《python爬虫》专题
-
 详解python3 + Scrapy爬虫学习之创建项目
详解python3 + Scrapy爬虫学习之创建项目本文向大家介绍详解python3 + Scrapy爬虫学习之创建项目,包括了详解python3 + Scrapy爬虫学习之创建项目的使用技巧和注意事项,需要的朋友参考一下 最近准备做一个关于scrapy框架的实战,爬取腾讯社招信息并存储,这篇博客记录一下创建项目的步骤 pycharm是无法创建一个scrapy项目的 因此,我们需要用命令行的方法新建一个scrapy项目 请确保已经安装了scrapy
-
 Java爬虫抓取视频网站下载链接
Java爬虫抓取视频网站下载链接本文向大家介绍Java爬虫抓取视频网站下载链接,包括了Java爬虫抓取视频网站下载链接的使用技巧和注意事项,需要的朋友参考一下 本篇文章抓取目标网站的链接的基础上,进一步提高难度,抓取目标页面上我们所需要的内容并保存在数据库中。这里的测试案例选用了一个我常用的电影下载网站(http://www.80s.la/)。本来是想抓取网站上的所有电影的下载链接,后来感觉需要的时间太长,因此改成了抓取2015
-
nginx修改配置限制恶意爬虫频率
本文向大家介绍nginx修改配置限制恶意爬虫频率,包括了nginx修改配置限制恶意爬虫频率的使用技巧和注意事项,需要的朋友参考一下 如何在nginx中限制恶意网络爬虫抓取内容呢?也就是限制下恶意爬虫的抓取频率。下面来一起看看。 今天在微博发现@金荣叶 的处理方法很灵活,可以动态设定一个爬虫的频率,达到减轻服务器负载,并且不至于封杀爬虫。 超过设置的限定频率,就会给spider一个503。 总结 以
-
node.js实现博客小爬虫的实例代码
本文向大家介绍node.js实现博客小爬虫的实例代码,包括了node.js实现博客小爬虫的实例代码的使用技巧和注意事项,需要的朋友参考一下 前言 爬虫,是一种自动获取网页内容的程序。是搜索引擎的重要组成部分,因此搜索引擎优化很大程度上就是针对爬虫而做出的优化。 这篇文章介绍的是利用node.js实现博客小爬虫,核心的注释我都标注好了,可以自行理解,只需修改url和按照要趴的博客内部dom构造改一下
-
java实现简单的爬虫之今日头条
本文向大家介绍java实现简单的爬虫之今日头条,包括了java实现简单的爬虫之今日头条的使用技巧和注意事项,需要的朋友参考一下 前言 需要提前说下的是,由于今日头条的文章的特殊性,所以无法直接获取文章的地址,需要获取文章的id然后在拼接成url再访问。下面话不多说了,直接上代码。 示例代码如下 总结 以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可
-
Java中的网络爬虫。下载网页问题
我正在尝试开发一个小的网络爬虫,它下载网页并搜索特定部分的链接。但当我运行这段代码时,“href”标记中的链接会变短。如: 原文链接:“/kids-toys-action-figures-accessories/b/ref=toys_hp_catblock_actnfig?ie=utf8&node=165993011&pf_rd_m=atvpdkikx0der&pf_rd_s=merchandis
-
scrapy 爬虫抓取网页写入 mysql 数据库
安装MySQL-python [root@centos7vm ~]# pip install MySQL-python 执行如下不报错说明安装成功: [root@centos7vm ~]# python Python 2.7.5 (default, Nov 20 2015, 02:00:19) [GCC 4.8.5 20150623 (Red Hat 4.8.5-4)] on linux2 T
-
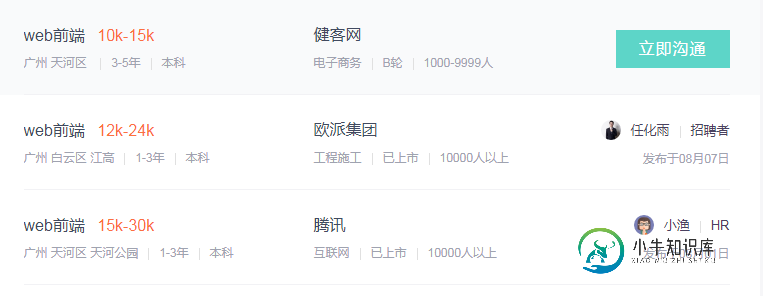 NodeJs实现简单的爬虫功能案例分析
