《python爬虫》专题
-
 利用Python爬取微博数据生成词云图片实例代码
利用Python爬取微博数据生成词云图片实例代码本文向大家介绍利用Python爬取微博数据生成词云图片实例代码,包括了利用Python爬取微博数据生成词云图片实例代码的使用技巧和注意事项,需要的朋友参考一下 前言 在很早之前写过一篇怎么利用微博数据制作词云图片出来,之前的写得不完整,而且只能使用自己的数据,现在重新整理了一下,任何的微博数据都可以制作出来,一年一度的虐汪节,是继续蹲在角落默默吃狗粮还是主动出击告别单身汪加入散狗粮的行列就看你啦,
-
 Node.js 实现简单小说爬虫实例
Node.js 实现简单小说爬虫实例本文向大家介绍Node.js 实现简单小说爬虫实例,包括了Node.js 实现简单小说爬虫实例的使用技巧和注意事项,需要的朋友参考一下 最近因为剧荒,老大追了爱奇艺的一部网剧,由丁墨的同名小说《美人为馅》改编,目前已经放出两季,虽然整部剧槽点满满,但是老大看得不亦乐乎,并且在看完第二季之后跟我要小说资源,直接要奔原著去看结局…… 随手搜了下,都是在线资源,下载的话需要登录,注册登录好麻烦,写个爬虫
-
最佳爬虫确定与技术构建?
BuiltWith.com和类似的服务提供(收费)使用SalesForce或NationBuilder等特定技术构建的域列表。有一些我感兴趣的技术builtwith没有扫描,可能是因为它们的市场份额太小。 如果我们知道某个网站使用了某种技术的页面签名,那么识别尽可能多的这些网站的最佳方法是什么?我们希望有1000个,我们对那些在前1000万网站的流量感兴趣。(我们不认为最大的网站使用这种技术。)
-
Queue 示例 - 一个并发网络爬虫
Tornado 的 模块对于协程实现了异步的 生产者 / 消费者 模型, 实现了类似于 Python 标准库中线程中的 模块. 一个协程 yield 将会在队列中有值时暂停. 如果队列设置了最大值, 协程会 yield 暂停直到有空间来存放. 从零开始维护了一系列未完成的任务. 增加计数; 来减少它. 在这个网络爬虫的例子中, 队列开始仅包含 base_url. 当一个 worker 获取一个页面
-
 python3制作捧腹网段子页爬虫
python3制作捧腹网段子页爬虫本文向大家介绍python3制作捧腹网段子页爬虫,包括了python3制作捧腹网段子页爬虫的使用技巧和注意事项,需要的朋友参考一下 0x01 春节闲着没事(是有多闲),就写了个简单的程序,来爬点笑话看,顺带记录下写程序的过程。第一次接触爬虫是看了这么一个帖子,一个逗逼,爬取煎蛋网上妹子的照片,简直不要太方便。于是乎就自己照猫画虎,抓了点图片。 科技启迪未来,身为一个程序员,怎么能干这种事呢,还是爬
-
使用 Node.js 开发资讯爬虫流程
本文向大家介绍使用 Node.js 开发资讯爬虫流程,包括了使用 Node.js 开发资讯爬虫流程的使用技巧和注意事项,需要的朋友参考一下 最近项目需要一些资讯,因为项目是用 Node.js 来写的,所以就自然地用 Node.js 来写爬虫了 项目地址:github.com/mrtanweijie… ,项目里面爬取了 Readhub 、 开源中国 、 开发者头条 、 36Kr 这几个网站的资讯内容
-
第十四章 数据采集与爬虫
一 数据采集概念 任何完整的大数据平台,一般包括以下的几个过程: 数据采集 数据存储 数据处理 数据展现(可视化,报表和监控) 其中,数据采集是所有数据系统必不可少的,随着大数据越来越被重视,数据采集的挑战也变的尤为突出。这其中包括: 数据源多种多样 数据量大,变化快 如何保证数据采集的可靠性的性能 如何避免重复数据 如何保证数据的质量 我们今天就来看看当前可用的六款数据采集的产品,重点关注它们是
-
《使用 superagent 与 cheerio 完成简单爬虫》
