《python爬虫》专题
-
python中用Scrapy实现定时爬虫的实例讲解
本文向大家介绍python中用Scrapy实现定时爬虫的实例讲解,包括了python中用Scrapy实现定时爬虫的实例讲解的使用技巧和注意事项,需要的朋友参考一下 一般网站发布信息会在具体实现范围内发布,我们在进行网络爬虫的过程中,可以通过设置定时爬虫,定时的爬取网站的内容。使用python爬虫框架Scrapy框架可以实现定时爬虫,而且可以根据我们的时间需求,方便的修改定时的时间。 1、Scrap
-
 Python爬虫抓取指定网页图片代码实例
Python爬虫抓取指定网页图片代码实例本文向大家介绍Python爬虫抓取指定网页图片代码实例,包括了Python爬虫抓取指定网页图片代码实例的使用技巧和注意事项,需要的朋友参考一下 想要爬取指定网页中的图片主要需要以下三个步骤: (1)指定网站链接,抓取该网站的源代码(如果使用google浏览器就是按下鼠标右键 -> Inspect-> Elements 中的 html 内容) (2)根据你要抓取的内容设置正则表达式以匹配要抓取的内容
-
 Python爬虫之模拟知乎登录的方法教程
Python爬虫之模拟知乎登录的方法教程本文向大家介绍Python爬虫之模拟知乎登录的方法教程,包括了Python爬虫之模拟知乎登录的方法教程的使用技巧和注意事项,需要的朋友参考一下 前言 对于经常写爬虫的大家都知道,有些页面在登录之前是被禁止抓取的,比如知乎的话题页面就要求用户登录才能访问,而 “登录” 离不开 HTTP 中的 Cookie 技术。 登录原理 Cookie 的原理非常简单,因为 HTTP 是一种无状态的协议,因此为了在
-
Python基于BeautifulSoup和requests实现的爬虫功能示例
本文向大家介绍Python基于BeautifulSoup和requests实现的爬虫功能示例,包括了Python基于BeautifulSoup和requests实现的爬虫功能示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python基于BeautifulSoup和requests实现的爬虫功能。分享给大家供大家参考,具体如下: 爬取的目标网页:http://www.qianlima.
-
python实现爬虫统计学校BBS男女比例(一)
本文向大家介绍python实现爬虫统计学校BBS男女比例(一),包括了python实现爬虫统计学校BBS男女比例(一)的使用技巧和注意事项,需要的朋友参考一下 一、项目需求 前言:BBS上每个id对应一个用户,他们注册时候会填写性别(男、女、保密三选一)。 经过检查,BBS注册用户的id对应1-300000,大概是30万的用户 笔者想用Python统计BBS上有多少注册用户,以及这些用户的性别分布
-
 零基础写python爬虫之打包生成exe文件
零基础写python爬虫之打包生成exe文件本文向大家介绍零基础写python爬虫之打包生成exe文件,包括了零基础写python爬虫之打包生成exe文件的使用技巧和注意事项,需要的朋友参考一下 1.下载pyinstaller并解压(可以去官网下载最新版): https://github.com/pyinstaller/pyinstaller/ 2.下载pywin32并安装(注意版本,我的是python2.7): https://pypi.
