《python爬虫》专题
-
13. 网络爬虫案例实战1
本次案例是通过登录人人网,抓取登录后用户中心的信息 1. 模拟人人登录请求,执行登录验证操作 from urllib import request,parse login_url = 'http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=2018321648829' data = { 'email':'1352*****6'
-
1、爬虫原理与数据抓取
课程背景 我们生活在一个充满数据的时代。 每天,来自商业、社会以及我们的日常生活所产生「图像、音频、视频、文本、定位信息」等各种各样的海量数据,注入到我们的万维网(WWW)、计算机和各种数据存储设备,其中万维网则是最大的信息载体。 数据的爆炸式增长、规模庞大和广泛可用的数据,使得我们真正进入到了“大数据(Big Data)时代”。我们急需功能强大的数据处理技术(Data Technology),从
-
09 使用 Xpath 进行爬虫开发
Xpath( XML Path Language, XML路径语言),是一种在 XML 数据中查找信息的语言,现在,我们也可以使用它在 HTML 中查找需要的信息。 既然谈到 Xpath 是一门语言,当然它就会有自己的一些特定的语法。我们这里罗列一些经常使用的语法,熟悉下面的基本语法之后,就能满足我们日常的爬虫开发所用。 本小节主要内容: Xpath的基本概念 Xpath的基本语法 Xpath实战
-
 详解Python爬取并下载《电影天堂》3千多部电影
详解Python爬取并下载《电影天堂》3千多部电影本文向大家介绍详解Python爬取并下载《电影天堂》3千多部电影,包括了详解Python爬取并下载《电影天堂》3千多部电影的使用技巧和注意事项,需要的朋友参考一下 不知不觉,玩爬虫玩了一个多月了。 我愈发觉得,爬虫其实并不是什么特别高深的技术,它的价值不在于你使用了什么特别牛的框架,用了多么了不起的技术,它不需要。它只是以一种自动化搜集数据的小工具,能够获取到想要的数据,就是它最大的价值。 我的爬
-
 用Python爬取QQ音乐评论并制成词云图的实例
用Python爬取QQ音乐评论并制成词云图的实例本文向大家介绍用Python爬取QQ音乐评论并制成词云图的实例,包括了用Python爬取QQ音乐评论并制成词云图的实例的使用技巧和注意事项,需要的朋友参考一下 环境:Ubuntu16.4 python版本:3.6.4 库:wordcloud 这次我们要讲的是爬取QQ音乐的评论并制成云词图,我们这里拿周杰伦的等你下课来举例。 第一步:获取评论 我们先打开QQ音乐,搜索周杰伦的《等你下课》,直接拉到底
-
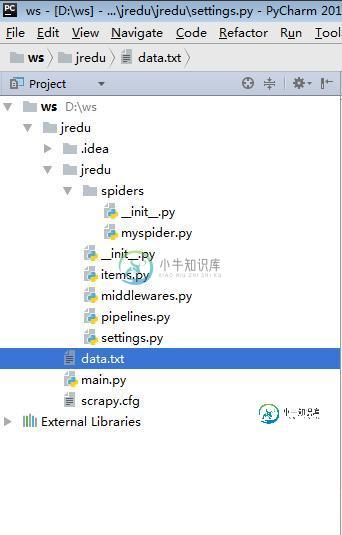 Python大数据之从网页上爬取数据的方法详解
