《python爬虫》专题
-
scrapy实践之翻页爬取的实现
本文向大家介绍scrapy实践之翻页爬取的实现,包括了scrapy实践之翻页爬取的实现的使用技巧和注意事项,需要的朋友参考一下 安装 Scrapy的安装很简单,官方文档也有详细的说明 http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/install.html 。这里不详细说明了。 在scrapy框架中,spider具有以下几个功能 1. 定义初始爬
-
易语言爬取网页内容方法
本文向大家介绍易语言爬取网页内容方法,包括了易语言爬取网页内容方法的使用技巧和注意事项,需要的朋友参考一下 写个辅助工具的时候需要提取网页里面的某些内容,我这里便把方法告诉大家,希望对大家有所帮助,记得投票给我哦! 1、在新建的windos窗口程序中画: 两个编辑框、一个按钮。 再添加模块如图中三步! 我们来实现,在一个编辑框中输入网址后,点击按钮,然后取到指定内容到编辑框2中。 2、比如我们来取
-
想知道如何在tripadvisor上爬行吗
我正在尝试获取新加坡餐馆的所有url链接,但我的代码不起作用 它在代码 我不知道为什么会发生这种情况,即使这对其他网站很有效。 这是因为行车顾问程序块爬行还是代码错误?
-
21. 从API爬取天气预报数据
21.1 注册免费API和阅读文档 本节通过一个API接口(和风天气预报)爬取天气信息,该接口为个人开发者提供了一个免费的预报数据(有次数限制)。 首先访问和风天气网,注册一个账户。注册地址:https://console.heweather.com/ 在登陆后的控制台中可以看到个人认证的key(密钥),这个key就是访问API接口的钥匙。 获取key之后阅读API文档:https://www.h
-
14. 使用代理爬取信息实战
14.1 实战目标: 本节目标是利用代理爬取微信公众号的文章信息,从中提取标题、摘要、发布日期、公众号以及url地址等内容。 本节爬取的是搜索关键字为python的,类别为微信的所有文章信息,并将信息存储到MongoDB中。 URL地址:http://weixin.sogou.com/weixin?type=2&query=python&ie=utf8&s_from=input 14.2 准备工作
-
“围棋之旅”网络爬虫练习中的频道说明
