《python爬虫》专题
-
使用基于python scrapy的爬虫程序,但出现错误
嗨,伙计们,我已经写了一个Python爬虫刮...... 我不断地犯错误 “downloader/response_bytes”:9282,“downloader/response_count”:2,“downloader/response_status_count/200”:1,“downloader/response_status_count/301”:1,“finish_reason”:7,
-
关于爬虫和反爬虫的简略方案分享
本文向大家介绍关于爬虫和反爬虫的简略方案分享,包括了关于爬虫和反爬虫的简略方案分享的使用技巧和注意事项,需要的朋友参考一下 前言 爬虫和反爬虫日益成为每家公司的标配系统。 爬虫在情报获取、虚假流量、动态定价、恶意攻击、薅羊毛等方面都能起到很关键的作用,所以每家公司都或多或少的需要开发一些爬虫程序,业界在这方面的成熟的方案也非常多。 有矛就有盾,每家公司也相应的需要反爬虫系统来达到数据保护、系统稳定
-
python爬取各类文档方法归类汇总
本文向大家介绍python爬取各类文档方法归类汇总,包括了python爬取各类文档方法归类汇总的使用技巧和注意事项,需要的朋友参考一下 HTML文档是互联网上的主要文档类型,但还存在如TXT、WORD、Excel、PDF、csv等多种类型的文档。网络爬虫不仅需要能够抓取HTML中的敏感信息,也需要有抓取其他类型文档的能力。下面简要记录一些个人已知的基于python3的抓取方法,以备查阅。 1.抓取
-
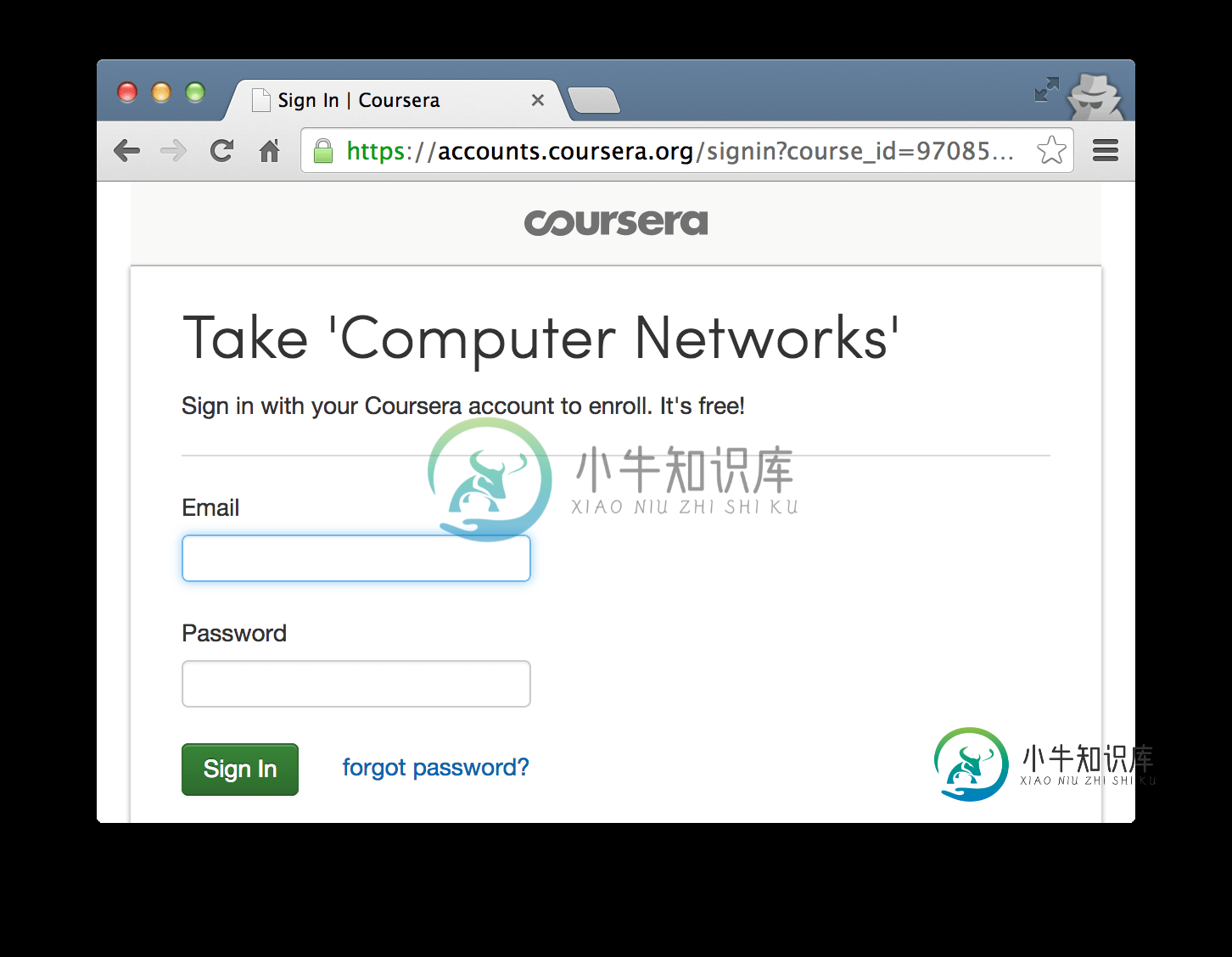 Python爬取Coursera课程资源的详细过程
Python爬取Coursera课程资源的详细过程本文向大家介绍Python爬取Coursera课程资源的详细过程,包括了Python爬取Coursera课程资源的详细过程的使用技巧和注意事项,需要的朋友参考一下 有时候我们需要把一些经典的东西收藏起来,时时回味,而Coursera上的一些课程无疑就是经典之作。Coursera中的大部分完结课程都提供了完整的配套教学资源,包括ppt,视频以及字幕等,离线下来后会非常便于学习。很明显,我们不会去一个
-
 Python爬取京东的商品分类与链接
Python爬取京东的商品分类与链接本文向大家介绍Python爬取京东的商品分类与链接,包括了Python爬取京东的商品分类与链接的使用技巧和注意事项,需要的朋友参考一下 前言 本文主要的知识点是使用Python的BeautifulSoup进行多层的遍历。 如图所示。只是一个简单的哈,不是爬取里面的隐藏的东西。 示例代码 运行这段代码以及达到了我们的目的。 我们来解读一下这段代码。 首先我们要访问到京东的首页。 然后通过Beauti
