《python爬虫》专题
-
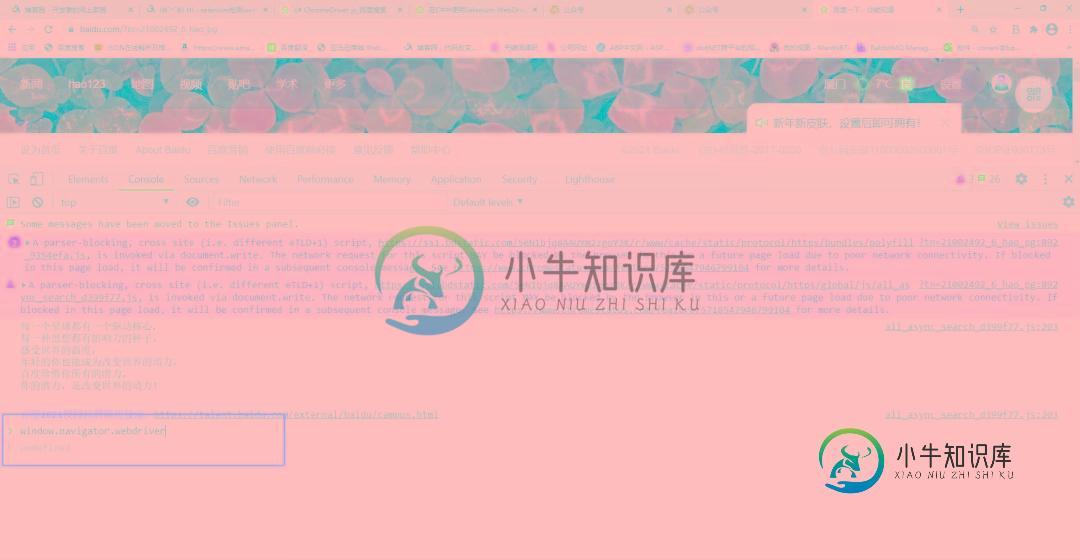 c# Selenium爬取数据时防止webdriver封爬虫的方法
c# Selenium爬取数据时防止webdriver封爬虫的方法本文向大家介绍c# Selenium爬取数据时防止webdriver封爬虫的方法,包括了c# Selenium爬取数据时防止webdriver封爬虫的方法的使用技巧和注意事项,需要的朋友参考一下 背景 大家在使用Selenium + Chromedriver爬取网站信息的时候,以为这样就能做到不被网站的反爬虫机制发现。但是实际上很多参数和实际浏览器还是不一样的,只要网站进行判断处理,就能轻轻松松识
-
 python爬虫把url链接编码成gbk2312格式过程解析
python爬虫把url链接编码成gbk2312格式过程解析本文向大家介绍python爬虫把url链接编码成gbk2312格式过程解析,包括了python爬虫把url链接编码成gbk2312格式过程解析的使用技巧和注意事项,需要的朋友参考一下 1. 问题 抓取某个网站,发现请求参数是乱码格式, 这是点击 TextView,发现请求参数如下图所示 3. 那么=%B9%FA%CE%F1%D4%BA%B7%A2%D5%B9%D1%D0%BE%BF%D6%D0%
-
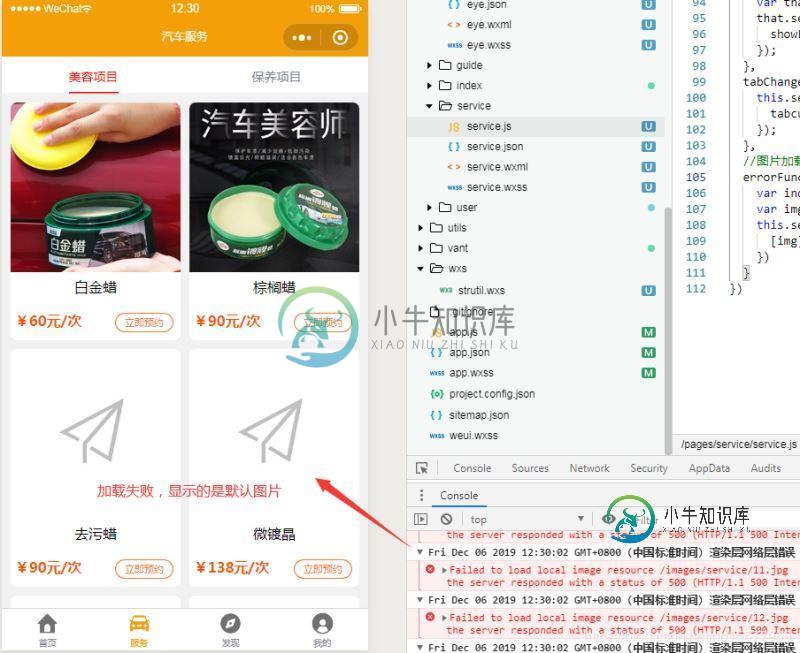 python爬虫模拟浏览器的两种方法实例分析
python爬虫模拟浏览器的两种方法实例分析本文向大家介绍python爬虫模拟浏览器的两种方法实例分析,包括了python爬虫模拟浏览器的两种方法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python爬虫模拟浏览器的两种方法。分享给大家供大家参考,具体如下: 爬虫爬取网站出现403,因为站点做了防爬虫的设置 一、Herders 属性 爬取CSDN博客 爬取结果 urllib.error.HTTPError: HTTP
-
 Python爬虫运用正则表达式的方法和优缺点
Python爬虫运用正则表达式的方法和优缺点本文向大家介绍Python爬虫运用正则表达式的方法和优缺点,包括了Python爬虫运用正则表达式的方法和优缺点的使用技巧和注意事项,需要的朋友参考一下 前言 我看到最近几部电影很火,查了一下猫眼电影上的数据,发现还有个榜单,里面有各种经典和热映电影的排行榜,然后我觉得电影封面图还挺好看的,想着一张一张下载真是费时费力,于是突发奇想,好像可以用一下最近学的东西实现我的需求,学习了正则表达式之后,想着
-
python通过伪装头部数据抵抗反爬虫的实例
本文向大家介绍python通过伪装头部数据抵抗反爬虫的实例,包括了python通过伪装头部数据抵抗反爬虫的实例的使用技巧和注意事项,需要的朋友参考一下 0x00 环境 系统环境:win10 编写工具:JetBrains PyCharm Community Edition 2017.1.2 x64 python 版本:python-3.6.2 抓包工具:Fiddler 4 0x01 头部数据伪装思路
