《python爬虫》专题
-
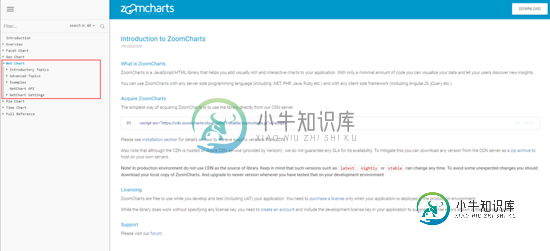 Puppeteer 爬取动态生成的网页实战
Puppeteer 爬取动态生成的网页实战本文向大家介绍Puppeteer 爬取动态生成的网页实战,包括了Puppeteer 爬取动态生成的网页实战的使用技巧和注意事项,需要的朋友参考一下 Puppeteer 相关介绍与安装不过多介绍,可通过以下链接进行学习 一、Puppeteer 开源地址 英文文档 中文社区 二、爬取动态网页 1. 需求 首先,了解下我们的需求: 爬取zoomcharts 文档中 Net Chart 目录下所有访问连接
-
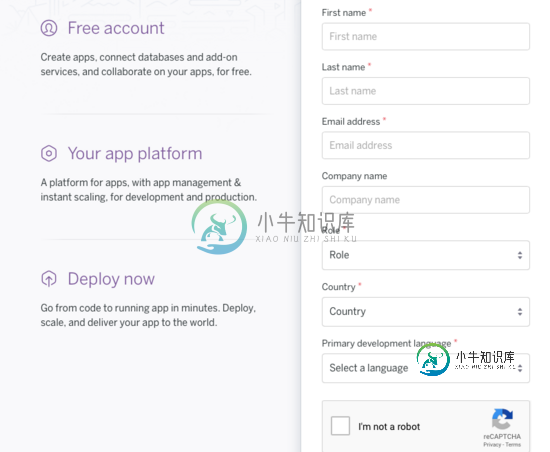 详解Spring Boot 项目部署到heroku爬坑
详解Spring Boot 项目部署到heroku爬坑本文向大家介绍详解Spring Boot 项目部署到heroku爬坑,包括了详解Spring Boot 项目部署到heroku爬坑的使用技巧和注意事项,需要的朋友参考一下 背景:最近小组进行一个环境比较恶劣的项目,由于没有真实的测试环境,决定上云,最终选择国外的heroku,折腾半天,其中有一些坑在这里记录下来,方便网友及个人。 1.账号注册 heroku官网: https://www.h
-
刮擦不产生结果(已爬网0页)
试图找出scrapy的工作原理,并使用它在论坛上查找信息。 items.py spider.py 在这个例子中,我试图获取帖子标题的论坛是:https://forum.bodybuilding.nl/fora/supplementen.22/ 然而,我一直没有得到任何结果: 类BodyBuildingSpider(BaseSpider):2017-10-07 00:42:28[scrapy.uti
-
Nutch Crawl-删除每个爬行影响的段
我注意到在每次Nutch抓取过程中,发送到Solr的索引不一致。有时会显示网页的最新更改,有时会显示较旧的更改。 原因 注意到Nutch将旧段的索引提供给Solr。 当前解决方案 在获取之前删除所有旧段,似乎解决了问题。 问题 想知道这种方法是否有任何含义,或者我对此的理解是不正确的。还想知道为什么Nutch在爬行过程中不会自动删除旧段。 谢谢。
-
15. 豆瓣电影Top250信息爬取实战
通过本案例[豆瓣电影Top250信息爬取]锻炼除正则表达式之外三种信息解析方式:Xpath、BeautifulSoup和PyQuery。 爬取url地址:https://movie.douban.com/top250 分析: 分析url地址:https://movie.douban.com/top250 每页25条数据,共计10页 第一页:https://movie.douban.com/top2
-
Linux/Nginx如何查看搜索引擎蜘蛛爬虫的行为
本文向大家介绍Linux/Nginx如何查看搜索引擎蜘蛛爬虫的行为,包括了Linux/Nginx如何查看搜索引擎蜘蛛爬虫的行为的使用技巧和注意事项,需要的朋友参考一下 摘要 做好网站SEO优化的第一步就是首先让蜘蛛爬虫经常来你的网站进行光顾,下面的Linux命令可以让你清楚的知道蜘蛛的爬行情况。下面我们针对nginx服务器进行分析,日志文件所在目录:/usr/local/nginx/logs/ac
-
 Java爬虫实战抓取一个网站上的全部链接
Java爬虫实战抓取一个网站上的全部链接本文向大家介绍Java爬虫实战抓取一个网站上的全部链接,包括了Java爬虫实战抓取一个网站上的全部链接的使用技巧和注意事项,需要的朋友参考一下 前言:写这篇文章之前,主要是我看了几篇类似的爬虫写法,有的是用的队列来写,感觉不是很直观,还有的只有一个请求然后进行页面解析,根本就没有自动爬起来这也叫爬虫?因此我结合自己的思路写了一下简单的爬虫。 一 算法简介 程序在思路上采用了广度优先算法,对未遍历过
-
 Python3爬虫之自动查询天气并实现语音播报
