《python爬虫》专题
-
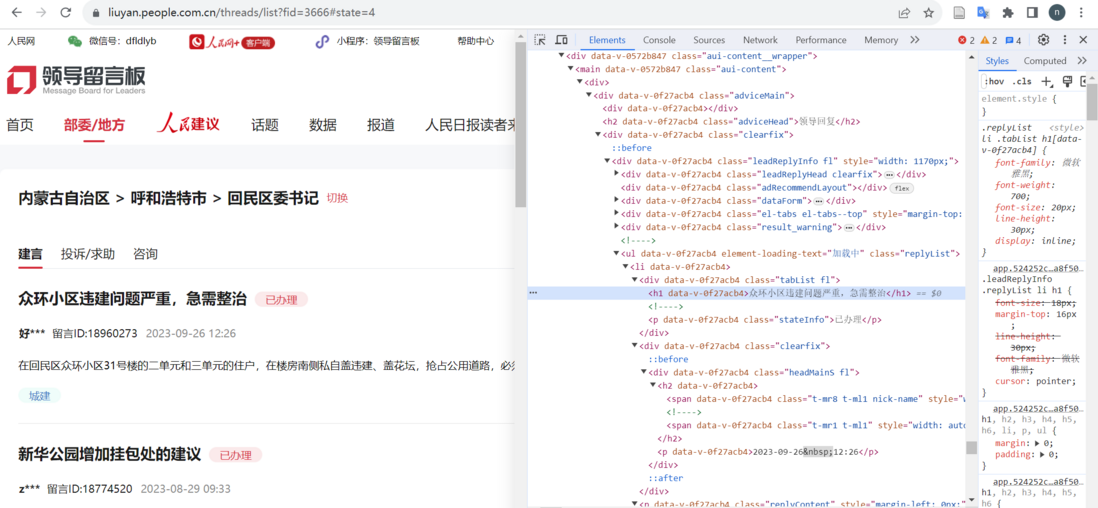 爬虫 - 为什么在F12中找不到网页中的超链接?
爬虫 - 为什么在F12中找不到网页中的超链接?如图,在爬人民网领导留言板数据时,这里每条留言都有一个超链接可以转到留言详情页,但在开发者工具中却找不到这个链接在哪里,查找tag_name为a的内容也没有找到,该怎么定位和提取超链接,求好心人帮助 网页链接为:https://liuyan.people.com.cn/threads/list?fid=3666 如图:
-
java代理实现爬取代理IP的示例
本文向大家介绍java代理实现爬取代理IP的示例,包括了java代理实现爬取代理IP的示例的使用技巧和注意事项,需要的朋友参考一下 仅仅使用了一个java文件,运行main方法即可,需要依赖的jar包是com.alibaba.fastjson(版本1.2.28)和Jsoup(版本1.10.2) 如果用了pom,那么就是以下两个: 完整的代码如下: 以上这篇java代理实现爬取代理IP的示例就是小编
-
5、常见的反爬手段和解决思路
1. 明确反反爬的主要思路 反反爬的主要思路就是:尽可能的去模拟浏览器,浏览器在如何操作,代码中就如何去实现。浏览器先请求了地址url1,保留了cookie在本地,之后请求地址url2,带上了之前的cookie,代码中也可以这样去实现。 很多时候,爬虫中携带的headers字段,cookie字段,url参数,post的参数很多,不清楚哪些有用,哪些没用的情况下,只能够去尝试,因为每个网站都是不相同
-
微信 Android 视频编码爬过的那些坑
Android的视频相关的开发,大概一直是整个Android生态,以及Android API中,最为分裂以及兼容性问题最为突出的一部分。摄像头,以及视频编码相关的API,Google一直对这方面的控制力非常差,导致不同厂商对这两个API的实现有不少差异,而且从API的设计来看,一直以来优化也相当有限,甚至有人认为这是“Android上最难用的API之一” 以微信为例,我们录制一个540p的mp4文
-
程序员 - scrapy 爬虫,始终获取不到数据,如何解决呢?