问题内容: 我正在经历“ A Go of Go”,并且一直在编辑大多数课程,以确保我完全理解它们。我对以下练习的答案有疑问: https : //tour.golang.org/concurrency/10,可在此处找到: https //github.com/golang/tour/blob/master/solutions/ webcrawler.go 我对以下部分有疑问: 从通道添加和删除t
-
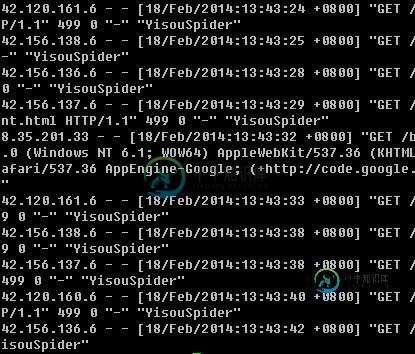 Nginx中配置过滤爬虫的User-Agent的简单方法
Nginx中配置过滤爬虫的User-Agent的简单方法本文向大家介绍Nginx中配置过滤爬虫的User-Agent的简单方法,包括了Nginx中配置过滤爬虫的User-Agent的简单方法的使用技巧和注意事项,需要的朋友参考一下 过去写博客的时候经常出现服务器宕机,网页全部刷不出来,但是Ping服务器的时候又能Ping通。登录SSH看了下top,惊呆了,平均负载13 12 8。瞬间觉得我这是被人DDOS了么?看了下进程基本上都是php-fpm把CPU
-
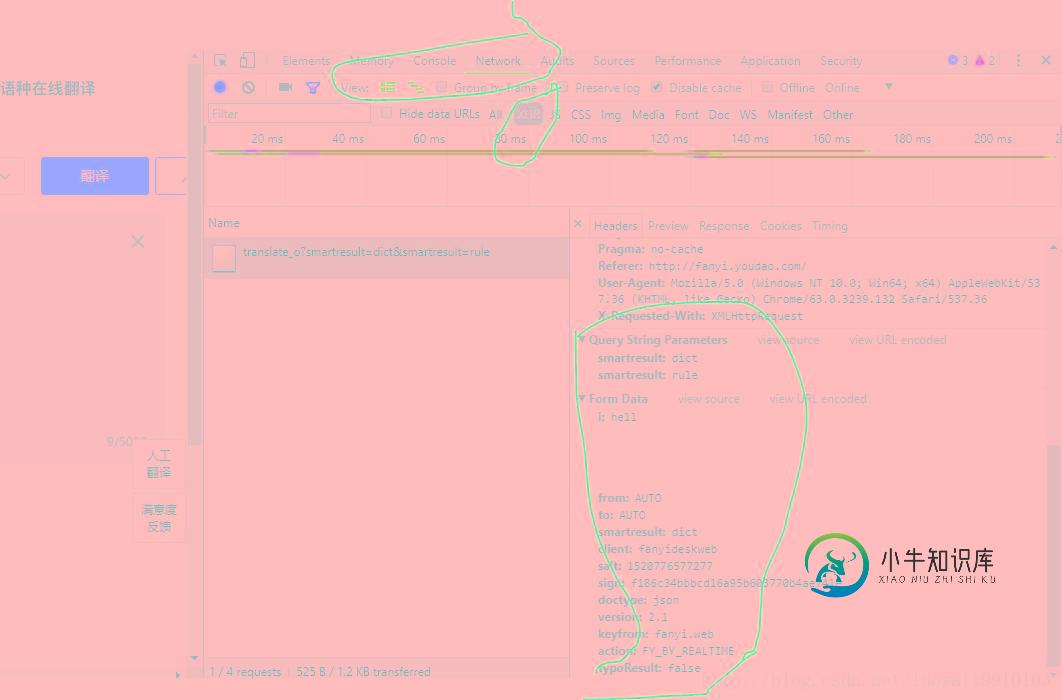 用python3 urllib破解有道翻译反爬虫机制详解
用python3 urllib破解有道翻译反爬虫机制详解本文向大家介绍用python3 urllib破解有道翻译反爬虫机制详解,包括了用python3 urllib破解有道翻译反爬虫机制详解的使用技巧和注意事项,需要的朋友参考一下 前言 最近在学习python 爬虫方面的知识,网上有一博客专栏专门写爬虫方面的,看到用urllib请求有道翻译接口获取翻译结果。发现接口变化很大,用md5加了密,于是自己开始破解。加上网上的其他文章找源码方式并不是通用的,所
-
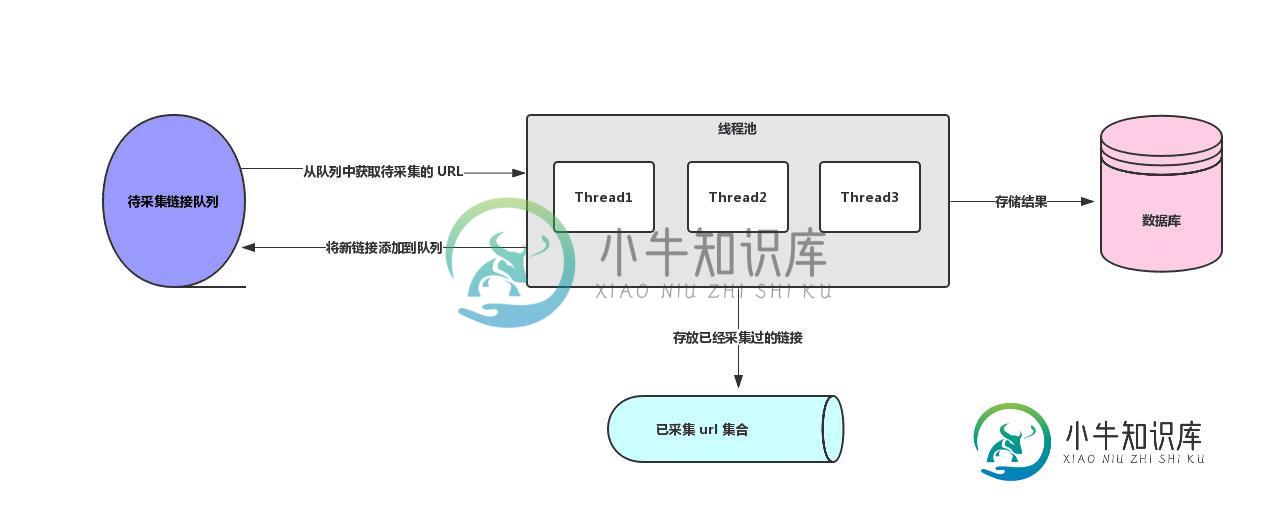 Java多线程及分布式爬虫架构原理解析
Java多线程及分布式爬虫架构原理解析本文向大家介绍Java多线程及分布式爬虫架构原理解析,包括了Java多线程及分布式爬虫架构原理解析的使用技巧和注意事项,需要的朋友参考一下 这是 Java 爬虫系列博文的第五篇,在上一篇Java 爬虫服务器被屏蔽的解决方案中,我们简单的聊反爬虫策略和反反爬虫方法,主要针对的是 IP 被封及其对应办法。前面几篇文章我们把爬虫相关的基本知识都讲的差不多啦。这一篇我们来聊一聊爬虫架构相关的内容。 前面几
-
 Android利用爬虫实现模拟登录的实现实例
