
火花集群的Ambari仪表板内存使用说明

我使用Ambari来监视我的spark群集,我对所有的内存类别都有点困惑;有专业知识的人能解释一下这些术语的含义吗?提前感谢!
以下是Ambari内存使用率缩小的屏幕截图:
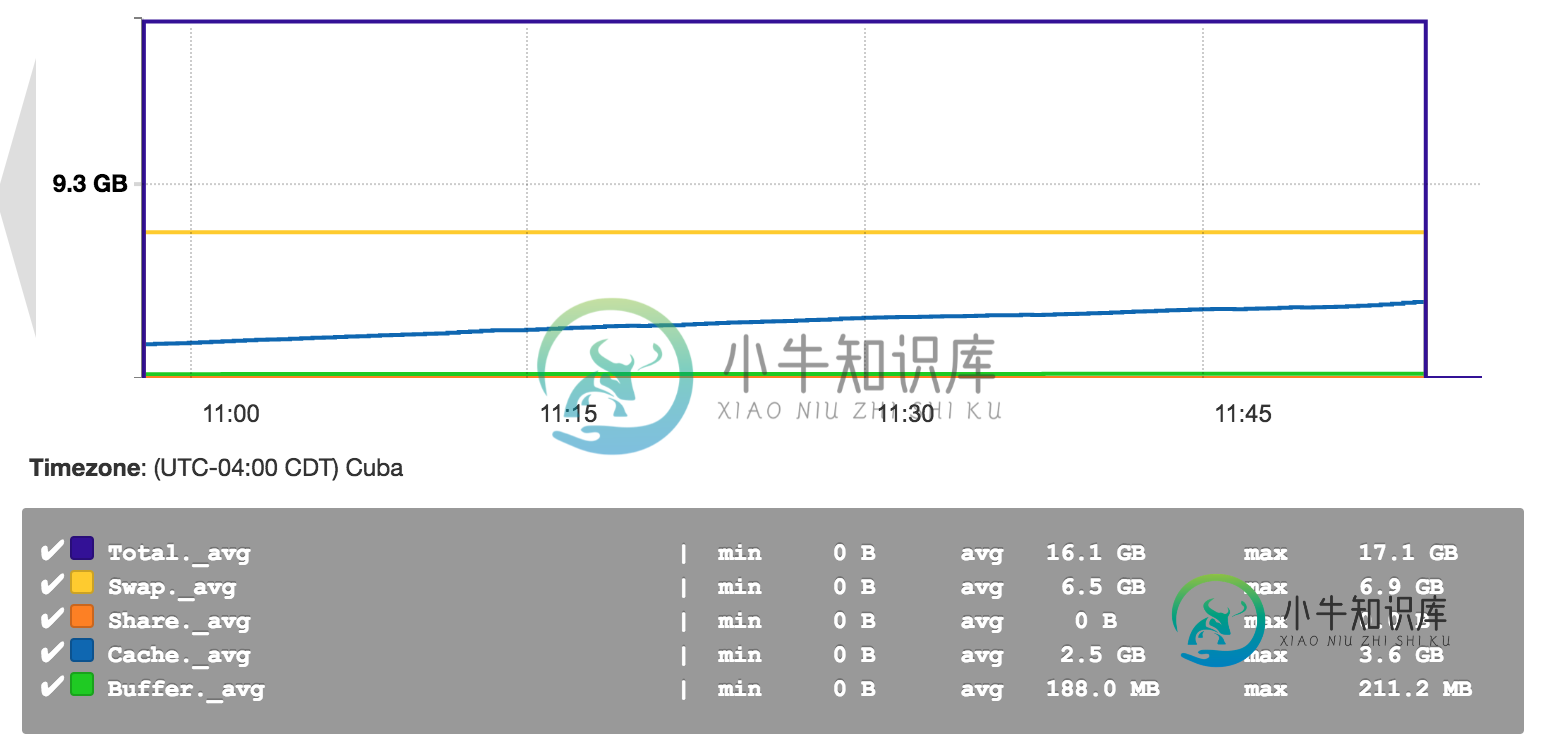
基本上,交换、共享、缓存和缓冲区的内存使用代表什么?(我想我完全理解了)
共有1个答案

这里没有Spark或Ambari特定的东西。这些是基本的Linux/Unix内存管理术语:
简而言之:
- 交换是写入磁盘的内存的一部分。请参阅Wikipedia和什么是交换内存
- 缓冲区和缓存用于缓存文件系统数据和文件数据。看看Linux中缓冲区和高速缓存的区别是什么?和内存管理概述
- 共享内存是用于共享库的虚拟内存的一部分
-
当我执行时 kubectl代理 它为我提供了o/p:开始在虚拟机上的127.0.0.1:8001上提供服务 我想在主机上看到仪表板,这给我带来了问题。 192 168 113 8001 api命名空间库贝系统服务https kubernetes仪表板代理 有什么问题,我没明白。我是库伯内特斯的新手。谢谢
-
大家知道什么叫做云计算吗?事实上,目前并没有一个确定的定义。然而概括来讲,所谓的云计算,指的就是把你的软件和服务统一部署在数据中心,统一管理,从而实现高伸缩性。 云计算具有以下特性: 虚拟化和自动化 服务器,存储介质,网络等资源都可以随时替换 所有的资源都由云端统一管理 高度的伸缩性以满足业务需求 集中于将服务传递给业务. 云计算的部署方式 从部署方式来说,总共有两类云计算 私有云:数据中心部署在
-
我的spark程序在小数据集上运行良好。(大约400GB)但是当我将其扩展到大型数据集时。我开始得到错误
-
我正在尝试使用命令从 azure HDInsight 群集的头节点运行火花 scala 应用程序 类com.test.spark.WordCountSparkJob1.jarwasbs 我正在接受它的异常。 导致原因:java.lang.ClassCastExc的:不能分配scala.collection.immutable.列表的实例$序列化代理字段org.apache.spark.rdd.RD
-
我对spark有疑问:HDFS块vs集群核心vs rdd分区。 假设我正在尝试在HDFS中处理一个文件(例如块大小为64MB,文件为6400MB)。所以理想情况下它确实有100个分裂。 我的集群总共有 200 个核心,我提交了包含 25 个执行程序的作业,每个执行程序有 4 个核心(意味着可以运行 100 个并行任务)。 简而言之,我在rdd中默认有100个分区,100个内核将运行。 这是一个好方
-
我是Spark的初学者,我正在运行我的应用程序,从文本文件中读取14KB的数据,执行一些转换和操作(收集、收集AsMap),并将数据保存到数据库 我在我的macbook上本地运行它,内存为16G,有8个逻辑核。 Java最大堆设置为12G。 这是我用来运行应用程序的命令。 bin/spark-submit-class com . myapp . application-master local[*