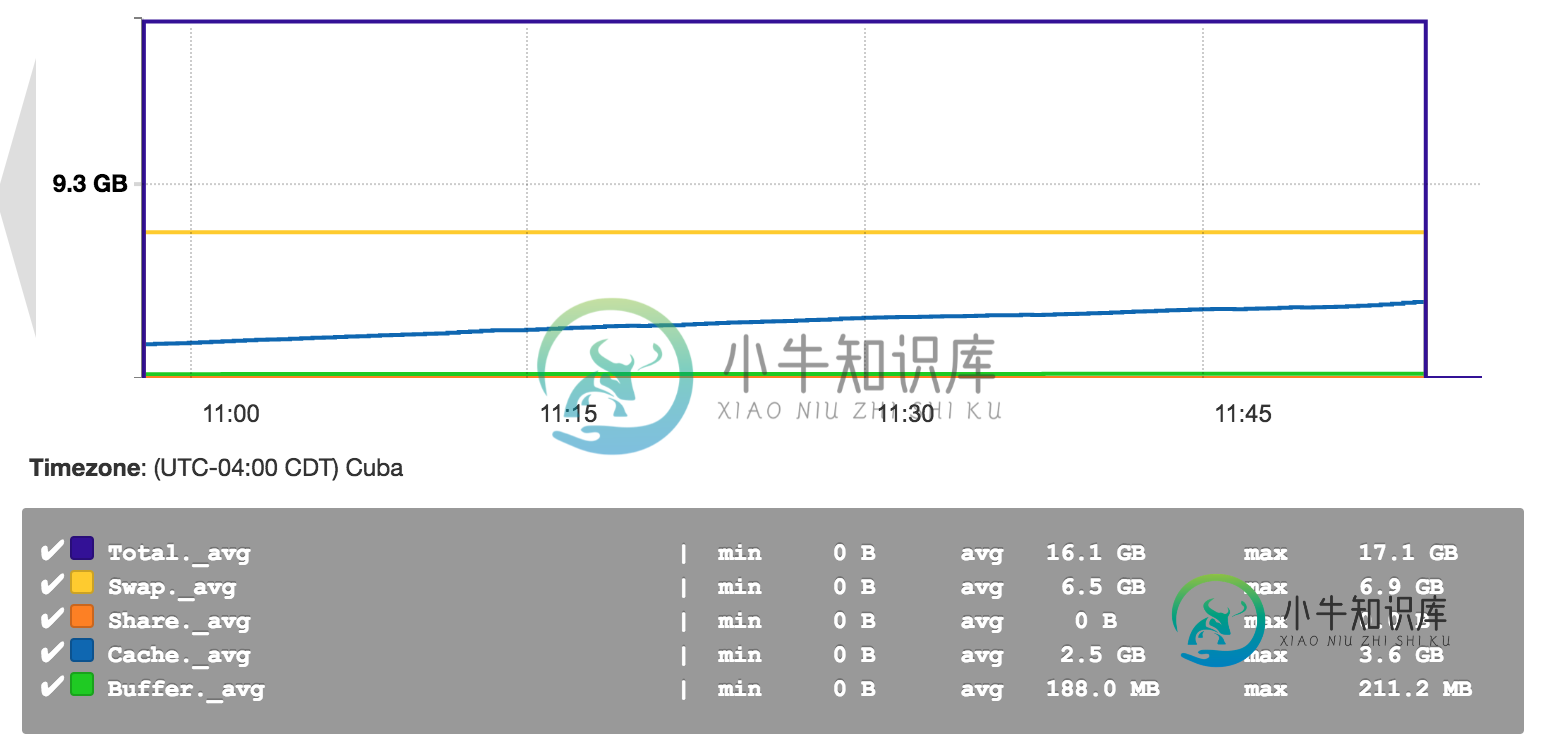 火花集群的Ambari仪表板内存使用说明
火花集群的Ambari仪表板内存使用说明我使用Ambari来监视我的spark群集,我对所有的内存类别都有点困惑;有专业知识的人能解释一下这些术语的含义吗?提前感谢! 以下是Ambari内存使用率缩小的屏幕截图: 基本上,交换、共享、缓存和缓冲区的内存使用代表什么?(我想我完全理解了)
-
如何在拼花架构定义中指定列描述
我正在使用层叠将文本分隔转换为拼花地板 下面是拼花图案: 以下是avro模式: 如何跟踪parquet中avro文件中的“doc”部分?
-
第一次预期失败后停止茉莉花测试
我熟悉python单元测试测试,如果断言失败,该测试将被标记为“失败”,并继续进行其他测试。另一方面,茉莉花将继续通过所有期望,即使其中一个失败。在第一个预期失败后,如何使Jasmine停止处理测试? 我想错了吗?我有一些测试有很多< code>expect,当只有第一个错误时,显示所有的堆栈跟踪似乎是一种浪费。
-
在火花中读取csv时防止分隔符碰撞
如何捕捉此字段中的而不将其视为CSV分隔符?