Python3爬虫之自动查询天气并实现语音播报本文向大家介绍Python3爬虫之自动查询天气并实现语音播报,包括了Python3爬虫之自动查询天气并实现语音播报的使用技巧和注意事项,需要的朋友参考一下 一、写在前面 之前写过一篇用Python发送天气预报邮件的博客,但是因为要手动输入城市名称,还要打开邮箱才能知道天气情况,这也太麻烦了。于是乎,有了这一篇博客,这次我要做的就是用Python获取本机IP地址,并根据这个IP地址获取物理位置也就是
-
详解nodejs爬虫程序解决gbk等中文编码问题
本文向大家介绍详解nodejs爬虫程序解决gbk等中文编码问题,包括了详解nodejs爬虫程序解决gbk等中文编码问题的使用技巧和注意事项,需要的朋友参考一下 使用nodejs写了一个爬虫的demo,目的是提取网页的title部分。 遇到最大的问题就是网页的编码与nodejs默认编码不一致造成的乱码问题。nodejs支持utf8, ucs2, ascii, binary, base64, hex等
-
基于C#实现网络爬虫 C#抓取网页Html源码
本文向大家介绍基于C#实现网络爬虫 C#抓取网页Html源码,包括了基于C#实现网络爬虫 C#抓取网页Html源码的使用技巧和注意事项,需要的朋友参考一下 最近刚完成一个简单的网络爬虫,开始的时候很迷茫,不知道如何入手,后来发现了很多的资料,不过真正能达到我需要,有用的资料--代码很难找。所以我想发这篇文章让一些要做这个功能的朋友少走一些弯路。 首先是抓取Html源码,并选择<ul class="
-
使用JAVA网络爬虫在MYSQL中存储印地语单词
我想在MySQL数据库中存储一些印地语单词。为此我写了一个网络爬虫。我能够从超文本标记语言页面成功读取这些单词并将它们显示在NetBeans控制台中。但是当我在MySQL中插入它们时,它们会变成???????。此外,如果我在PHPMyAdmin本身中使用SQL查询插入相同的单词,它们会被正确存储。 我搜索了很多谷歌和各种论坛,在大多数地方都采取了适当的预防措施来处理Unicode。如果输入Unic
-
python3.x - 爬虫:如何获得vn30指数构成公司的symbol?
"https://cn.investing.com/indices/hnx-30-components",这个网页包含了hnx30公司的构成,我只要爬取下来,用一个字典来容纳结果,键是公司名,值是一个链接,点击这个链接,可以跳转到公司名的网页,这个公司名对应的symbol就在里面。 下面我要做的是,获得每个公司的symbol,发现,居然无法用playwright,来模拟跳转,并获取跳转后的网页,请
-
python - 求解?爬取电影使用协程出现'任务已销毁,但仍处于挂起状态!'?
爬取某一部电影 于网上从学习 一步一步操作 没有出现代码错误 但还是出现 '任务已销毁,但仍处于挂起状态!' 在网上看了很多没有看到合适的解决方法 需要把所有的 任务下载完毕 而不是跳过该任务 源代码 出现的错误是
-
 Python3网络爬虫之使用User Agent和代理IP隐藏身份
Python3网络爬虫之使用User Agent和代理IP隐藏身份本文向大家介绍Python3网络爬虫之使用User Agent和代理IP隐藏身份,包括了Python3网络爬虫之使用User Agent和代理IP隐藏身份的使用技巧和注意事项,需要的朋友参考一下 本文介绍了Python3网络爬虫之使用User Agent和代理IP隐藏身份,分享给大家,具体如下: 运行平台:Windows Python版本:Python3.x IDE:Sublime text3 一
-
网络爬虫是否读取WEB-INF文件夹内的JSP页面
我有一个使用jsp页面的网络应用程序。我故意没有把jsp页面放在WEB-INF文件夹中,因为jsp中只有最少的代码,而且因为当时(大约5年前)我读到网络爬虫找不到WEB-INF文件夹中的文件。因此影响了我的搜索引擎优化/排名/搜索引擎搜索结果。 我还将jsp文件的位置放在网站地图中。xml文件。我使用的是tomcat,该网站完全公开,没有登录/安全要求。 所以,快进到现在。我的网站排名不错,搜索结