
docker中的火花,为驱动程序/执行程序设置内存

我在一个单独的Docker中运行spark-master和spark-worker。
我能看见他们在跑
PS-EF grep火花根3477 3441 0 1 05?00:04:17/usr/lib/jvm/java-1.8-openjdk/jre/bin/java-cp/usr/local/spark/conf/:/usr/local/spark/jars/*-xmx1g org.apache.spark.deploy.master.master--IP节点-master--端口7077--WebUI-端口10080
我不确定我的员工使用的是1G还是8G,我确实通过SparkConf设置内存选项
conf.set("spark.executor.memory", "8g")
conf.set("spark.driver.memory", "8g")
我可以在web ui中看到8g
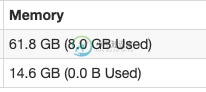
我真的在用8G吗?有没有办法更改xmm1g部分,这些部分显示在ps下的命令行中?
**编辑
我正在运行独立集群(而不是yarn),并且使用pyspark,不可能使用Spark-在独立集群模式下提交python文件
http://spark.apache.org/docs/latest/submitting-applications.html
共有1个答案

通常,您不应该在代码中设置这些选项,因为根据群集管理器,这些选项可能不会起作用。
您应该在spark-submit命令中设置这些。
请参阅此。
Spark属性主要分为两类:一类是与deploy相关的属性,如“Spark.driver.memory”、“Spark.executor.instances”,这类属性在运行时通过SparkConf编程设置时可能不会受到影响,或者行为取决于您选择的集群管理器和部署模式,所以建议通过配置文件或spark-submit命令行选项设置;另一个主要与Spark运行时控制有关,像“Spark.task.maxFailures”,这类属性可以用任何一种方式设置。
更新
# Run a Python application on a Spark standalone cluster
./bin/spark-submit \
--master spark://207.184.161.138:7077 \
examples/src/main/python/pi.py \
1000
-
我是Spark的初学者,我正在运行我的应用程序,从文本文件中读取14KB的数据,执行一些转换和操作(收集、收集AsMap),并将数据保存到数据库 我在我的macbook上本地运行它,内存为16G,有8个逻辑核。 Java最大堆设置为12G。 这是我用来运行应用程序的命令。 bin/spark-submit-class com . myapp . application-master local[*
-
如前所述,更改Spark集群冗长性的理想方法是更改相应的log4j.properties。然而,在dataproc上,Spark在Yarn上运行,因此我们必须调整全局配置,而不是/usr/lib/Spark/conf 几点建议: 在dataproc上,我们有几个gcloud命令和属性可以在集群创建过程中传递。请参阅留档是否可以通过指定更改 /etc/hadoop/conf下的log4j.prope
-
我正在对YARN上的Spark作业进行一些内存调优,我注意到不同的设置会给出不同的结果,并影响Spark作业运行的结果。但是,我很困惑,不明白为什么会这样,如果有人能给我一些指导和解释,我会很感激。 我将提供一些背景资料和张贴我的问题和描述案例,我已经经历了他们在下面。 我的环境设置如下: 存储器20G,每个节点20个vCore(共3个节点) Hadoop 2.6.0 火花1.4.0 我的代码对R
-
在浏览到网络论坛后给出错误。我得到了上面的错误。专家们能帮我解决这个问题吗。此外,我还需要使用Selenium在QC中运行测试集的指导原则。
-
背景我试图运行一个火花提交命令,该命令来自Kafka,并在AWS EMR(版本5.23.0)中使用scala(版本2.11.12)执行JDBC接收器到postgres DB。我看到的错误是 假设问题我认为错误告诉我,在执行器上找不到JDBCPostgres驱动程序,这就是为什么它不能下沉到postgres。 以前的尝试我已经做了以下事情: 在我的结构化流作业中将我的驱动程序标识为 在我的火花提交作
-
我正在通过阅读高性能Spark来学习如何配置Spark应用程序,其中提到的一句话让我感到困惑: 根据我的经验,设置Spark驱动程序内存的良好启发式方法只是不会导致驱动程序内存错误的最低可能值,即为执行程序提供最大可能的资源。 我的理解是驱动程序存在于它自己的节点中,而执行程序独立存在于工作节点上。我本以为我可以最大限度地利用驱动程序内存,而不必担心它会影响执行程序。 这本书的建议是真的吗?如果是