《python爬虫》专题
-
Runnig Ex爬行器
嗨,我正在运行这个开源Ex-Crawler的罐子 但我总是收到这样的错误:og4j:WARN找不到记录器的追加器(eu.medsea.mimeutil.TextMimeDetector)。log4j:警告请正确初始化log4j系统。log4j:请参阅http://logging.apache.org/log4j/1.2/faq.html#noconfig更多信息
-
一文带你了解Python 四种常见基础爬虫方法介绍
本文向大家介绍一文带你了解Python 四种常见基础爬虫方法介绍,包括了一文带你了解Python 四种常见基础爬虫方法介绍的使用技巧和注意事项,需要的朋友参考一下 一、Urllib方法 Urllib是python内置的HTTP请求库 二、requests方法 –Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库 –urllib还
-
使用Python爬虫库requests发送请求、传递URL参数、定制headers
本文向大家介绍使用Python爬虫库requests发送请求、传递URL参数、定制headers,包括了使用Python爬虫库requests发送请求、传递URL参数、定制headers的使用技巧和注意事项,需要的朋友参考一下 首先我们先引入requests模块 一、发送请求 二、传递URL参数 URL传递参数的形式为:httpbin.org/get?key=val。但是手动的构造很麻烦,这是可以
-
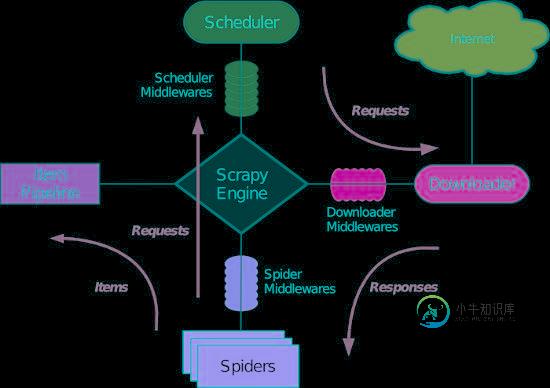 深入剖析Python的爬虫框架Scrapy的结构与运作流程
深入剖析Python的爬虫框架Scrapy的结构与运作流程本文向大家介绍深入剖析Python的爬虫框架Scrapy的结构与运作流程,包括了深入剖析Python的爬虫框架Scrapy的结构与运作流程的使用技巧和注意事项,需要的朋友参考一下 网络爬虫(Web Crawler, Spider)就是一个在网络上乱爬的机器人。当然它通常并不是一个实体的机器人,因为网络本身也是虚拟的东西,所以这个“机器人”其实也就是一段程序,并且它也不是乱爬,而是有一定目的的,并且
-
python 每天如何定时启动爬虫任务(实现方法分享)
本文向大家介绍python 每天如何定时启动爬虫任务(实现方法分享),包括了python 每天如何定时启动爬虫任务(实现方法分享)的使用技巧和注意事项,需要的朋友参考一下 python2.7环境下运行 安装相关模块 想要每天定时启动,最好是把程序放在linux服务器上运行,毕竟linux可以不用关机,即定时任务一直存活; 以上这篇python 每天如何定时启动爬虫任务(实现方法分享)就是小编分享给
-
