《python爬虫》专题
-
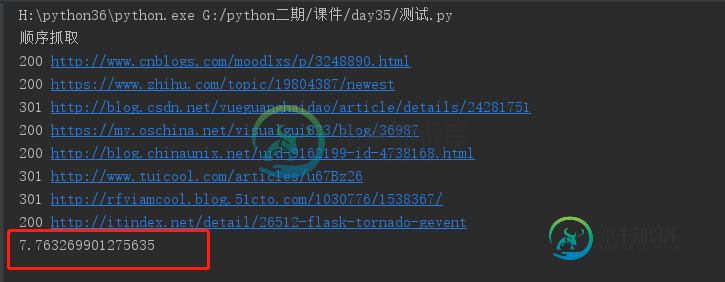 Python并发爬虫常用实现方法解析
Python并发爬虫常用实现方法解析本文向大家介绍Python并发爬虫常用实现方法解析,包括了Python并发爬虫常用实现方法解析的使用技巧和注意事项,需要的朋友参考一下 在进行单个爬虫抓取的时候,我们不可能按照一次抓取一个url的方式进行网页抓取,这样效率低,也浪费了cpu的资源。目前python上面进行并发抓取的实现方式主要有以下几种:进程,线程,协程。进程不在的讨论范围之内,一般来说,进程是用来开启多个spider,比如我们开
-
Python小白学习爬虫常用请求报头
本文向大家介绍Python小白学习爬虫常用请求报头,包括了Python小白学习爬虫常用请求报头的使用技巧和注意事项,需要的朋友参考一下 客户端HTTP请求 URL只是标识资源的位置,而HTTP是用来提交和获取资源。客户端发送一个HTTP请求到服务器的请求消息,包括以下格式: 请求行、请求头部、空行、请求数据 一个典型的HTTP请求 常用请求报头 1. Host (主机和端口号) Host:对应网址
-
 Python代理IP爬虫的新手使用教程
Python代理IP爬虫的新手使用教程本文向大家介绍Python代理IP爬虫的新手使用教程,包括了Python代理IP爬虫的新手使用教程的使用技巧和注意事项,需要的朋友参考一下 前言 Python爬虫要经历爬虫、爬虫被限制、爬虫反限制的过程。当然后续还要网页爬虫限制优化,爬虫再反限制的一系列道高一尺魔高一丈的过程。爬虫的初级阶段,添加headers和ip代理可以解决很多问题。 本人自己在爬取豆瓣读书的时候,就以为爬取次数过多,直接被封
-
简单的抓取淘宝图片的Python爬虫
本文向大家介绍简单的抓取淘宝图片的Python爬虫,包括了简单的抓取淘宝图片的Python爬虫的使用技巧和注意事项,需要的朋友参考一下 写了一个抓taobao图片的爬虫,全是用if,for,while写的,比较简陋,入门作品。 从网页http://mm.taobao.com/json/request_top_list.htm?type=0&page=中提取taobao模特的照片。 是不是很简单呢,
-
Python的Scrapy爬虫框架简单学习笔记
本文向大家介绍Python的Scrapy爬虫框架简单学习笔记,包括了Python的Scrapy爬虫框架简单学习笔记的使用技巧和注意事项,需要的朋友参考一下 一、简单配置,获取单个网页上的内容。 (1)创建scrapy项目 (2)编辑 items.py (3)在 spiders 文件夹下,创建 blog_spider.py 需要熟悉下xpath选择,感觉跟JQuery选择器差不多,但是不如
-
Python爬虫实现模拟点击动态页面
本文向大家介绍Python爬虫实现模拟点击动态页面,包括了Python爬虫实现模拟点击动态页面的使用技巧和注意事项,需要的朋友参考一下 动态页面的模拟点击: 以斗鱼直播为例:http://www.douyu.com/directory/all 爬取每页的房间名、直播类型、主播名称、在线人数等数据,然后模拟点击下一页,继续爬取 代码如下 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多
-
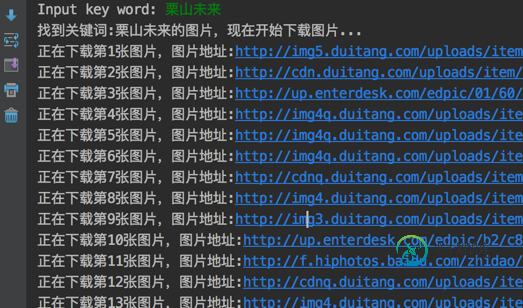 Python爬虫实现百度图片自动下载
Python爬虫实现百度图片自动下载本文向大家介绍Python爬虫实现百度图片自动下载,包括了Python爬虫实现百度图片自动下载的使用技巧和注意事项,需要的朋友参考一下 制作爬虫的步骤 制作一个爬虫一般分以下几个步骤: 分析需求分析网页源代码,配合开发者工具编写正则表达式或者XPath表达式正式编写 python 爬虫代码 效果预览 运行效果如下: 存放图片的文件夹: 需求分析 我们的爬虫至少要实现两个功能:一是搜索图片,二是自动
