《python爬虫》专题
-
零基础写python爬虫之抓取百度贴吧代码分享
本文向大家介绍零基础写python爬虫之抓取百度贴吧代码分享,包括了零基础写python爬虫之抓取百度贴吧代码分享的使用技巧和注意事项,需要的朋友参考一下 这里就不给大家废话了,直接上代码,代码的解释都在注释里面,看不懂的也别来问我,好好学学基础知识去! 以上就是python抓取百度贴吧的一段简单的代码,非常的实用吧,各位可以自行扩展下。
-
 网络爬虫是什么
网络爬虫是什么主要内容:认识爬虫,爬虫分类,爬虫应用,爬虫是一把双刃剑,为什么用Python做爬虫,编写爬虫的流程网络爬虫又称网络蜘蛛、网络机器人,它是一种按照一定的规则自动浏览、检索网页信息的程序或者脚本。网络爬虫能够自动请求网页,并将所需要的数据抓取下来。通过对抓取的数据进行处理,从而提取出有价值的信息。 认识爬虫 我们所熟悉的一系列搜索引擎都是大型的网络爬虫,比如百度、搜狗、360浏览器、谷歌搜索等等。每个搜索引擎都拥有自己的爬虫程序,比如 360 浏览器的爬虫称作 360Spider,搜狗的爬虫叫做
-
Jobs: 暂停,恢复爬虫
有些情况下,例如爬取大的站点,我们希望能暂停爬取,之后再恢复运行。 Scrapy通过如下工具支持这个功能: 一个把调度请求保存在磁盘的调度器 一个把访问请求保存在磁盘的副本过滤器[duplicates filter] 一个能持续保持爬虫状态(键/值对)的扩展 Job 路径 要启用持久化支持,你只需要通过 JOBDIR 设置 job directory 选项。这个路径将会存储 所有的请求数据来保持一
-
8. 网络爬虫实战
案例:爬取百度新闻首页的新闻标题信息 url地址:http://news.baidu.com/ 具体实现步骤: 导入urlib库和re正则 使用urllib.request.Request()创建request请求对象 使用urllib.request.urlopen执行信息爬取,并返回Response对象 使用read()读取信息,使用decode()执行解码 使用re正则解析结果 遍历输出结果
-
5. 网络爬虫概述
5.1 网络爬虫概述: 网络爬虫(Web Spider)又称网络蜘蛛、网络机器人,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。 网络爬虫按照系统结构和实现技术,大致可分为一下集中类型: 通用网络爬虫:就是尽可能大的网络覆盖率,如 搜索引擎(百度、雅虎和谷歌等…)。 聚焦网络爬虫:有目标性,选择性地访问万维网来爬取信息。 增量式网络爬虫:只爬取新产生的或者已经更新的页面信息。特点:耗费
-
01 网络爬虫简介
图片来源于网络 1. 爬虫的定义 网络爬虫(又称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。—— 百度百科定义 详细定义参照 慕课网注解: 爬虫其实是一种自动化信息采集程序或脚本,可以方便的帮助大家获得自己想要的特定信息。比如说,像百度,谷歌等搜索引擎
-
百度云分享爬虫
百度云分享爬虫项目 github上有好几个这样的开源项目,但是都只提供了爬虫部分,这个项目在爬虫的基础上还增加了保存数据,建立elasticsearch索引的模块,可以用在实际生产环境中,不过web模块还是需要自己开发 安装 安装node.js和pm2,node用来运行爬虫程序和索引程序,pm2用来管理node任务 安装mysql和mongodb,mysql用来保存爬虫数据,mongodb用来保存
