
火花驱动程序内存和执行器内存

我是Spark的初学者,我正在运行我的应用程序,从文本文件中读取14KB的数据,执行一些转换和操作(收集、收集AsMap),并将数据保存到数据库
我在我的macbook上本地运行它,内存为16G,有8个逻辑核。
Java最大堆设置为12G。
这是我用来运行应用程序的命令。
bin/spark-submit-class com . myapp . application-master local[*]-executor-memory 2G-driver-memory 4G/jars/application . jar
我收到以下警告
2017-01-13 16:57:31.579[执行器任务启动工作人员-8hread]WARNorg.apache.spark.storage.MemoryStore-没有足够的空间来缓存内存中的rdd_57_0!
有谁能告诉我这里出了什么问题,以及我如何提高绩效?还有如何优化浮雕溢出?这是我的本地系统中发生的泄漏的视图
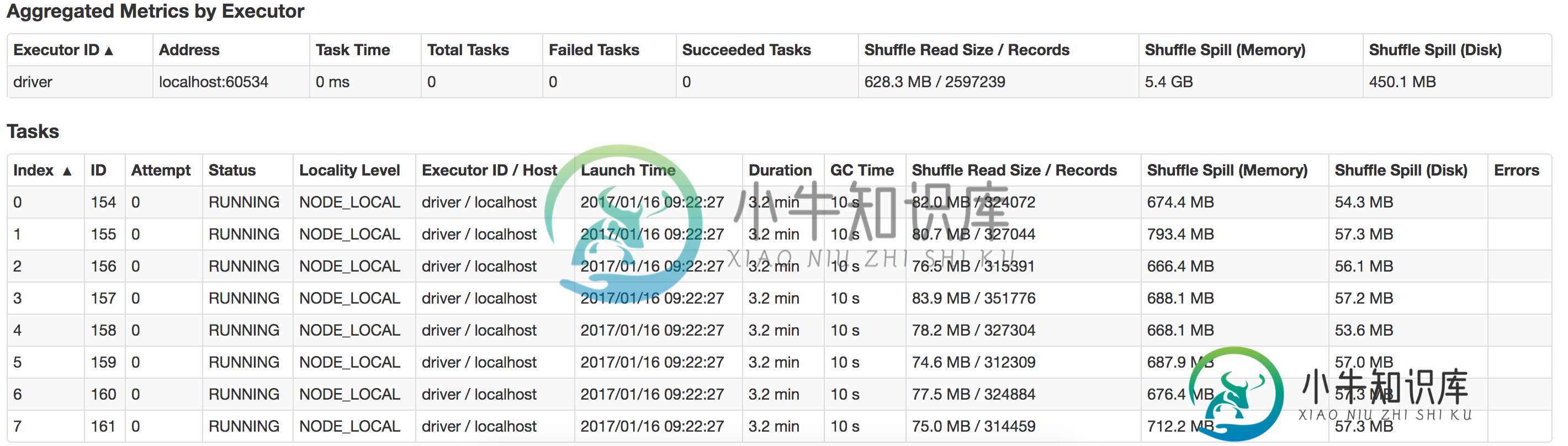
共有2个答案

在本地模式下,您不需要指定master,使用默认参数是可以的。官方网站上说,“Spark的bin目录中的火花提交脚本用于在集群上启动应用程序。它可以通过统一的界面使用Spark支持的所有集群管理器,因此您不必为每个管理器专门配置应用程序。所以你最好在集群中使用火花提交,本地你可以使用火花壳。

运行具有过多内存的执行程序通常会导致过多的垃圾回收延迟。因此,分配更多内存不是一个好主意。由于您只有14KB数据,因此2GB执行器内存和4GB驱动程序内存绰绰有余。分配这么多内存是没有用的。您甚至可以用100MB内存运行此作业,性能将优于2GB。
在纱线集群模式下运行应用程序时,驱动程序内存更有用,因为应用程序主机运行驱动程序。在这里,您正在本地模式下运行应用程序。不需要驱动程序内存。您可以从作业中删除此配置。
在您的申请中,您已分配
Java Max heap is set at: 12G.
executor-memory: 2G
driver-memory: 4G
总内存分配 = 16GB,而您的 Macbook 只有 16GB 内存。在这里,您已经将RAM内存的总和分配给了您的spark应用程序。
这并不好。操作系统本身消耗大约1GB的内存,而您可能正在运行的其他应用程序也消耗RAM内存。因此,您实际上分配的内存比您拥有的要多。这是您的应用程序抛出错误的根本原因没有足够的空间来缓存RDD
- 将Java堆分配到12 GB是没有用的,需要将其减少到4GB或更小。
- 将执行器内存减少到
执行器内存1G或更少 - 由于您在本地运行,请从您的配置中删除
驱动程序内存。
提交您的作业。它将平稳运行。
如果您非常想了解火花内存管理技术,请参考这篇有用的文章。
关于纱线执行器资源分配的火花
-
我在一个单独的Docker中运行spark-master和spark-worker。 我能看见他们在跑 PS-EF grep火花根3477 3441 0 1 05?00:04:17/usr/lib/jvm/java-1.8-openjdk/jre/bin/java-cp/usr/local/spark/conf/:/usr/local/spark/jars/*-xmx1g org.apache.s
-
我正在对YARN上的Spark作业进行一些内存调优,我注意到不同的设置会给出不同的结果,并影响Spark作业运行的结果。但是,我很困惑,不明白为什么会这样,如果有人能给我一些指导和解释,我会很感激。 我将提供一些背景资料和张贴我的问题和描述案例,我已经经历了他们在下面。 我的环境设置如下: 存储器20G,每个节点20个vCore(共3个节点) Hadoop 2.6.0 火花1.4.0 我的代码对R
-
null null 为了进行简单的开发,我使用在独立集群模式下(8个工作者、20个内核、45.3G内存)执行了我的Python代码。现在我想为性能调优设置执行器内存或驱动程序内存。 在Spark文档中,执行器内存的定义是 每个执行程序进程使用的内存量,格式与JVM内存字符串相同(例如512M、2G)。
-
您从哪里开始调优上面提到的params。我们是从执行器内存开始,得到执行器的数目,还是从核心开始,得到执行器的数目。我跟踪了链接。然而得到了一个高水平的想法,但仍然不确定如何或从哪里开始并得出最终结论。
-
如前所述,更改Spark集群冗长性的理想方法是更改相应的log4j.properties。然而,在dataproc上,Spark在Yarn上运行,因此我们必须调整全局配置,而不是/usr/lib/Spark/conf 几点建议: 在dataproc上,我们有几个gcloud命令和属性可以在集群创建过程中传递。请参阅留档是否可以通过指定更改 /etc/hadoop/conf下的log4j.prope
-
我是否正确理解了客户端模式的文档? 客户端模式与驱动程序在应用程序主程序中运行的集群模式相反? 在客户端模式下,驱动程序和应用程序主程序是独立的进程,因此+必须小于计算机的内存? 在客户端模式下,驱动程序内存不包括在应用程序主内存设置中吗?