《python爬虫》专题
-
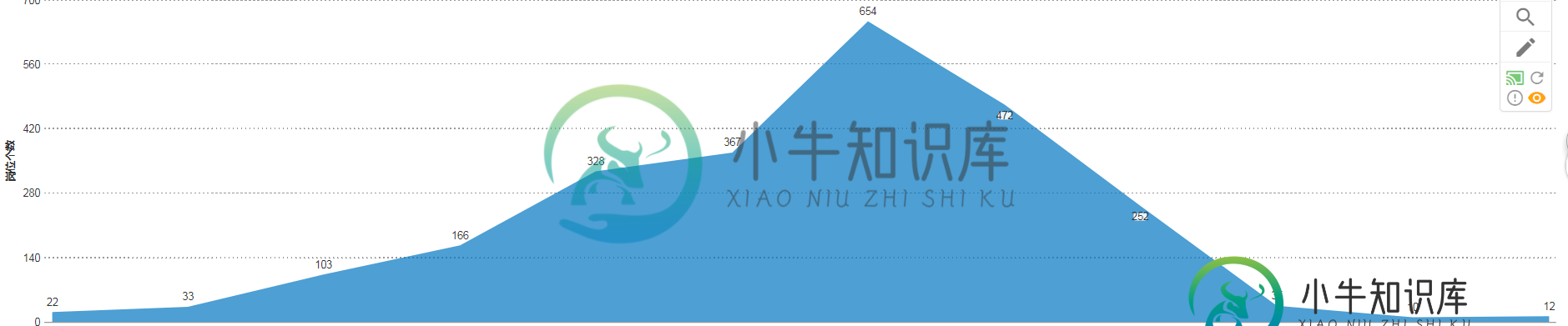 JAVA超级简单的爬虫实例讲解
JAVA超级简单的爬虫实例讲解本文向大家介绍JAVA超级简单的爬虫实例讲解,包括了JAVA超级简单的爬虫实例讲解的使用技巧和注意事项,需要的朋友参考一下 爬取整个页面的数据,并进行有效的提取信息,注释都有就不废话了: 上一张自己爬取的图片,并用fusioncharts生成报表(一般抓取的是int类型的数据的话,生成报表可以很直观) 以上这篇JAVA超级简单的爬虫实例讲解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希
-
 宇润爬虫框架 Yurun Crawler 帮助文档
宇润爬虫框架 Yurun Crawler 帮助文档宇润爬虫框架 Yurun Crawler 是一个低代码、高性能、分布式爬虫采集框架,基于 imi 框架开发,运行在 Swoole 常驻内存的协程环境。
-
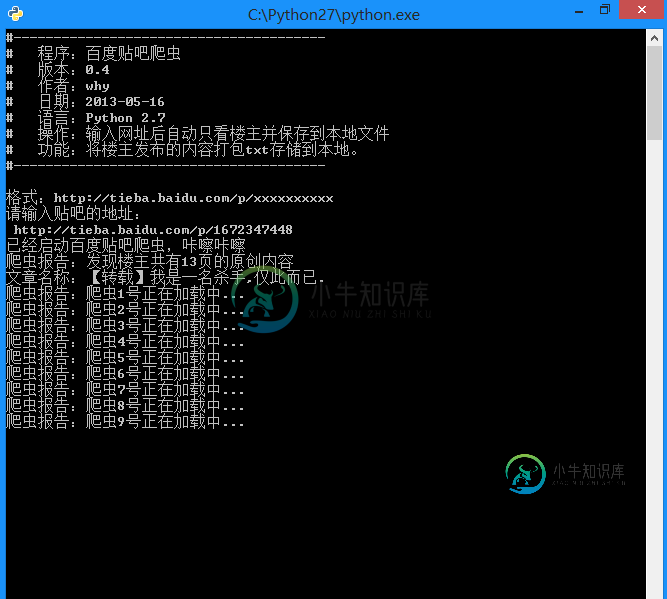 零基础写python爬虫之抓取百度贴吧并存储到本地txt文件改进版
零基础写python爬虫之抓取百度贴吧并存储到本地txt文件改进版本文向大家介绍零基础写python爬虫之抓取百度贴吧并存储到本地txt文件改进版,包括了零基础写python爬虫之抓取百度贴吧并存储到本地txt文件改进版的使用技巧和注意事项,需要的朋友参考一下 百度贴吧的爬虫制作和糗百的爬虫制作原理基本相同,都是通过查看源码扣出关键数据,然后将其存储到本地txt文件。 项目内容: 用Python写的百度贴吧的网络爬虫。 使用方法: 新建一个BugBaidu.py
-
python中requests爬去网页内容出现乱码问题解决方法介绍