目标 建立一个 lesson3 项目,在其中编写代码。 当在浏览器中访问 http://localhost:3000/ 时,输出 CNode(https://cnodejs.org/ ) 社区首页的所有帖子标题和链接,以 json 的形式。 输出示例: [ { "title": "【公告】发招聘帖的同学留意一下这里", "href": "http://cnodejs.org/t
-
21. 网络爬虫阶段案例实战
任务:Ajax爬取今日头条的街拍美图 爬取url地址:https://www.toutiao.com/search_content/ 分析: 分析url地址:https://www.toutiao.com/search_content/? 每页20条数据,Ajax加载数据 需要提交参数: params = { 'offset': offset, #页码数据
-
9. 网络爬虫中的异常处理
在网络爬虫运行时出现异常,若不处理则会因报错而终止运行,导致爬取数据中断,所以异常处理还是十分重要的。 urllib.error可以接收有urllib.request产生的异常。urllib.error有两个类,URLError和HTTPError。 URLError内有一个属性:reason 返回错误的原因 # 测试URLError的异常处理 from urllib import request
-
4.4 爬虫的配置、启动和终止
4.4 爬虫的配置、启动和终止 4.4.1 Spider Spider是爬虫启动的入口。在启动爬虫之前,我们需要使用一个PageProcessor创建一个Spider对象,然后使用run()进行启动。同时Spider的其他组件(Downloader、Scheduler、Pipeline)都可以通过set方法来进行设置。 方法 说明 示例 create(PageProcessor) 创建Spider
-
08 最简单的爬虫案例开发
前面的学习中我们已经简单了解了一些爬虫所需的知识,这节课我们就来做一个小爬虫来实践下我们前面所学习的知识,这节课我们会爬取慕课网首页所有的课程名称: 1. 爬取慕课网首页所有课程名称 我们第一个爬虫程序,是来爬取慕课网的首页的所有课程信息的名字。下面的代码锁使用到的技术有的我们并没有涉及到,后面的学习中我们会一一讲解。这里只是让大家对爬虫程序有个大概的了解,熟悉最基本的爬虫流程,以及对爬虫处理有一
-
爬虫 - 新站百度迟迟不收录?
新站百度迟迟不收录? 之前做网站一般做好在百度上验证提交一下,一般1~2周就收录了, 可今年3.1上线提交了一个新的网站,新的域名,新的备案,新的空间,据我知道的域名之类的都没问题,但是这都过去一个月多了,现在还没有收录首页(域名),是今年的新站不好收录了吗?还是什么情况?有知道的吗?
-
 人工智能爬山算法
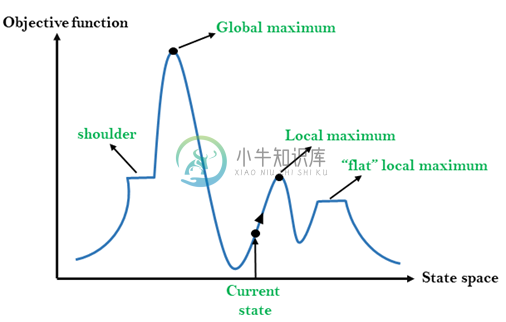
人工智能爬山算法主要内容:爬山算法的特点,爬山的国家空间图,状态的不同区域,爬山类型算法:,爬山算法存在的问题爬山(Hill Climbing)算法是一种局部搜索算法,它在增加高度/值的方向上连续移动,以找到山峰或最佳解决问题的方法。它在达到峰值时终止,其中没有邻居具有更高的值。 爬山算法是一种用于优化数学问题的技术。其中一个广泛讨论的爬山算法的例子是旅行商问题,其中我们需要最小化推销员的行进距离。 它也称为贪婪的本地搜索,因为它只关注其良好的直接邻居状态而不是超越它。爬山算法的节点有两个组成部分,即状态
-
什么是爬山法(Hill Climbing)?
本文向大家介绍什么是爬山法(Hill Climbing)?相关面试题,主要包含被问及什么是爬山法(Hill Climbing)?时的应答技巧和注意事项,需要的朋友参考一下 DFS的变形,不同的是每次选择的是最优的一个子结点,即局部最优解 例如,对于8数码问题,设置一个函数表示放错位置的数目,每次选择子结点中放错最少的结点 步骤: 1.建立一个栈,将根结点放入栈 2.判断栈顶元素是否是目标结点,如果