-
Python爬虫框架scrapy实现的文件下载功能示例
本文向大家介绍Python爬虫框架scrapy实现的文件下载功能示例,包括了Python爬虫框架scrapy实现的文件下载功能示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python爬虫框架scrapy实现的文件下载功能。分享给大家供大家参考,具体如下: 我们在写普通脚本的时候,从一个网站拿到一个文件的下载url,然后下载,直接将数据写入文件或者保存下来,但是这个需要我们自己一点一
-
 Python爬虫之正则表达式基本用法实例分析
Python爬虫之正则表达式基本用法实例分析本文向大家介绍Python爬虫之正则表达式基本用法实例分析,包括了Python爬虫之正则表达式基本用法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python爬虫之正则表达式基本用法。分享给大家供大家参考,具体如下: 一、简介 正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:Regular Expression,在代码中常简写为regex、re
-
Python爬虫抓取代理IP并检验可用性的实例
本文向大家介绍Python爬虫抓取代理IP并检验可用性的实例,包括了Python爬虫抓取代理IP并检验可用性的实例的使用技巧和注意事项,需要的朋友参考一下 经常写爬虫,难免会遇到ip被目标网站屏蔽的情况,银次一个ip肯定不够用,作为节约的程序猿,能不花钱就不花钱,那就自己去找吧,这次就写了下抓取 西刺代理上的ip,但是这个网站也反爬!!! 至于如何应对,我觉得可以通过增加延时试试,可能是我抓取的太
-
Python使用Beautiful Soup包编写爬虫时的一些关键点
本文向大家介绍Python使用Beautiful Soup包编写爬虫时的一些关键点,包括了Python使用Beautiful Soup包编写爬虫时的一些关键点的使用技巧和注意事项,需要的朋友参考一下 1.善于利用soup节点的parent属性 比如对于已经得到了如下html代码: 的soup变量eachMonthHeader了。 想要提取其中的 Month的label的值:November 和Ye
-
Python的爬虫包Beautiful Soup中用正则表达式来搜索
本文向大家介绍Python的爬虫包Beautiful Soup中用正则表达式来搜索,包括了Python的爬虫包Beautiful Soup中用正则表达式来搜索的使用技巧和注意事项,需要的朋友参考一下 Beautiful Soup使用时,一般可以通过指定对应的name和attrs去搜索,特定的名字和属性,以找到所需要的部分的html代码。 但是,有时候,会遇到,对于要处理的内容中,其name或att
-
python爬虫获取小区经纬度以及结构化地址