本文向大家介绍python中requests爬去网页内容出现乱码问题解决方法介绍,包括了python中requests爬去网页内容出现乱码问题解决方法介绍的使用技巧和注意事项,需要的朋友参考一下 最近在学习python爬虫,使用requests的时候遇到了不少的问题,比如说在requests中如何使用cookies进行登录验证,这可以查看这篇文章。这篇博客要解决的问题是如何避免在使用request
-
在Jmeter的线程组中爬升
我对在JMeter中设置斜坡有异议。 下面描述了我的测试场景。 null
-
使角度爬网-项目开始
问题内容: 使用angularJS开发网站时,在开始使用网站之前,您是否需要担心Web爬网程序,还是可以将其推迟到网站完成。 例如,我读过HTML快照是一个很好的解决方案。如果选择执行此操作,则可以在对网站进行编码后实现它,还是必须基于这种功能来创建网站。 问题答案: 我认为在项目开始时考虑该策略并在项目结束时实施该策略是很好的。 我们在我正在工作的公司中遇到了问题。 在所有情况下,您都需要向GE
-
 详解Vue爬坑之vuex初识
详解Vue爬坑之vuex初识本文向大家介绍详解Vue爬坑之vuex初识,包括了详解Vue爬坑之vuex初识的使用技巧和注意事项,需要的朋友参考一下 在 Vue.js 的项目中,如果项目结构简单, 父子组件之间的数据传递可以使用 props 或者 $emit 等方式. 但是如果是大型项目,很多时候都需要在子组件之间传递数据,使用之前的方式就不太方便。Vue 的状态管理工具 Vuex 完美的解决了这个问题。 一、安装并引入
-
刮痕爬行蜘蛛不连接
我在这里和其他网站上读了很多关于scrapy的文章,但我无法解决这个问题,所以我问你:P希望有人能帮助我。 我想在主客户端页面中验证登录名,然后解析所有类别和所有产品,并保存产品的标题、类别、数量和价格。 我的代码: 当我在终端上运行scrapy爬行蜘蛛时,我得到以下信息: 刮痒的)pi@raspberry:~/SCRAPY/combatzone/combatzone/spiders$SCRAPY
