《python爬虫》专题
-
T-SQL Puzzler-爬行对象依赖项
问题内容: 此代码涉及一个递归存储过程调用和一种避免游标名称冲突的“不太好”的方法。最后,我不在乎它是否使用游标。只是在寻找最优雅的方法。我主要将其用作跟踪Stored Proc层次结构的简单方法(无需购买产品)。我在“动态sql”中尝试了游标,但运气不佳。我想深入十个层次。 所需的输出: 它不是很漂亮,但是这里是代码(它没有按预期工作) 问题答案: 对于ms sql服务器,您可以使用CURSOR
-
谷歌爬网503服务不可用
当我在我的服务器上用wget、curl或python爬行谷歌搜索引擎时,我遇到了一个非常奇怪的问题。Google将我重定向到以[ipv4 | ipv6]开头的地址。谷歌。fr/抱歉/索引重定向。。。最后发送503错误,服务不可用。。。 有时抓取工作正常,有时不是在白天,我尝试了几乎所有可能的方法:强制ipv4/ipv6而不是主机名、引用者、用户代理、vpn、. com/. fr/、代理和tor,.
-
如何解决段:爬网/段/*错误
在点击此链接时,我收到此错误,但无法弄清楚它 http://wiki.apache.org/nutch/NutchTutorial runtime/local$bin/nutch parse$s1 ParseSegment:开始于2013-10-11 17:43:36 ParseSemment:segment:craw/segments/20131011173126线程“main”java.io.
-
执行爬网时出现Nutch问题
我正在尝试让nutch 1.11执行爬网。我正在使用cygwin在windows 7中运行这些命令。 Nutch正在运行,运行bin/Nutch会得到结果,但当我尝试运行爬网时,会不断收到错误消息。 当我尝试使用 nutch 运行爬网执行时,我收到以下错误: 运行时出错:/cygdrive/c/Users/User5/Documents/Nutch/apache-Nutch-1.11/runtim
-
26. 使用web展示爬取信息
26.1 创建项目myweb和应用web # 创建项目框架myweb $ django-admin startproject myweb $ cd myweb # 在项目中创建一个web应用 $ python3 manage.py startapp web # 创建模板目录 $ mkdir templates $ mkdir t
-
12. POST请求爬取数据实战
import json json.loads(json_str) # json字符串转换成字典 json.dumps(dict) # 字典转换成json字符串 使用urllib发送POST数据,并抓取百度翻译信息 from urllib import request,parse import json url = 'http://fanyi.baidu.com/sug' # 定义
-
11. GET请求爬取数据实战
使用urllib的GET获取58同城中关于python的招聘信息 from urllib import request from urllib import error import re url = "http://bj.58.com/job/?key=python&final=1&jump=1" req = request.Request(url) try: response = r
-
第十五章 爬取维基百科
在本章中,我展示了上一个练习的解决方案,并分析了 Web 索引算法的性能。然后我们构建一个简单的 Web 爬虫。 15.1 基于 Redis 的索引器 在我的解决方案中,我们在 Redis 中存储两种结构: 对于每个检索词,我们有一个URLSet,它是一个 Redis 集合,包含检索词的 URL。 对于每个网址,我们有一个TermCounter,这是一个 Redis 哈希表,将每个检索词映射到它出
-
python - 为什么scapy爬虫用管道持久化存储时创建的文件一直为空写不进去?