求助 scrapy 爬取数据失败,排查了好久都没有找到问题了,实在找不到了 目标:爬取欣欣旅游网的某一城市 各大景点的基本信息 这是我的 sipder 以及 item 代码 spider: item: 这是执行日志: 跟着老师讲的一步一步来的,自己多爬取了几个信息(打开对应的详细网页进行爬取) 始终获取不到任何信息,301重定向错误也试了很多方法,但都没有解决 救救我吧 大佬们
-
 php实现爬取和分析知乎用户数据
php实现爬取和分析知乎用户数据本文向大家介绍php实现爬取和分析知乎用户数据,包括了php实现爬取和分析知乎用户数据的使用技巧和注意事项,需要的朋友参考一下 背景说明:小拽利用php的curl写的爬虫,实验性的爬取了知乎5w用户的基本信息;同时,针对爬取的数据,进行了简单的分析呈现。 php的spider代码和用户dashboard的展现代码,整理后上传github,在个人博客和公众号更新代码库,程序仅供娱乐和学习交流;如果有
-
 SpringBoot中使用Jsoup爬取网站数据的方法
SpringBoot中使用Jsoup爬取网站数据的方法本文向大家介绍SpringBoot中使用Jsoup爬取网站数据的方法,包括了SpringBoot中使用Jsoup爬取网站数据的方法的使用技巧和注意事项,需要的朋友参考一下 爬取数据 导入jar包 新建实体类 编写爬虫工具类 可以看到内容、图片、价格系数爬取 到此这篇关于SpringBoot中使用Jsoup爬取网站数据的方法的文章就介绍到这了,更多相关SpringBoot Jsoup爬取内容请搜索呐
-
 scrapy利用selenium爬取豆瓣阅读的全步骤
scrapy利用selenium爬取豆瓣阅读的全步骤本文向大家介绍scrapy利用selenium爬取豆瓣阅读的全步骤,包括了scrapy利用selenium爬取豆瓣阅读的全步骤的使用技巧和注意事项,需要的朋友参考一下 首先创建scrapy项目 命令:scrapy startproject douban_read 创建spider 命令:scrapy genspider douban_spider url 网址:https://read.douba
-
在Scrapy中爬行经过身份验证的会话
问题内容: 我对问题不是很具体(希望通过与Scrapy进行身份验证的会话进行抓取),希望能够从更笼统的答案中得出解决方案。我应该宁可使用这个词。 所以,这是到目前为止的代码: 如你所见,我访问的第一页是登录页面。如果尚未通过身份验证(在函数中),则调用自定义函数,该函数将发布到登录表单中。然后,如果我我验证,我想继续爬行。 问题是我尝试覆盖以登录的功能,现在不再进行必要的调用以刮擦任何其他页面(我
-
 如何爬取通过ajax加载数据的网站
如何爬取通过ajax加载数据的网站本文向大家介绍如何爬取通过ajax加载数据的网站,包括了如何爬取通过ajax加载数据的网站的使用技巧和注意事项,需要的朋友参考一下 目前很多网站都使用ajax技术动态加载数据,和常规的网站不一样,数据时动态加载的,如果我们使用常规的方法爬取网页,得到的只是一堆html代码,没有任何的数据。 请看下面的代码: 上面的代码是爬取今日头条的一个网页,并打印出get方法返回的文本内容如下图所示,值现在一堆
-
python2使用bs4爬取腾讯社招过程解析
本文向大家介绍python2使用bs4爬取腾讯社招过程解析,包括了python2使用bs4爬取腾讯社招过程解析的使用技巧和注意事项,需要的朋友参考一下 目的:获取腾讯社招这个页面的职位名称及超链接 职位类别 人数 地点和发布时间 要求:使用bs4进行解析,并把结果以json文件形式存储 注意:如果直接把python列表没有序列化为json数组,写入到json文件,会产生中文写不进去到文件,所以要序
-
浅谈js数组splice删除某个元素爬坑
本文向大家介绍浅谈js数组splice删除某个元素爬坑,包括了浅谈js数组splice删除某个元素爬坑的使用技巧和注意事项,需要的朋友参考一下 先来看下几个概念: 本次就拿删除举例,本身我们想删除数组中的某个指定元素,我们需要知道它所在数组中的下标,我们可以用 数组.indexOf获取它所在的下标,然后拿splice删除这个元素。 本身是没问题 代码如下: 但是。。。。。问题就来了。 如果放到fo
-
刮。开始爬行后如何更改蜘蛛设置?
我无法更改分析方法中的爬行器设置。但这肯定是一种方式。 例如: 但是项目将由FirstPipeline处理。新项目参数不工作。开始爬网后如何更改设置?提前谢谢!
-
使用Solr Nutch对特定数据进行Web爬网
我看到了一些像http://homes.mitula.ph/homes/makati这样的搜索网站,我想知道他们是如何抓取其他网站(如、和)中的数据并将其显示到他们的站点上的。 我正在考虑使用Solr索引数据,使用Nutch抓取数据。我是一个新的网页抓取和索引,目前为止,我只能抓取一个网页的内容。 Solr Nutch能做那种爬行吗?怎么做的?
-
在多个solr索引之间共享爬网nutch数据
我们有数以千计的solr索引/集合共享Nutch抓取的页面。 感谢任何想法或帮助:)