-
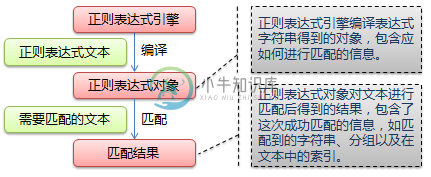 零基础写python爬虫之神器正则表达式
零基础写python爬虫之神器正则表达式本文向大家介绍零基础写python爬虫之神器正则表达式,包括了零基础写python爬虫之神器正则表达式的使用技巧和注意事项,需要的朋友参考一下 接下来准备用糗百做一个爬虫的小例子。 但是在这之前,先详细的整理一下Python中的正则表达式的相关内容。 正则表达式在Python爬虫中的作用就像是老师点名时用的花名册一样,是必不可少的神兵利器。 一、 正则表达式基础 1.1.概念介绍 正则表达式是用于
-
 Python爬虫实战:王者荣耀全套皮肤采集
Python爬虫实战:王者荣耀全套皮肤采集王者荣耀这款手游,想必大家都玩过或听过,虽已运营多年,但热度依然不减当年,各种英雄配上各式各样的皮肤,甚是精美, 今天就教大家如何利用几行Python代码爬取王者荣耀全套皮肤~~ 01网页分析 首先打开王者荣耀官网,点击英雄资料
-
爬虫对象类
一个爬虫对象下面可能会有多个爬虫项目,他们都是相关联的。 定义示例: 继承Yurun\Crawler\Module\Crawler\Contract\BaseCrawler类,并实现方法。 <?php namespace Yurun\CrawlerApp\Module\YurunBlog; use Imi\Bean\Annotation\Bean; use Imi\Cron\Consts\Cro
-
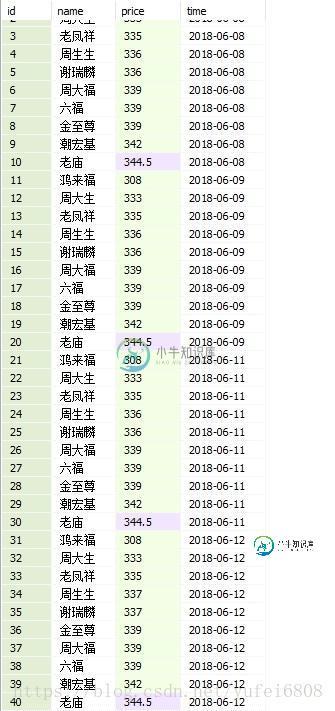 使用python爬虫获取黄金价格的核心代码
使用python爬虫获取黄金价格的核心代码本文向大家介绍使用python爬虫获取黄金价格的核心代码,包括了使用python爬虫获取黄金价格的核心代码的使用技巧和注意事项,需要的朋友参考一下 继续练手,根据之前获取汽油价格的方式获取了金价,暂时没钱投资,看看而已 最近的数据 总结 以上所述是小编给大家介绍的使用python爬虫获取黄金价格的核心代码,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对
-
python制作爬虫并将抓取结果保存到excel中
本文向大家介绍python制作爬虫并将抓取结果保存到excel中,包括了python制作爬虫并将抓取结果保存到excel中的使用技巧和注意事项,需要的朋友参考一下 学习Python也有一段时间了,各种理论知识大体上也算略知一二了,今天就进入实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫。 第一步:分析网站的请求过程 我们在查看拉勾网上的招聘信息的时候,搜索Python,或者是PHP等等
-
Python爬虫之pandas基本安装与使用方法示例
本文向大家介绍Python爬虫之pandas基本安装与使用方法示例,包括了Python爬虫之pandas基本安装与使用方法示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python爬虫之pandas基本安装与使用方法。分享给大家供大家参考,具体如下: 一、简介: Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决
-
 python爬虫获取京东手机图片的图文教程
python爬虫获取京东手机图片的图文教程本文向大家介绍python爬虫获取京东手机图片的图文教程,包括了python爬虫获取京东手机图片的图文教程的使用技巧和注意事项,需要的朋友参考一下 如题,首先当然是要打开京东的手机页面 因为要获取不同页面的所有手机图片,所以我们要跳转到不同页面观察页面地址的规律,这里观察第二页页面 由观察可以得到,第二页的链接地址很有可能是 https://list.jd.com/list.html?cat=99
-
Python网络爬虫中的同步与异步示例详解
本文向大家介绍Python网络爬虫中的同步与异步示例详解,包括了Python网络爬虫中的同步与异步示例详解的使用技巧和注意事项,需要的朋友参考一下 一、同步与异步 模板 tips: await表达式中的对象必须是awaitable requests不支持非阻塞 aiohttp是用于异步请求的库 代码 gevent简介 gevent是一个python的并发库,它为各种并发和网络相关的任务提供了整洁的
-
python爬虫 基于requests模块的get请求实现详解
本文向大家介绍python爬虫 基于requests模块的get请求实现详解,包括了python爬虫 基于requests模块的get请求实现详解的使用技巧和注意事项,需要的朋友参考一下 需求:爬取搜狗首页的页面数据 requests模块如何处理携带参数的get请求,返回携带参数的请求 需求:指定一个词条,获取搜狗搜索结果所对应的页面数据 之前urllib模块处理url上参数有中文的需要处理编码,