最近在学习scrapy爬虫的用管道持久化存储时,遇到了这个问题,只知道这个创建的fp一直为none 接下来分别是item.py的 这个是pipelines.py: 以下是我的报错: 真的找了很久的问题了,像是那种重写父类方法的问题我也比对过感觉自己重写的方式是正确的,还有就是setting文件中pipelines也有手动打开,但是始终不知道自己创建的这个fp为什么是None,一直无法写入,连txt
-
 使用python itchat包爬取微信好友头像形成矩形头像集的方法
使用python itchat包爬取微信好友头像形成矩形头像集的方法本文向大家介绍使用python itchat包爬取微信好友头像形成矩形头像集的方法,包括了使用python itchat包爬取微信好友头像形成矩形头像集的方法的使用技巧和注意事项,需要的朋友参考一下 初学python,我们必须干点有意思的事!从微信下手吧! 头像集样例如下: 大家可以发朋友圈开启辨认大赛哈哈~ 话不多说,直接上代码,注释我写了比较多,大家应该能看懂 运行结果: ok!!! 以上这篇
-
 java网络爬虫连接超时解决实例代码
java网络爬虫连接超时解决实例代码本文向大家介绍java网络爬虫连接超时解决实例代码,包括了java网络爬虫连接超时解决实例代码的使用技巧和注意事项,需要的朋友参考一下 本文研究的主要是java网络爬虫连接超时的问题,具体如下。 在网络爬虫中,经常会遇到如下报错。即连接超时。针对此问题,一般解决思路为:将连接时间、请求时间设置长一下。如果出现连接超时的情况,则在重新请求【设置重新请求次数】。 下面的代码便是使用httpclient
-
 python3爬虫中多线程进行解锁操作实例
python3爬虫中多线程进行解锁操作实例本文向大家介绍python3爬虫中多线程进行解锁操作实例,包括了python3爬虫中多线程进行解锁操作实例的使用技巧和注意事项,需要的朋友参考一下 生活中我们为了保障房间里物品的安全,所以给门进行上锁,在我们需要进入房间的时候又会重新打开。同样的之间我们讲过多线程中的lock,作用是为了不让多个线程运行是出错所以进行锁住的指令。但是鉴于我们实际运用中,因为线程和指令不会只有一个,如果全部都进行lo
-
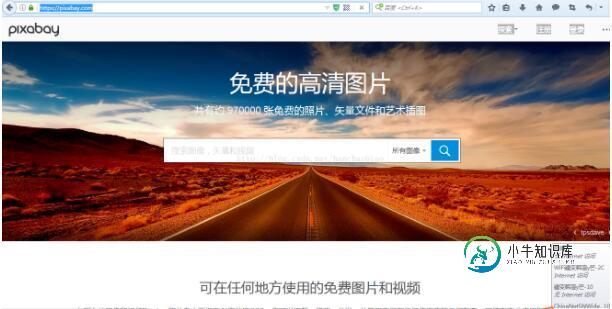 Python3.x爬虫下载网页图片的实例讲解
Python3.x爬虫下载网页图片的实例讲解本文向大家介绍Python3.x爬虫下载网页图片的实例讲解,包括了Python3.x爬虫下载网页图片的实例讲解的使用技巧和注意事项,需要的朋友参考一下 一、选取网址进行爬虫 本次我们选取pixabay图片网站 二、选择图片右键选择查看元素来寻找图片链接的规则 通过查看多个图片路径我们发现取src路径都含有 https://cdn.pixabay.com/photo/ 公共部分且图片格式都为.jpg
-
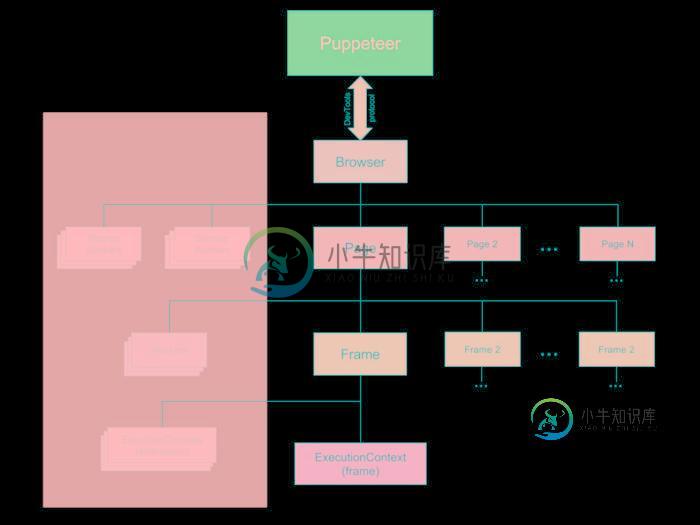 详解Node使用Puppeteer完成一次复杂的爬虫
详解Node使用Puppeteer完成一次复杂的爬虫本文向大家介绍详解Node使用Puppeteer完成一次复杂的爬虫,包括了详解Node使用Puppeteer完成一次复杂的爬虫的使用技巧和注意事项,需要的朋友参考一下 本文介绍了详解Node使用Puppeteer完成一次复杂的爬虫,分享给大家,具体如下: 架构图 Puppeteer架构图 Puppeteer 通过 devTools 与 browser 通信 Browser 一个可以拥有多个页面的浏
-
粘附爬行器以读取Json数组
我有一个Json数组文件的格式:-[[{key1:value1},{key2:value2},{key3:value3}],[{key1:value4},{key2:value5},{key3:value6}]] 我需要使用AWS glue爬取上述文件,并读取json模式,其中每个键都作为模式中的一列。我尝试使用标准的json分类器,但它似乎不起作用,并且模式加载为数组。我需要从S3读取json文