-
python爬虫 urllib模块url编码处理详解
本文向大家介绍python爬虫 urllib模块url编码处理详解,包括了python爬虫 urllib模块url编码处理详解的使用技巧和注意事项,需要的朋友参考一下 案例:爬取使用搜狗根据指定词条搜索到的页面数据(例如爬取词条为‘周杰伦'的页面数据) 编码错误 【注意】上述代码中url存在非ascii编码的数据,则该url无效。如果对其发起请求,则会报如下错误: url的特性:url不可以存在非
-
 零基础写python爬虫之urllib2使用指南
零基础写python爬虫之urllib2使用指南本文向大家介绍零基础写python爬虫之urllib2使用指南,包括了零基础写python爬虫之urllib2使用指南的使用技巧和注意事项,需要的朋友参考一下 前面说到了urllib2的简单入门,下面整理了一部分urllib2的使用细节。 1.Proxy 的设置 urllib2 默认会使用环境变量 http_proxy 来设置 HTTP Proxy。 如果想在程序中明确控制 Proxy 而不受环境
-
 python爬虫 - https认证如何用代码实现?
python爬虫 - https认证如何用代码实现?这个网页的数据如何获得? https://fiin-core.ssi.com.vn/Master/GetListOrganization?langu... 访问的时候,要求认证 点击,verify you are human,可以看到数据。 现在,我想抓取这些数据: 怎么办呢?
-
python3.x - python mitmproxy高级爬虫问题,求解决?
我要把downstream_port传到tiktok_response_interceptor.py脚本, 我目前的方法是 tiktok_response_interceptor-9092.py tiktok_response_interceptor-9093.py tiktok_response_interceptor-9094.py 然后文件中也写死 这大概不是最好的方法
-
爬虫面试
拼多多爬虫工程师面试题 电话面: http协议、tcp协议(几次握手) top命令 Linux/Mac 下虚拟内存(Swap) 线程、进程、协程 Async 相关、事件驱动相关 阻塞、非阻塞 Python GIL 布隆过滤器原理:如何实现、一般要几次哈希函数 给我留下了一个作业:抓取天猫超市上某些商品的可以配送省份信息。(当时做这个也花了很久,主要是需要解决PC端的登陆问题,后来通过h5接口) 现
-
爬虫介绍
什么是数据采集 定义 就我个人而说,更喜欢说数据采集而不是”爬虫“。其实更标准的叫法是网络爬虫,在wiki上是这样定义的: 网络爬虫(英语:web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引。 就比如百度、谷歌,都是网络爬虫,把互联网上所有的数据采集下来,保存到自己的数据库中,并根据各种各种规则建立排名和索引,向用户提供搜索服务。
-
 爬虫课件
爬虫课件每天,来自商业、社会以及我们的日常生活所产生「图像、音频、视频、文本、定位信息」等各种各样的海量数据,注入到我们的万维网(WWW)、计算机和各种数据存储设备,其中万维网则是最大的信息载体。
-
 python爬取youtube视频的示例代码
python爬取youtube视频的示例代码本文向大家介绍python爬取youtube视频的示例代码,包括了python爬取youtube视频的示例代码的使用技巧和注意事项,需要的朋友参考一下 这几天正在追剧,原名《大秦帝国之天下》的《大秦赋》,看着看着又想把前几部刷一遍了,但第一部《裂变》自己没有高清资源,搜了一波发现youtube上有个48集版的高清资源,有删减就有删减吧,就想着写个脚本批量下载一下,记录一下过程,主要是youtu