-
Python多线程爬取豆瓣影评API接口
本文向大家介绍Python多线程爬取豆瓣影评API接口,包括了Python多线程爬取豆瓣影评API接口的使用技巧和注意事项,需要的朋友参考一下 爬虫库 使用简单的requests库,这是一个阻塞的库,速度比较慢。 解析使用XPATH表达式 总体采用类的形式 多线程 使用concurrent.future并发模块,建立线程池,把future对象扔进去执行即可实现并发爬取效果 数据存储 使用Pytho
-
 Python爬取知乎图片代码实现解析
Python爬取知乎图片代码实现解析本文向大家介绍Python爬取知乎图片代码实现解析,包括了Python爬取知乎图片代码实现解析的使用技巧和注意事项,需要的朋友参考一下 首先,需要获取任意知乎的问题,只需要你输入问题的ID,就可以获取相关的页面信息,比如最重要的合计有多少人回答问题。 问题ID为如下标红数字 编写代码,下面的代码用来检测用户输入的是否是正确的ID,并且通过拼接URL去获取该问题下面合计有多少答案。 完善图片下载部分
-
Python Scrapy图片爬取原理及代码实例
本文向大家介绍Python Scrapy图片爬取原理及代码实例,包括了Python Scrapy图片爬取原理及代码实例的使用技巧和注意事项,需要的朋友参考一下 1.在爬虫文件中只需要解析提取出图片地址,然后将地址提交给管道 在管道文件对图片进行下载和持久化存储 2.配置文件修改 配置文件要增加IMAGES_STORE = './imgsLib'表明图片存放的路径 3.管道类的修改 原本管道类继承的
-
 Python爬取365好书中小说代码实例
Python爬取365好书中小说代码实例本文向大家介绍Python爬取365好书中小说代码实例,包括了Python爬取365好书中小说代码实例的使用技巧和注意事项,需要的朋友参考一下 需要转载的小伙伴转载后请注明转载的地址 需要用到的库 from bs4 import BeautifulSoup import requests import time 365好书链接:http://www.365haoshu.com/ 爬取《我以月夜寄相
-
 如何使用python爬取csdn博客访问量
如何使用python爬取csdn博客访问量本文向大家介绍如何使用python爬取csdn博客访问量,包括了如何使用python爬取csdn博客访问量的使用技巧和注意事项,需要的朋友参考一下 最近学习了python和爬虫,想写一个程序练练手,所以我就想到了大家都比较关心的自己的博客访问量,使用python来获取自己博客的访问量,这也是后边我将要进行的项目的一部分,后边我会对博客的访问量进行分析,以折线图和饼图等可视化的方式展示自己博客被访问