Python大数据之从网页上爬取数据的方法详解本文向大家介绍Python大数据之从网页上爬取数据的方法详解,包括了Python大数据之从网页上爬取数据的方法详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python大数据之从网页上爬取数据的方法。分享给大家供大家参考,具体如下: myspider.py : items.py : middlewares.py : pipelines.py : settings.py
-
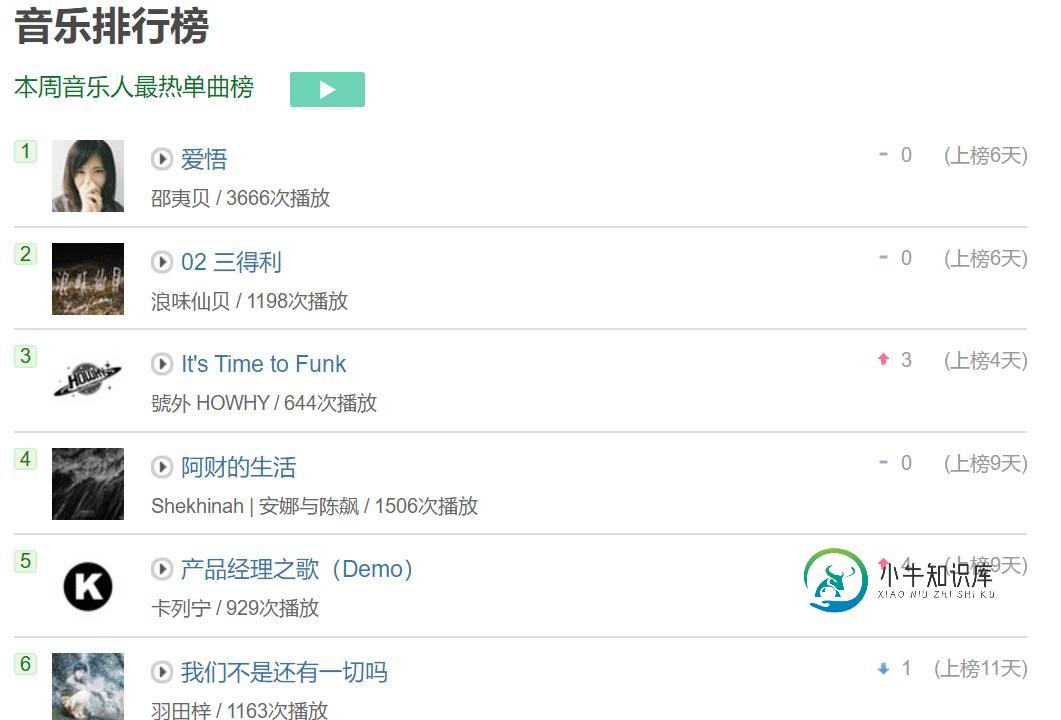 Python使用Beautiful Soup爬取豆瓣音乐排行榜过程解析
Python使用Beautiful Soup爬取豆瓣音乐排行榜过程解析本文向大家介绍Python使用Beautiful Soup爬取豆瓣音乐排行榜过程解析,包括了Python使用Beautiful Soup爬取豆瓣音乐排行榜过程解析的使用技巧和注意事项,需要的朋友参考一下 前言 要想学好爬虫,必须把基础打扎实,之前发布了两篇文章,分别是使用XPATH和requests爬取网页,今天的文章是学习Beautiful Soup并通过一个例子来实现如何使用Beautiful
-
Java Web爬网程序库
问题内容: 我想做一个基于Java的网络爬虫进行实验。我听说如果您是第一次使用Java编写Web爬虫,那是必须走的路。但是,我有两个重要问题。 我的程序如何“访问”或“连接”到网页?请简要说明。(我了解从硬件到软件的抽象层的基础,这里我对Java抽象感兴趣) 我应该使用哪些库?我假设我需要一个用于连接到网页的库,一个用于HTTP / HTTPS协议的库和一个用于HTML解析的库。 问题答案: 这是
-
Nutch爬行不起作用
我想使用Apache Nutch1.12爬网一个站点,并将数据索引到Apache Solr中。我已经遵循了这个教程。 我的seed.txt文件的url是http://nutch.apache.org/ 在我的regex url筛选器中,我有如下所示+^http://([a-z0-9]*.)*nutch.apache.org/ 当我试图获取数据时,我只得到seed.txt文件中的url。 我在这里错
-
使用Firebug进行爬取
注解 本教程所使用的样例站Google Directory已经 被Google关闭 了。不过教程中的概念任然适用。 如果您打算使用一个新的网站来更新本教程,您的贡献是再欢迎不过了。 详细信息请参考 Contributing to Scrapy 。 介绍 本文档介绍了如何适用 Firebug (一个Firefox的插件)来使得爬取更为简单,有趣。 更多有意思的Firefox插件请参考 对爬取有帮助的
-
18. App的信息爬取
之前我们讲解的都是Web网页信息爬取,随着移动互联的发展,越来越多的企业并没有提供Web网页端的服务,而是直接开发App。 App的爬取相比Web端爬取更加容易,反爬中能力没有那么强,而且响应数据大多都是JSON形式,解析更加简单。 在APP端若想查看和分析内容那就需要借助抓包软件,常用的有:Filddler、Charles、mitmproxy、Appium等。 mitmproxy是一个支持HTT
-
python爬虫 - 微信公众号文章自动同步到其他平台解决方案?
