《python爬虫》专题
-
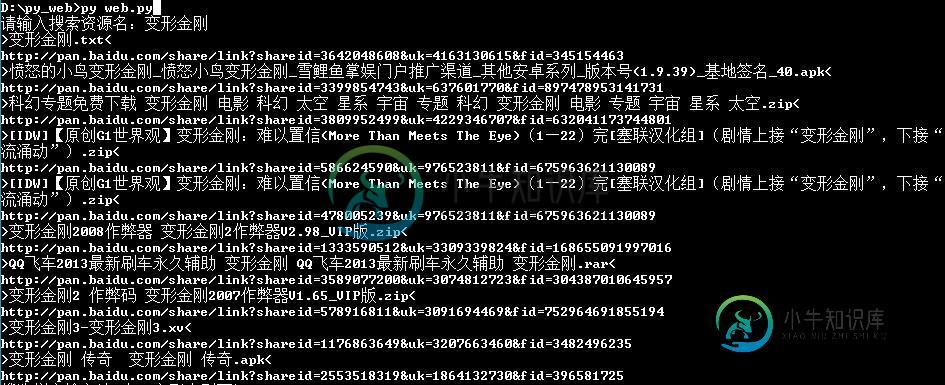 python urllib爬取百度云连接的实例代码
python urllib爬取百度云连接的实例代码本文向大家介绍python urllib爬取百度云连接的实例代码,包括了python urllib爬取百度云连接的实例代码的使用技巧和注意事项,需要的朋友参考一下 翻看自己以前写的程序,发现写过一个爬取盘多多百度云资源的东西,完全是当时想看变形金刚才自己写的,而且当时第一次接触python大概写了有2天才搞出来这个程序,学习python语言,可以看得出来那时候的代码写的真的low。虽然现在也不怎么
-
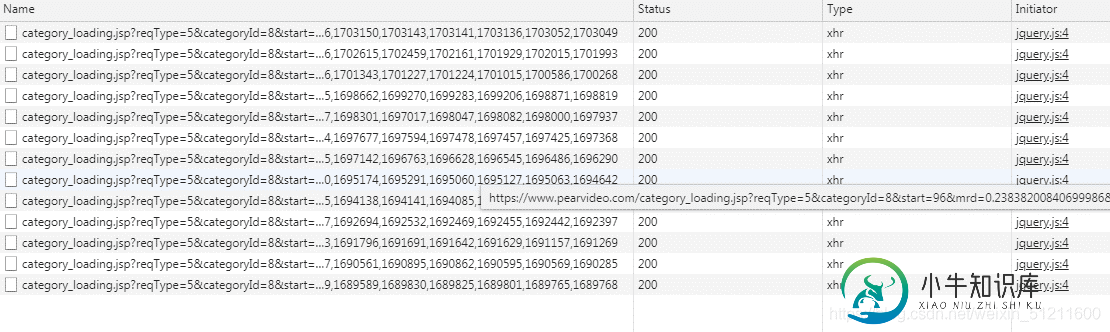 基于python爬取梨视频实现过程解析
基于python爬取梨视频实现过程解析本文向大家介绍基于python爬取梨视频实现过程解析,包括了基于python爬取梨视频实现过程解析的使用技巧和注意事项,需要的朋友参考一下 目标网址:梨视频 然后我们找到科技这一页:https://www.pearvideo.com/category_8。其实你要哪一页都行,你喜欢就行。嘿嘿… 这是动态网站,所以咱们直奔network 然后去到XHR: 找规律,这个应该不难,我就直接贴网址上来咯,
-
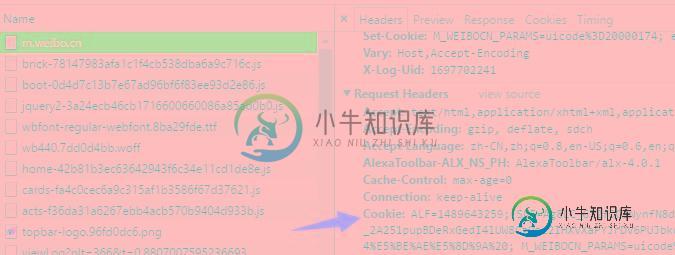 使用python爬取微博数据打造一颗“心”
使用python爬取微博数据打造一颗“心”本文向大家介绍使用python爬取微博数据打造一颗“心”,包括了使用python爬取微博数据打造一颗“心”的使用技巧和注意事项,需要的朋友参考一下 前言 一年一度的虐狗节终于过去了,朋友圈各种晒,晒自拍,晒娃,晒美食,秀恩爱的。程序员在晒什么,程序员在加班。但是礼物还是少不了的,送什么好?作为程序员,我准备了一份特别的礼物,用以往发的微博数据打造一颗“爱心”,我想她一定会感动得哭了吧。哈哈 准备工
-
Python爬取国外天气预报网站的方法