Android利用爬虫实现模拟登录的实现实例本文向大家介绍Android利用爬虫实现模拟登录的实现实例,包括了Android利用爬虫实现模拟登录的实现实例的使用技巧和注意事项,需要的朋友参考一下 Android利用爬虫实现模拟登录的实现实例 为了用手机登录校网时不用一遍一遍的输入账号密码,于是决定用爬虫抓取学校登录界面,然后模拟填写本次保存的账号、密码,模拟点击登录按钮。实现过程折腾好几个。 一开始选择的是htmlunit解析登录界面htm
-
详解Selenium-webdriver绕开反爬虫机制的4种方法
本文向大家介绍详解Selenium-webdriver绕开反爬虫机制的4种方法,包括了详解Selenium-webdriver绕开反爬虫机制的4种方法的使用技巧和注意事项,需要的朋友参考一下 之前爬美团外卖后台的时候出现的问题,各种方式拖动验证码都无法成功,包括直接控制拉动,模拟人工轨迹的随机拖动都失败了,最后发现只要用chrome driver打开页面,哪怕手动登录也不可以,猜测driver肯定
-
java - 做爬虫时如何提取网站登录后的cookie?
我知道可以通过F12查看,我现在的需求是要完整的请求头的cookie内容,因为我需要放到爬虫的Jsoup的connection的head里, 有什么好的获取cookie的方法吗?我总不可能手动输入一个一个的键值对吧?
-
如何使用 LLM 来做爬虫的页面通用解析?
现在遇到的问题是 html 往往很大,甚至可以说体积是超级超级大,几百KB甚至几MB 但是 LLM 的上下文比较小,输入的 html 这么大,非常的糟糕 但是又不能去除掉所有的 html 标签,因为这样就是失去了原始信息了,怎么有选择性的把有效且精简的数据输入给 llm 呢?
-
通过抓取淘宝评论为例讲解Python爬取ajax动态生成的数据(经典)
本文向大家介绍通过抓取淘宝评论为例讲解Python爬取ajax动态生成的数据(经典),包括了通过抓取淘宝评论为例讲解Python爬取ajax动态生成的数据(经典)的使用技巧和注意事项,需要的朋友参考一下 在学习python的时候,一定会遇到网站内容是通过 ajax动态请求、异步刷新生成的json数据 的情况,并且通过python使用之前爬取静态网页内容的方式是不可以实现的,所以这篇文章将要讲述如果
-
php爬取天猫和淘宝商品数据
本文向大家介绍php爬取天猫和淘宝商品数据,包括了php爬取天猫和淘宝商品数据的使用技巧和注意事项,需要的朋友参考一下 一、思路 最近做了一个网站用到了从网址爬取天猫和淘宝的商品信息,首先看了下手机端的网页发现用的react,不太了解没法搞,所以就考虑从PC入口爬取数据,但是当爬取URL获取数据时并没有获取价格,库存等的信息,仔细研究了下发现是异步请求了另一个接口,但是接口要使用refer才能获取