-
6.7 分布式爬虫
互联网时代的信息爆炸是很多人倍感头痛的问题,应接不暇的新闻、信息、视频,无孔不入地侵占着我们的碎片时间。但另一方面,在我们真正需要数据的时候,却感觉数据并不是那么容易获取的。比如我们想要分析现在人在讨论些什么,关心些什么。甚至有时候,可能我们只是暂时没有时间去一一阅览心仪的小说,但又想能用技术手段把它们存在自己的资料库里。哪怕是几个月或一年后再来回顾。再或者我们想要把互联网上这些稍纵即逝的有用信息
-
通用爬虫(Broad Crawls)
Scrapy默认对特定爬取进行优化。这些站点一般被一个单独的Scrapy spider进行处理, 不过这并不是必须或要求的(例如,也有通用的爬虫能处理任何给定的站点)。 除了这种爬取完某个站点或没有更多请求就停止的”专注的爬虫”,还有一种通用的爬取类型,其能爬取大量(甚至是无限)的网站, 仅仅受限于时间或其他的限制。 这种爬虫叫做”通用爬虫(broad crawls)”,一般用于搜索引擎。 通用爬
-
使用 bs4 的爬虫
我们以 亚马逊Kindle电子书销售排行榜 商品页面来做演示:https://www.amazon.cn/gp/bestsellers/digital-text/116169071 使用BeautifuSoup4解析器,将每件商品的的ASIN、标题、价格、star、评价数量,以及每件商品的链接爬取下来并存储在.csv文件中。 import csv import requests from
-
4.6 爬虫的监控
4.6 爬虫的监控 爬虫的监控是0.5.0新增的功能。利用这个功能,你可以查看爬虫的执行情况——已经下载了多少页面、还有多少页面、启动了多少线程等信息。该功能通过JMX实现,你可以使用Jconsole等JMX工具查看本地或者远程的爬虫信息。 如果你完全不会JMX也没关系,因为它的使用相对简单,本章会比较详细的讲解使用方法。如果要弄明白其中原理,你可能需要一些JMX的知识,推荐阅读:JMX整理。我很
-
神箭手云爬虫
神箭手云爬虫是一个帮助开发者快速开发爬虫系统的云框架。神箭手提供上手简单,灵活开放的爬虫云开发环境,让开发者只需要在线写几行js代码就可以实现一个爬虫。并且爬虫将自动运行在云服务器上,爬取速度更快,效率更高。 神箭手的主要功能包括: 1、完全脚本化,只需要编写简单的js就可以爬取任何网站。提供丰富的开放接口,同时支持所有的js自带函数。 2、自带防屏蔽函数,包括代理ip、验证码识别等。 3、爬取的