本文向大家介绍Python爬取国外天气预报网站的方法,包括了Python爬取国外天气预报网站的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python爬取国外天气预报网站的方法。分享给大家供大家参考。具体如下: crawl_weather.py如下: FetchLocation.py如下: 希望本文所述对大家的python程序设计有所帮助。
-
python脚本爬取字体文件的实现方法
本文向大家介绍python脚本爬取字体文件的实现方法,包括了python脚本爬取字体文件的实现方法的使用技巧和注意事项,需要的朋友参考一下 前言 大家应该都有所体会,为了提高验证码的识别准确率,我们当然要首先得到足够多的测试数据。验证码下载下来容易,但是需要人脑手工识别着实让人受不了,于是我就想了个折衷的办法——自己造验证码。 为了保证多样性,首先当然需要不同的字模了,直接用类似ttf格式的字体文
-
Python Scrapy多页数据爬取实现过程解析
本文向大家介绍Python Scrapy多页数据爬取实现过程解析,包括了Python Scrapy多页数据爬取实现过程解析的使用技巧和注意事项,需要的朋友参考一下 1.先指定通用模板 url = 'https://www.qiushibaike.com/text/page/%d/'#通用的url模板 pageNum = 1 2.对parse方法递归处理 parse第一次调用表示的是用来解析第一页对
-
python使用beautifulsoup4爬取酷狗音乐代码实例
本文向大家介绍python使用beautifulsoup4爬取酷狗音乐代码实例,包括了python使用beautifulsoup4爬取酷狗音乐代码实例的使用技巧和注意事项,需要的朋友参考一下 这篇文章主要介绍了python使用beautifulsoup4爬取酷狗音乐代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 小编经常在网上听一些音乐但
-
Python下使用Scrapy爬取网页内容的实例