本文向大家介绍python爬虫获取小区经纬度以及结构化地址,包括了python爬虫获取小区经纬度以及结构化地址的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了python爬虫获取小区经纬度、地址的具体代码,供大家参考,具体内容如下 通过小区名称利用百度api可以获取小区的地址以及经纬度,但是由于api返回的值中的地址形式不同,所以可以首先利用小区名称进行一轮爬虫,获取小区的经纬度,然
-
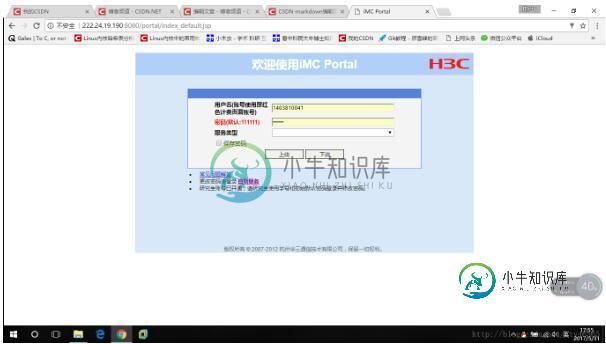 python爬虫_实现校园网自动重连脚本的教程
python爬虫_实现校园网自动重连脚本的教程本文向大家介绍python爬虫_实现校园网自动重连脚本的教程,包括了python爬虫_实现校园网自动重连脚本的教程的使用技巧和注意事项,需要的朋友参考一下 一、背景 最近学校校园网不知道是什么情况,总出现掉线的情况。每次掉线都需要我手动打开web浏览器重新进行账号密码输入,重新进行登录。系统的问题我没办法解决,但是可以写一个简单的python脚本用于自动登录校园网。每次掉线后,再打开任意网页就是这
-
使用Python的Scrapy框架编写web爬虫的简单示例
本文向大家介绍使用Python的Scrapy框架编写web爬虫的简单示例,包括了使用Python的Scrapy框架编写web爬虫的简单示例的使用技巧和注意事项,需要的朋友参考一下 在这个教材中,我们假定你已经安装了Scrapy。假如你没有安装,你可以参考这个安装指南。 我们将会用开放目录项目(dmoz)作为我们例子去抓取。 这个教材将会带你走过下面这几个方面: 创造一个新的Scrapy项
-
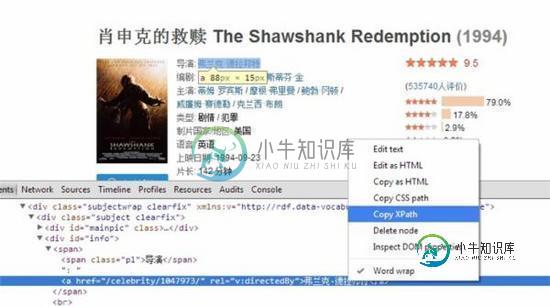 实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250
实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250本文向大家介绍实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250,包括了实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250的使用技巧和注意事项,需要的朋友参考一下 安装部署Scrapy 在安装Scrapy前首先需要确定的是已经安装好了Python(目前Scrapy支持Python2.5,Python2.6和Python2.7)。官方文档中介绍了三种方法进行安装,我采用的
-
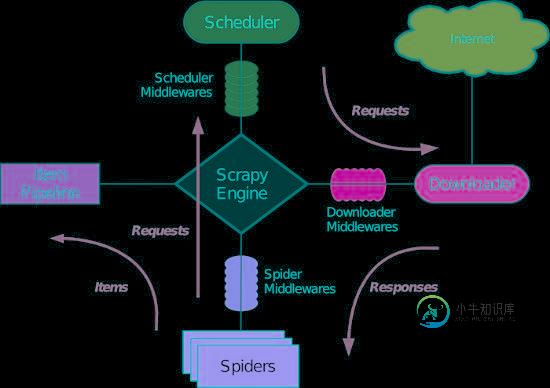 Python的爬虫程序编写框架Scrapy入门学习教程
Python的爬虫程序编写框架Scrapy入门学习教程本文向大家介绍Python的爬虫程序编写框架Scrapy入门学习教程,包括了Python的爬虫程序编写框架Scrapy入门学习教程的使用技巧和注意事项,需要的朋友参考一下 1. Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。 其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以