NodeJs实现简单的爬虫功能案例分析本文向大家介绍NodeJs实现简单的爬虫功能案例分析,包括了NodeJs实现简单的爬虫功能案例分析的使用技巧和注意事项,需要的朋友参考一下 1.爬虫:爬虫,是一种按照一定的规则,自动地抓取网页信息的程序或者脚本;利用NodeJS实现一个简单的爬虫案例,爬取Boss直聘网站的web前端相关的招聘信息,以广州地区为例; 2.脚本所用到的nodejs模块 express 用来搭建一个服务,将结果
-
用爬虫找出哪个div包含“主要内容”
所以...我们如何确定哪个是页面的“主div”? 我很确定谷歌会这么做。他们肯定知道元素在页面上的位置,例如,如果某些东西位于“主要内容”或页脚中。他们怎么会知道这些? 我可以看到的在大范围内做到这一点的方法是: 编辑:我想一种渲染它的方法是不渲染每一个单独的页面。而是呈现域。例如。如果域结构是http://example.com/post/1-post-name/,我可以保存它的一个呈现,下次我
-
如何优雅地使用c语言编写爬虫
本文向大家介绍如何优雅地使用c语言编写爬虫,包括了如何优雅地使用c语言编写爬虫的使用技巧和注意事项,需要的朋友参考一下 大家在平时或多或少地都会有编写网络爬虫的需求。一般来说,编写爬虫的首选自然非python莫属,除此之外,java等语言也是不错的选择。选择上述语言的原因不仅仅在于它们均有非常不错的网络请求库和字符串处理库,还在于基于上述语言的爬虫框架非常之多和完善。良好的爬虫框架可以确保爬虫程序
-
 python3 Scrapy爬虫框架ip代理配置的方法
python3 Scrapy爬虫框架ip代理配置的方法本文向大家介绍python3 Scrapy爬虫框架ip代理配置的方法,包括了python3 Scrapy爬虫框架ip代理配置的方法的使用技巧和注意事项,需要的朋友参考一下 什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍。所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板。
-
从零学习node.js之简易的网络爬虫(四)
本文向大家介绍从零学习node.js之简易的网络爬虫(四),包括了从零学习node.js之简易的网络爬虫(四)的使用技巧和注意事项,需要的朋友参考一下 前言 之前已经介绍了node.js的一些基本知识,下面这篇文章我们的目标是学习完本节课程后,能进行网页简单的分析与抓取,对抓取到的信息进行输出和文本保存。 爬虫的思路很简单: 确定要抓取的URL; 对URL进行抓取,获取网页内容; 对内容进行分析并
-
 Java爬虫Jsoup+httpclient获取动态生成的数据
Java爬虫Jsoup+httpclient获取动态生成的数据本文向大家介绍Java爬虫Jsoup+httpclient获取动态生成的数据,包括了Java爬虫Jsoup+httpclient获取动态生成的数据的使用技巧和注意事项,需要的朋友参考一下 Java爬虫Jsoup+httpclient获取动态生成的数据 前面我们详细讲了一下Jsoup发现这玩意其实也就那样,只要是可以访问到的静态资源页面都可以直接用他来获取你所需要的数据,详情情跳转-Jsoup爬虫详
-
PythonValueError:太多的值无法为爬虫程序解包
我试图运行我在网上找到的刮板,但收到一个ValueError:太多的值在这行代码上解包 这条线是这个函数的一部分 如果您有任何意见,我们将不胜感激,谢谢。
-
Scrapy爬虫提取URL,但错过了一半回调
我在尝试刮取此URL时遇到了一个奇怪的问题: 为了执行爬行,我设计了这个: 我从命令行启动spider,我可以看到URL通常被删除,但是,对于其中一些URL,回调不起作用(大约一半的URL通常被删除)。 由于此页面上有150多个链接,这可能解释了爬虫程序缺少回调(太多作业)的原因。你们中的一些人对此有什么想法吗? 这是日志: 2015-12-25 09:02:55[scrapy]信息:存储在中的c