本文向大家介绍Python下使用Scrapy爬取网页内容的实例,包括了Python下使用Scrapy爬取网页内容的实例的使用技巧和注意事项,需要的朋友参考一下 上周用了一周的时间学习了Python和Scrapy,实现了从0到1完整的网页爬虫实现。研究的时候很痛苦,但是很享受,做技术的嘛。 首先,安装Python,坑太多了,一个个爬。由于我是windows环境,没钱买mac, 在安装的时候遇到各种各
-
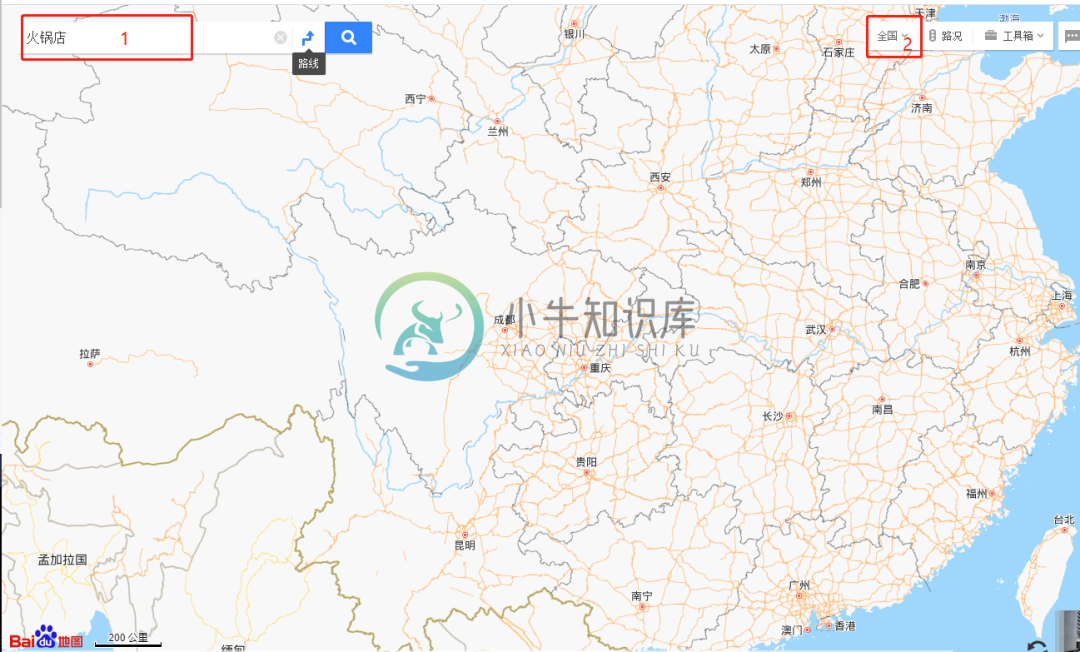 Python爬取全国火锅店并可视化展示
Python爬取全国火锅店并可视化展示先给大家分享一个数据可视化案例:如何获取全国不同城市火锅店数量情况,并将这些数据进行可视化展示,以更加直观的方式去浏览全国不同省份、不同城市的火锅店分布情况。(本文数据来自于某度地图,通过python技术知识去获取数据并进行可视化。)
-
使用python实现抓取腾讯视频所有电影的爬虫
本文向大家介绍使用python实现抓取腾讯视频所有电影的爬虫,包括了使用python实现抓取腾讯视频所有电影的爬虫的使用技巧和注意事项,需要的朋友参考一下 用python实现的抓取腾讯视频所有电影的爬虫 总结 以上所述是小编给大家介绍的使用python实现抓取腾讯视频所有电影的爬虫,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!
-
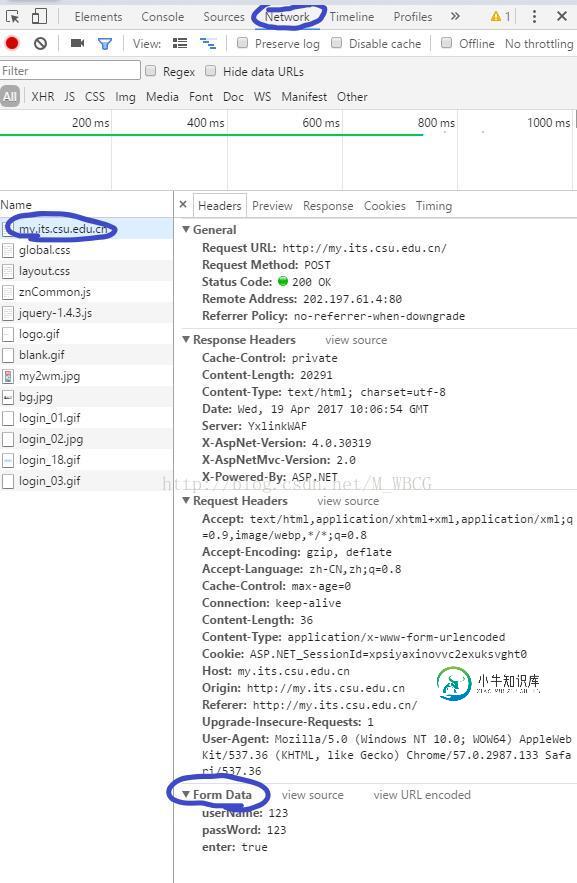 Python 网络爬虫--关于简单的模拟登录实例讲解
Python 网络爬虫--关于简单的模拟登录实例讲解本文向大家介绍Python 网络爬虫--关于简单的模拟登录实例讲解,包括了Python 网络爬虫--关于简单的模拟登录实例讲解的使用技巧和注意事项,需要的朋友参考一下 和获取网页上的信息不同,想要进行模拟登录还需要向服务器发送一些信息,如账号、密码等等。 模拟登录一个网站大致分为这么几步: 1.先将登录网站的隐藏信息找到,并将其内容先进行保存(由于我这里登录的网站并没有额外信息,所以这里没有进行信
-
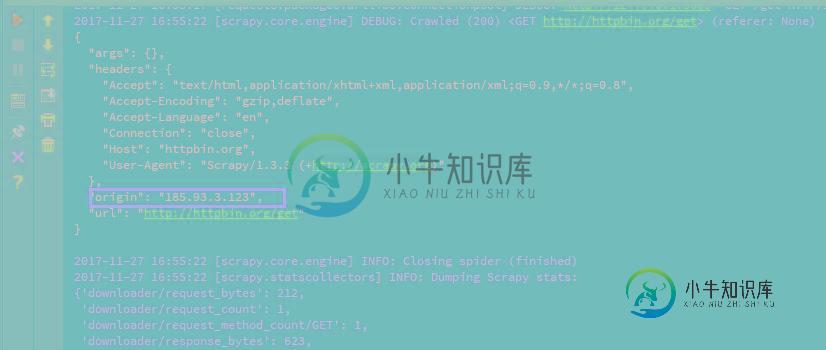 Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能示例
Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能示例本文向大家介绍Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能示例,包括了Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能。分享给大家供
-
 使用Python的urllib和urllib2模块制作爬虫的实例教程
使用Python的urllib和urllib2模块制作爬虫的实例教程本文向大家介绍使用Python的urllib和urllib2模块制作爬虫的实例教程,包括了使用Python的urllib和urllib2模块制作爬虫的实例教程的使用技巧和注意事项,需要的朋友参考一下 urllib 学习python完基础,有些迷茫.眼睛一闭,一种空白的窒息源源不断而来.还是缺少练习,遂拿爬虫来练练手.学习完斯巴达python爬虫课程后,将心得整理如下,供后续翻看.整篇笔记主要分以下
-
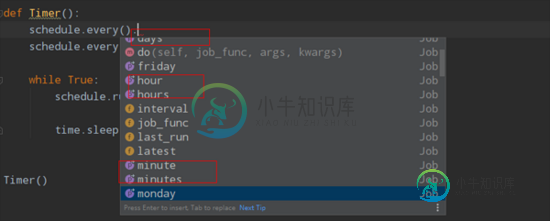 Python爬虫定时计划任务的几种常见方法(推荐)
Python爬虫定时计划任务的几种常见方法(推荐)本文向大家介绍Python爬虫定时计划任务的几种常见方法(推荐),包括了Python爬虫定时计划任务的几种常见方法(推荐)的使用技巧和注意事项,需要的朋友参考一下 记得以前的Windows任务定时是可以正常使用的,今天试了下,发现不能正常使用了,任务计划总是挂起。接下来记录下Python爬虫定时任务的几种解决方法。 1.方法一、while True 首先最容易的是while true死循环挂起,不
-
Linux部署python爬虫脚本,并设置定时任务的方法
本文向大家介绍Linux部署python爬虫脚本,并设置定时任务的方法,包括了Linux部署python爬虫脚本,并设置定时任务的方法的使用技巧和注意事项,需要的朋友参考一下 去年因项目需要,用python写了个爬虫。因爬到的数据需要存到生产环境的PG数据库。所以需要将脚本部署到CentOS服务器,并设置定时任务,自动启动脚本。 实施步骤如下: 1.安装pip(操作系统自带了python2.6可以