基于python实现的抓取腾讯视频所有电影的爬虫
本文向大家介绍基于python实现的抓取腾讯视频所有电影的爬虫,包括了基于python实现的抓取腾讯视频所有电影的爬虫的使用技巧和注意事项,需要的朋友参考一下 我搜集了国内10几个电影网站的数据,里面近几十W条记录,用文本没法存,mongodb学习成本非常低,安装、下载、运行起来不会花你5分钟时间。
-
 零基础写python爬虫之使用urllib2组件抓取网页内容
零基础写python爬虫之使用urllib2组件抓取网页内容本文向大家介绍零基础写python爬虫之使用urllib2组件抓取网页内容,包括了零基础写python爬虫之使用urllib2组件抓取网页内容的使用技巧和注意事项,需要的朋友参考一下 版本号:Python2.7.5,Python3改动较大,各位另寻教程。 所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地。 类似于使用程序模拟IE浏览器的功能,把URL作为HTTP请求的
-
 使用Python编写简单网络爬虫抓取视频下载资源
使用Python编写简单网络爬虫抓取视频下载资源本文向大家介绍使用Python编写简单网络爬虫抓取视频下载资源,包括了使用Python编写简单网络爬虫抓取视频下载资源的使用技巧和注意事项,需要的朋友参考一下 我第一次接触爬虫这东西是在今年的5月份,当时写了一个博客搜索引擎,所用到的爬虫也挺智能的,起码比电影来了这个站用到的爬虫水平高多了! 回到用Python写爬虫的话题。 Python一直是我主要使用的脚本语言,没有之一。Python的语言简洁
-
java能写爬虫程序吗
本文向大家介绍java能写爬虫程序吗,包括了java能写爬虫程序吗的使用技巧和注意事项,需要的朋友参考一下 我们经常会使用网络爬虫去爬取需要的内容,提到爬虫,可能大家伙都会想到python,其实除了python,还有java。java的编程语言简单规范,是很好的爬虫工具。而且java爬虫的语言运行速度比python快,另外,java的多线程是可以利用多核的。 1、java为什么可以应用于网络爬虫?
-
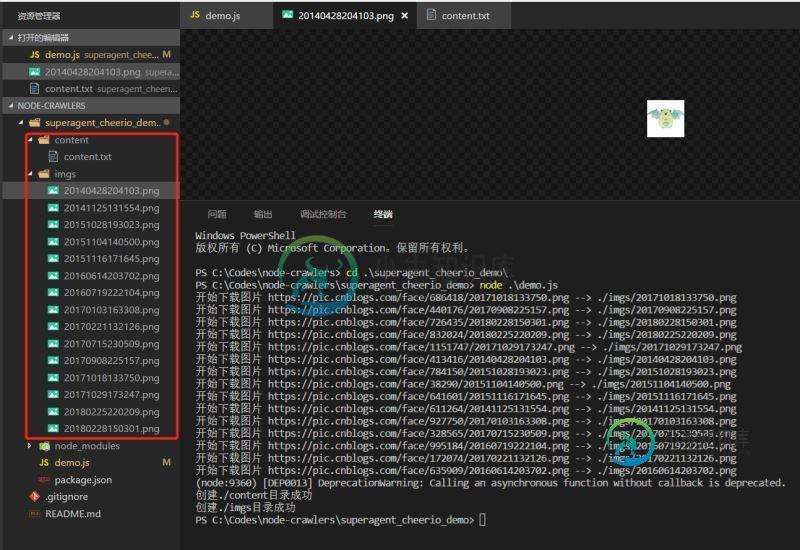 nodejs爬虫初试superagent和cheerio
nodejs爬虫初试superagent和cheerio本文向大家介绍nodejs爬虫初试superagent和cheerio,包括了nodejs爬虫初试superagent和cheerio的使用技巧和注意事项,需要的朋友参考一下 前言 早就听过爬虫,这几天开始学习nodejs,写了个爬虫https://github.com/leichangchun/node-crawlers/tree/master/superagent_cheerio_demo
