《python爬虫》专题
-
第三章 爬虫和蜘蛛
简介 渗透测试可以通过多种途径完成,例如黑盒、灰盒和白盒。黑盒测试在测试者没有任何应用的前置信息条件下执行,除了服务器的 URL。白盒测试在测试者拥有目标的全部信息的条件下执行,例如它的构造、软件版本、测试用户、开发信息,以及其它。灰盒测试是黑盒和白盒的混合。 对于黑盒和灰盒测试,侦查阶段对测试者非常必然,以便发现白盒测试中通常由应用所有者提供的信息。 我们打算采取黑盒测试方式,因为它涉及到外部攻
-
示例: 并发的Web爬虫
8.6. 示例: 并发的Web爬虫 在5.6节中,我们做了一个简单的web爬虫,用bfs(广度优先)算法来抓取整个网站。在本节中,我们会让这个这个爬虫并行化,这样每一个彼此独立的抓取命令可以并行进行IO,最大化利用网络资源。crawl函数和gopl.io/ch5/findlinks3中的是一样的。 gopl.io/ch8/crawl1 func crawl(url string) []string
-
16. 分布式爬虫原理
在前面我们已经掌握了Scrapy框架爬虫,虽然爬虫是异步多线程的,但是我们只能在一台主机上运行,爬取效率还是有限。 分布式爬虫则是将多台主机组合起来,共同完成一个爬取任务,将大大提高爬取的效率。 16.1 分布式爬虫架构 回顾Scrapy的架构: Scrapy单机爬虫中有一个本地爬取队列Queue,这个队列是利用deque模块实现的。 如果有新的Request产生,就会放到队列里面,随后Reque
-
8. Scrapy爬虫案例实战
任务:爬取腾讯网中关于指定条件的所有社会招聘信息,搜索条件为北京地区,Python关键字的就业岗位,并将信息存储到MySql数据库中。 网址:https://hr.tencent.com/position.php?keywords=python&lid=2156 实现思路:首先爬取每页的招聘信息列表,再爬取对应的招聘详情信息 ① 创建项目 在命令行编写下面命令,创建项目tencent scrapy
-
4. 编写基本的爬虫
4. 编写基本的爬虫 在WebMagic里,实现一个基本的爬虫只需要编写一个类,实现PageProcessor接口即可。这个类基本上包含了抓取一个网站,你需要写的所有代码。 同时这部分还会介绍如何使用WebMagic的抽取API,以及最常见的抓取结果保存的问题。
-
2.3 第一个爬虫项目
2.3 第一个爬虫项目 在你的项目中添加了WebMagic的依赖之后,即可开始第一个爬虫的开发了!我们这里拿一个抓取Github信息的例子: import us.codecraft.webmagic.Page; import us.codecraft.webmagic.Site; import us.codecraft.webmagic.Spider; import us.codecraft.we
-
urllib.robotparser — 互联网爬虫控制
测试访问权限 # urllib_robotparser_simple.py from urllib import parse from urllib import robotparser AGENT_NAME = 'PyMOTW' URL_BASE = 'https://pymotw.com/' parser = robotparser.RobotFileParser() parser.set_
-
Python爬取视频(其实是一篇福利)过程解析
本文向大家介绍Python爬取视频(其实是一篇福利)过程解析,包括了Python爬取视频(其实是一篇福利)过程解析的使用技巧和注意事项,需要的朋友参考一下 窗外下着小雨,作为单身程序员的我逛着逛着发现一篇好东西,来自知乎 你都用 Python 来做什么?的第一个高亮答案。 到上面去看了看,地址都是明文的,得,赶紧开始吧。 下载流式文件,requests库中请求的stream设为True就可以啦,文
-
Python爬取数据保存为Json格式的代码示例