-
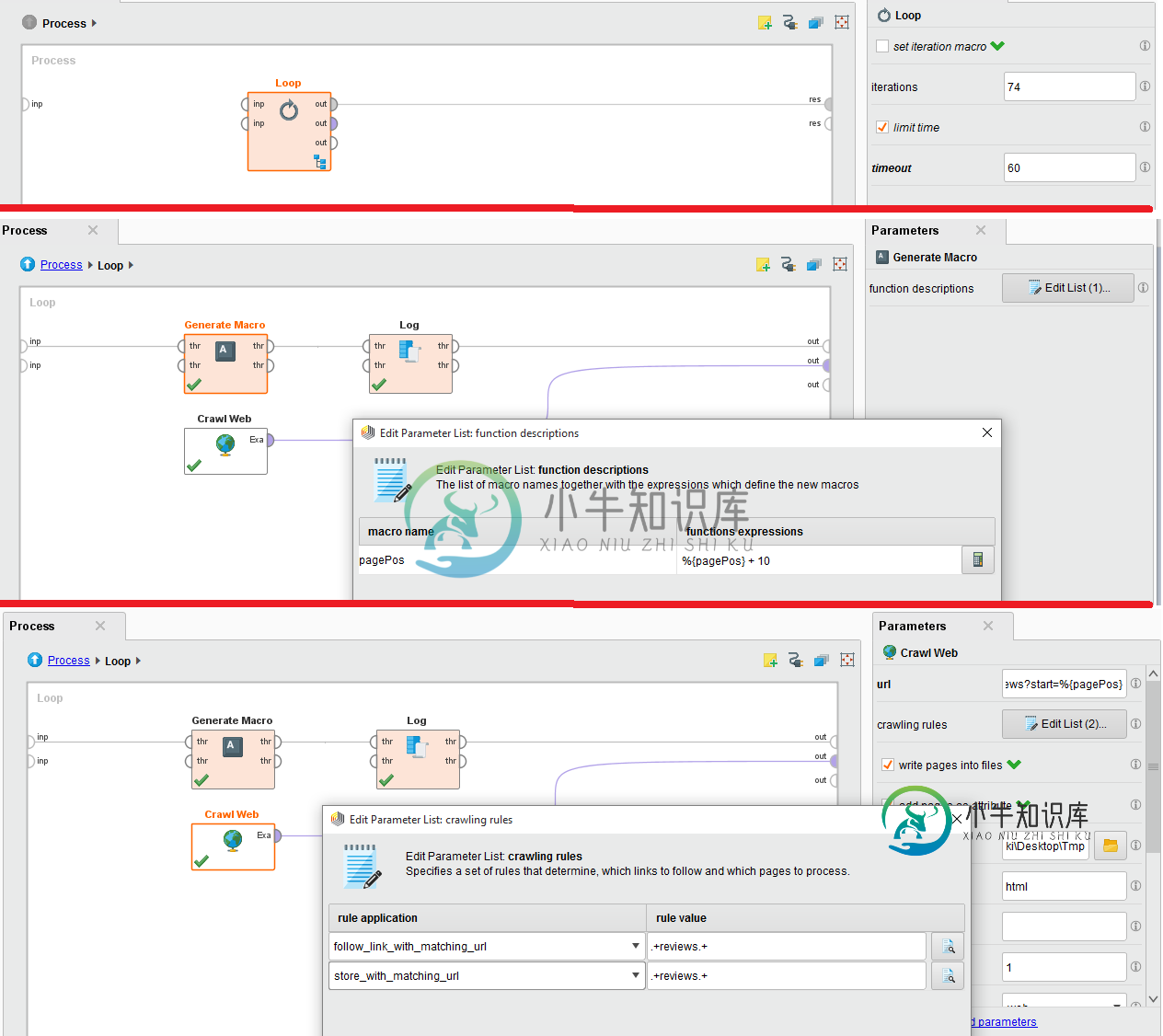 Rapid Miner不保存爬网结果
Rapid Miner不保存爬网结果我试图从IMDB网站抓取特定电影评论的评论。为此,我使用抓取网络,我有内嵌循环,因为有74个页面。 附件是配置的图像。请帮忙。我深陷其中。 爬网网站的URL为:http://www.imdb.com/title/tt0454876/reviews?start=%{pagePos}
-
16. 图片信息爬取实战
案例分析 任务:爬取京东指定商品图片信息,并存储在当期目录下。 url地址:https://list.jd.com/list.html?cat=9987,653,655 分析Web的响应内容,并作出对应处理准备: 具体实现代码: import requests from bs4 import BeautifulSoup from urllib.request import urlretrieve
-
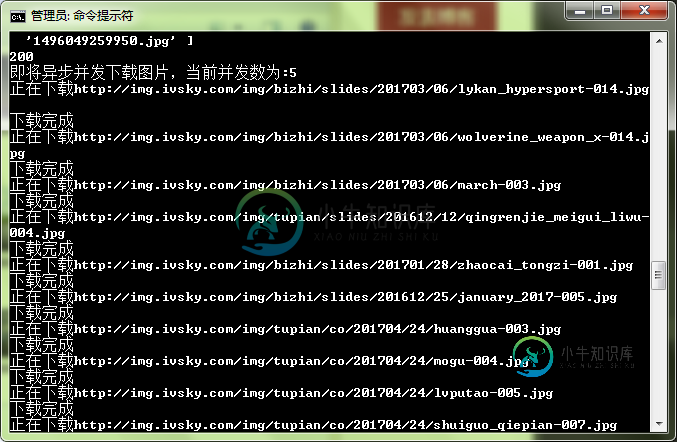 基于nodejs 的多页面爬虫实例代码
基于nodejs 的多页面爬虫实例代码本文向大家介绍基于nodejs 的多页面爬虫实例代码,包括了基于nodejs 的多页面爬虫实例代码的使用技巧和注意事项,需要的朋友参考一下 前言 前端时间再回顾了一下node.js,于是顺势做了一个爬虫来加深自己对node的理解。 主要用的到是request,cheerio,async三个模块 request 用于请求地址和快速下载图片流。 https://github.com/request/r
-
基于selenium-java封装chrome、firefox、phantomjs实现爬虫