主题:使用Python爬虫和API实现微信公众号文章的自动同步 问题诉求:作为开发者,我们需要定期将微信公众号上发布的文章自动摘取,并发布到其他内容平台,如博客或自媒体网站。我们需要一个自动化的解决方案,能够实现文章内容的抓取、处理和同步发布。 运行环境: Python 3.8 或更高版本 相关Python库:requests, beautifulsoup4, html2text (用于网页内容抓
-
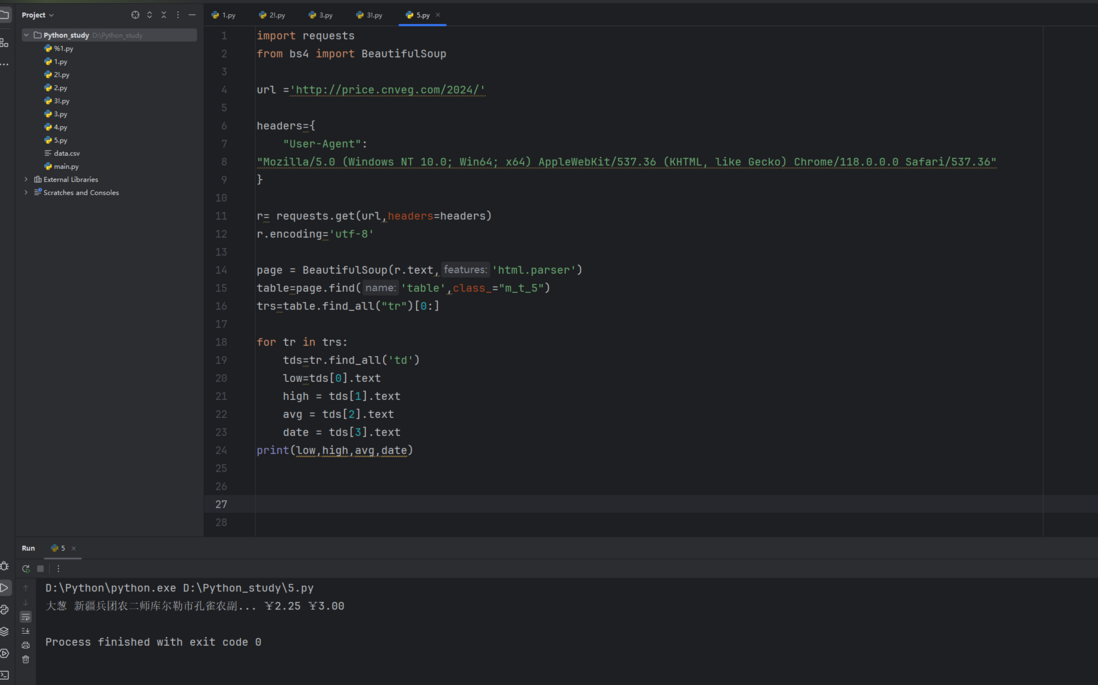 网络爬虫 - 如何解决爬虫切片时只能获取单个数据项的问题?