本文向大家介绍Python爬取数据保存为Json格式的代码示例,包括了Python爬取数据保存为Json格式的代码示例的使用技巧和注意事项,需要的朋友参考一下 python爬取数据保存为Json格式 代码如下: 总结 以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对呐喊教程的支持。如果你想了解更多相关内容请查看下面相关链接
-
 Python爬取网易云音乐上评论火爆的歌曲
Python爬取网易云音乐上评论火爆的歌曲本文向大家介绍Python爬取网易云音乐上评论火爆的歌曲,包括了Python爬取网易云音乐上评论火爆的歌曲的使用技巧和注意事项,需要的朋友参考一下 前言 网易云音乐这款音乐APP本人比较喜欢,用户量也比较大,而网易云音乐之所以用户众多和它的歌曲评论功能密不可分,很多歌曲的评论非常有意思,其中也不乏很多感人的评论。但是,网易云音乐并没有提供热评排行榜和按评论排序的功能,没关系,本文就使用爬虫给大家爬
-
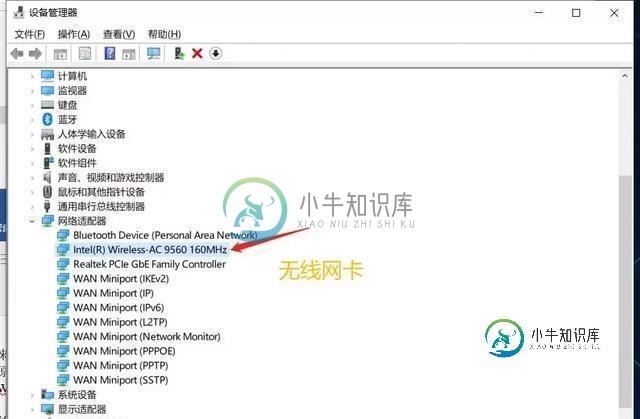 Python爬取破解无线网络wifi密码过程解析
Python爬取破解无线网络wifi密码过程解析本文向大家介绍Python爬取破解无线网络wifi密码过程解析,包括了Python爬取破解无线网络wifi密码过程解析的使用技巧和注意事项,需要的朋友参考一下 前言 今天从WiFi连接的原理,再结合代码为大家详细的介绍如何利用python来破解WiFi。 Python真的是无所不能,原因就是因为Python有数目庞大的库,无数的现成的轮子,让你做很多很多应用都非常方便。wifi跟我们的生活息息相关
-
在Selenium中查找隐藏的超链接(Python网络爬行)
我想跟踪销售数据从化妆品品牌使用硒,但我有一个困难,找到超链接到下一页。 https://www.gsshop.com/shop/sect/sects.gs?isect=1425746&brandid=143878&lseq=407585 在这个链接中,有3个页面,我可以通过下一个页面,如果我点击页面底部的2或3。 但是,当我检查html代码时,它只返回表单。所以我在“a”标签中找不到任何指向下一
-
编写Python爬虫抓取暴走漫画上gif图片的实例分享
本文向大家介绍编写Python爬虫抓取暴走漫画上gif图片的实例分享,包括了编写Python爬虫抓取暴走漫画上gif图片的实例分享的使用技巧和注意事项,需要的朋友参考一下 本文要介绍的爬虫是抓取暴走漫画上的GIF趣图,方便离线观看。爬虫用的是python3.3开发的,主要用到了urllib、request和BeautifulSoup模块。 urllib模块提供了从万维网中获取数据的高层接口,当我们
-
讲解Python的Scrapy爬虫框架使用代理进行采集的方法
本文向大家介绍讲解Python的Scrapy爬虫框架使用代理进行采集的方法,包括了讲解Python的Scrapy爬虫框架使用代理进行采集的方法的使用技巧和注意事项,需要的朋友参考一下 1.在Scrapy工程下新建“middlewares.py” 2.在项目配置文件里(./project_name/settings.py)添加 只要两步,现在请求就是通过代理的了。测试一下^_^ 3.使用随机user
-
 零基础写python爬虫之urllib2中的两个重要概念:Openers和Handlers
零基础写python爬虫之urllib2中的两个重要概念:Openers和Handlers本文向大家介绍零基础写python爬虫之urllib2中的两个重要概念:Openers和Handlers,包括了零基础写python爬虫之urllib2中的两个重要概念:Openers和Handlers的使用技巧和注意事项,需要的朋友参考一下 在开始后面的内容之前,先来解释一下urllib2中的两个个方法:info / geturl urlopen返回的应答对象response(或者HTTPErr