本文向大家介绍基于selenium-java封装chrome、firefox、phantomjs实现爬虫,包括了基于selenium-java封装chrome、firefox、phantomjs实现爬虫的使用技巧和注意事项,需要的朋友参考一下 2017年一直以来在公司负责爬虫项目相关工程,主要业务有预定、库存、在开发中也遇到很多问题,随手记录一下,后续会持续更新。 chrome、firefox、p
-
 nodeJs爬虫获取数据简单实现代码
nodeJs爬虫获取数据简单实现代码本文向大家介绍nodeJs爬虫获取数据简单实现代码,包括了nodeJs爬虫获取数据简单实现代码的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了nodeJs爬虫获取数据代码,供大家参考,具体内容如下 效果图: 以上就是nodeJs爬虫获取数据的相关代码,希望对大家的学习有所帮助。
-
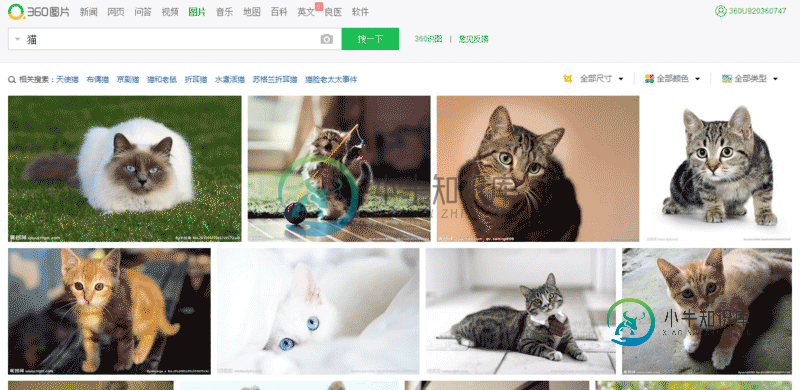 nodejs制作爬虫实现批量下载图片
nodejs制作爬虫实现批量下载图片本文向大家介绍nodejs制作爬虫实现批量下载图片,包括了nodejs制作爬虫实现批量下载图片的使用技巧和注意事项,需要的朋友参考一下 今天想获取一大批猫的图片,然后就在360流浪器搜索框中输入 猫 ,然后点击图片。就看到了一大波猫的图片: http://image.so.com/i?q=%E7%8... ,我在想啊,要是审查元素,一张张手动下载,多麻烦,所以打算写程序来实现。不写不知道,一写发现
-
Nodejs实现爬虫抓取数据实例解析
本文向大家介绍Nodejs实现爬虫抓取数据实例解析,包括了Nodejs实现爬虫抓取数据实例解析的使用技巧和注意事项,需要的朋友参考一下 开始之前请先确保自己安装了Node.js环境,如果没有安装,大家可以到呐喊教程下载安装。 1.在项目文件夹安装两个必须的依赖包 superagent 是一个轻量的,渐进式的ajax api,可读性好,学习曲线低,内部依赖nodejs原生的请求api,适用于node