网络爬虫 - 如何解决爬虫切片时只能获取单个数据项的问题?我看做过切片所爬取的还是很全的
-
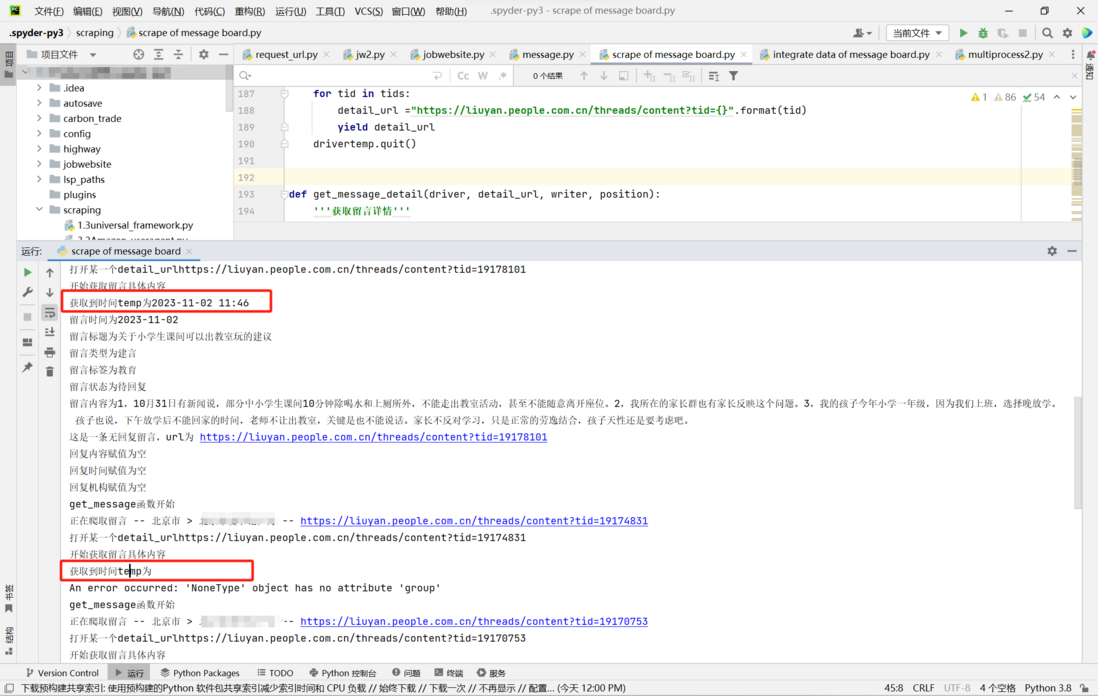 前端 - 爬虫爬取到标签内容有时为空有时正常,请问怎么解决?
前端 - 爬虫爬取到标签内容有时为空有时正常,请问怎么解决?在爬取人民网领导留言板数据时,在留言详情页面按照xpath提取留言时间的信息,但是有的留言可以提取出时间,有的留言提取出来是空,看起来非常随机,不明白这是为什么...当提取时间内容为空时,反复提取十几次,有时候是三十几次,又可以提取出来,不知道这是为什么?应该如何解决呢 此外不知道大家还有没有什么可以提高爬取速度的修改建议,或者可以实现爬取一部分存储一部分,中断后可以继续爬取不用从头再来的修改建议
-
 python实现模拟器爬取抖音评论数据的示例代码
python实现模拟器爬取抖音评论数据的示例代码本文向大家介绍python实现模拟器爬取抖音评论数据的示例代码,包括了python实现模拟器爬取抖音评论数据的示例代码的使用技巧和注意事项,需要的朋友参考一下 目标: 由于之前和朋友聊到抖音评论的爬虫,demo做出来之后一直没整理,最近时间充裕后,在这里做个笔记。 提示:大体思路 通过fiddle + app模拟器进行抖音抓包,使用python进行数据整理 安装需要的工具: python3 下载