-
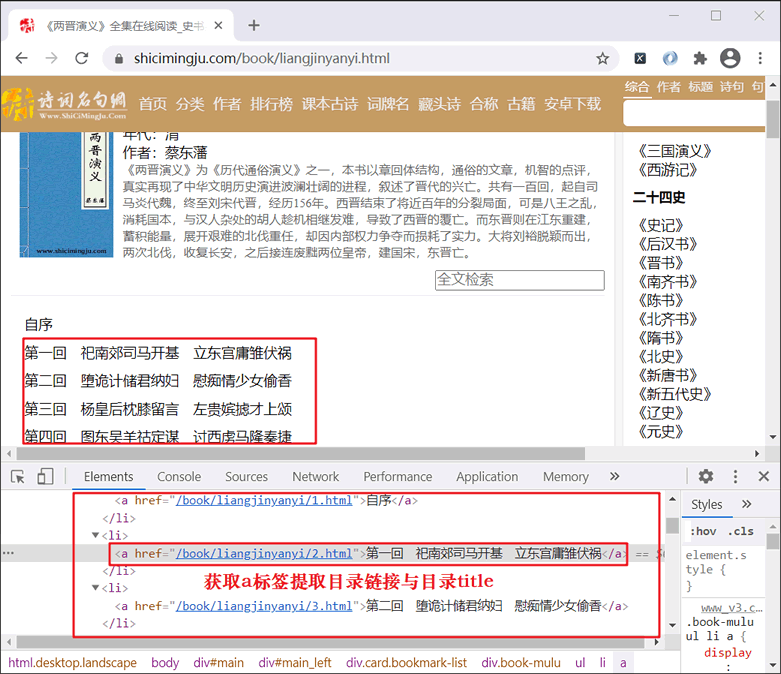 [实例]爬虫下载小说
[实例]爬虫下载小说主要内容:案例简单分析,编写爬虫程序本节通过具体的爬虫程序,演示 BS4 解析库的实际应用。爬虫程序目标:下载诗词名句网( https://www.shicimingju.com/book/)《 两晋演义》小说。 关于分析网页分过程,这里不再做详细介绍了,只要通读了前面的文章,那么关于如何分析网页,此时您应该了然于胸了。其实,无论您爬取什么类型的网站,分析过程总是相似的。 案例简单分析 首先判网站属于静态网站,因此您的主要任务是分析
-
[实例]爬虫抓取网页
主要内容:导入所需模块,拼接URL地址,向URL发送请求,保存为本地文件,函数式编程修改程序本节讲解第一个 Python 爬虫实战案例:抓取您想要的网页,并将其保存至本地计算机。 首先我们对要编写的爬虫程序进行简单地分析,该程序可分为以下三个部分: 拼接 url 地址 发送请求 将照片保存至本地 明确逻辑后,我们就可以正式编写爬虫程序了。 导入所需模块 本节内容使用 urllib 库来编写爬虫,下面导入程序所用模块: 拼接URL地址 定义 URL 变量,拼接 url 地址。代码如下所示:
-
 node+express制作爬虫教程
node+express制作爬虫教程本文向大家介绍node+express制作爬虫教程,包括了node+express制作爬虫教程的使用技巧和注意事项,需要的朋友参考一下 最近开始重新学习node.js,之前学的都忘了。所以准备重新学一下,那么,先从一个简单的爬虫开始吧。 什么是爬虫 百度百科的解释: 爬虫即网络爬虫,是一种自动获取网页内容的程序。是搜索引擎的重要组成部分,因此搜索引擎优化很大程度上就是针对爬虫而做出的优化。 通俗一
-
Java 爬虫工具Jsoup详解
本文向大家介绍Java 爬虫工具Jsoup详解,包括了Java 爬虫工具Jsoup详解的使用技巧和注意事项,需要的朋友参考一下 Java 爬虫工具Jsoup详解 Jsoup是一款 Java 的 HTML 解析器,可直接解析某个 URL 地址、HTML 文本内容。它提供了一套非常省力的 API,可通过 DOM,CSS 以及类似于 jQuery 的操作方法来取出和操作数据。 jsoup 的主要功能如
-
如何识别网络爬虫?
问题内容: 如何过滤来自网络抓取工具等的点击。不是人类的点击。 我使用maxmind.com从IP请求城市。.如果我必须支付所有点击数(包括网络抓取工具,机器人等)的话,这并不便宜。 问题答案: 有两种检测机器人的一般方法,我将它们称为“礼貌/被动”和“激进”。基本上,您必须使您的网站出现心理障碍。 有礼貌 这些是礼貌地告诉抓取工具他们不应该抓取您的网站并限制抓取频率的方法。可以通过robots.