-
Scrapy-爬行器开始爬行后更改规则
我的查询是针对
-
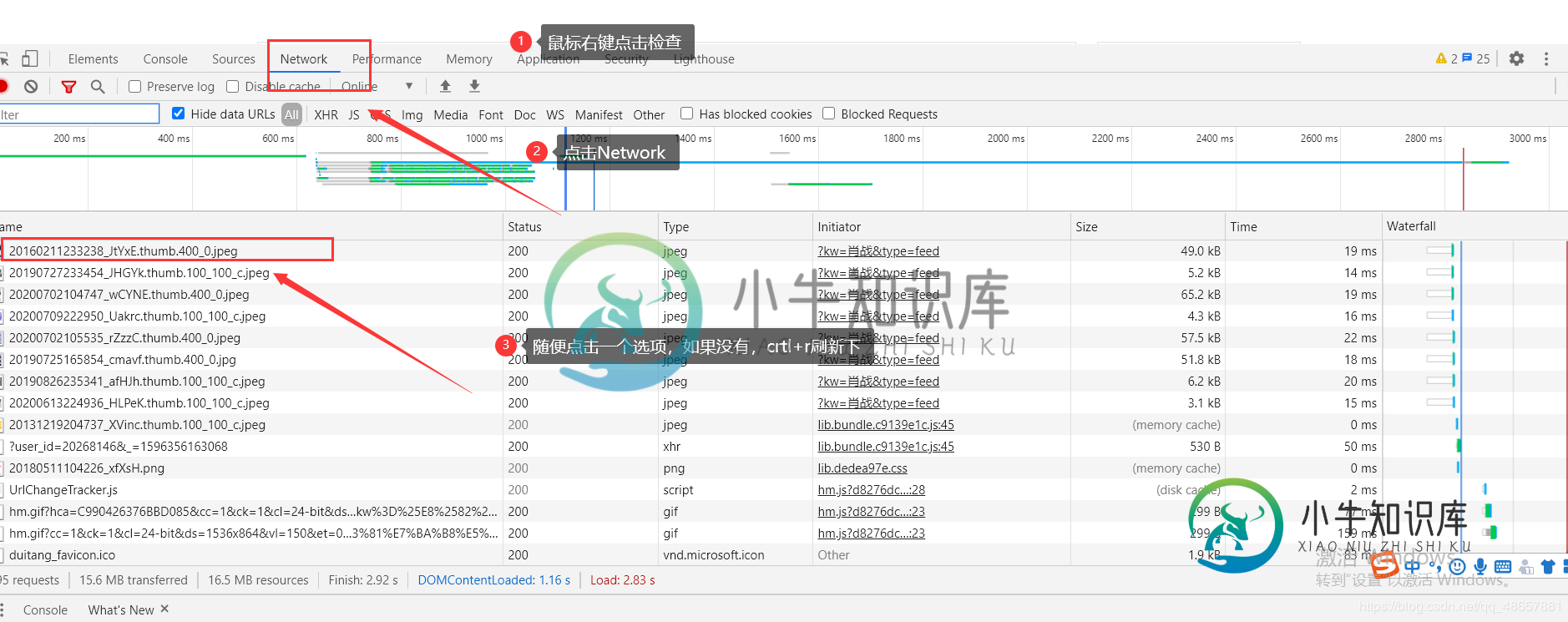 python根据用户需求输入想爬取的内容及页数爬取图片方法详解
python根据用户需求输入想爬取的内容及页数爬取图片方法详解本文向大家介绍python根据用户需求输入想爬取的内容及页数爬取图片方法详解,包括了python根据用户需求输入想爬取的内容及页数爬取图片方法详解的使用技巧和注意事项,需要的朋友参考一下 本次小编向大家介绍的是根据用户的需求输入想爬取的内容及页数。 主要步骤: 1.提示用户输入爬取的内容及页码。 2.根据用户输入,获取网址列表。 3.模拟浏览器向服务器发送请求,获取响应。 4.利用xpath方法找
-
 Python爬取qq music中的音乐url及批量下载
Python爬取qq music中的音乐url及批量下载本文向大家介绍Python爬取qq music中的音乐url及批量下载,包括了Python爬取qq music中的音乐url及批量下载的使用技巧和注意事项,需要的朋友参考一下 前言 qq music上的音乐还是不少的,有些时候想要下载好听的音乐,但有每次在网页下载都是烦人的登录什么的。于是,来了个qqmusic的爬虫。至少我觉得for循环爬虫,最核心的应该就是找到待爬元素所在url吧。下面开始找吧
-
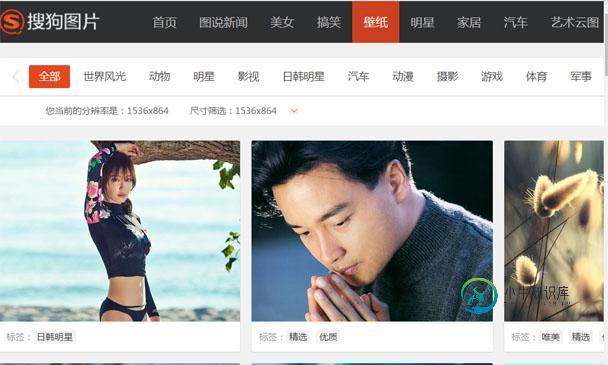 Python爬取网页中的图片(搜狗图片)详解
Python爬取网页中的图片(搜狗图片)详解本文向大家介绍Python爬取网页中的图片(搜狗图片)详解,包括了Python爬取网页中的图片(搜狗图片)详解的使用技巧和注意事项,需要的朋友参考一下 前言 最近几天,研究了一下一直很好奇的爬虫算法。这里写一下最近几天的点点心得。下面进入正文: 你可能需要的工作环境: Python 3.6官网下载 本地下载 我们这里以sogou作为爬取的对象。 首先我们进入搜狗图片http://
-
基于Python爬取fofa网页端数据过程解析
本文向大家介绍基于Python爬取fofa网页端数据过程解析,包括了基于Python爬取fofa网页端数据过程解析的使用技巧和注意事项,需要的朋友参考一下 FOFA-网络空间安全搜索引擎是网络空间资产检索系统(FOFA)是世界上数据覆盖更完整的IT设备搜索引擎,拥有全球联网IT设备更全的DNA信息。探索全球互联网的资产信息,进行资产及漏洞影响范围分析、应用分布统计、应用流行度态势感知等。 安装环境
-
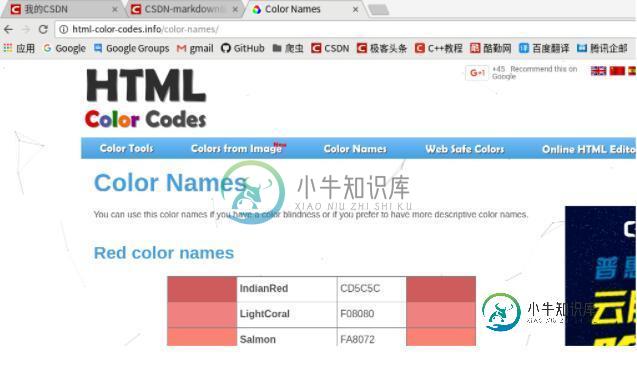 Python爬取数据并写入MySQL数据库的实例
Python爬取数据并写入MySQL数据库的实例本文向大家介绍Python爬取数据并写入MySQL数据库的实例,包括了Python爬取数据并写入MySQL数据库的实例的使用技巧和注意事项,需要的朋友参考一下 首先我们来爬取 http://html-color-codes.info/color-names/ 的一些数据。 按 F12 或 ctrl+u 审查元素,结果如下: 结构很清晰简单,我们就是要爬 tr 标签里面的 style 和 tr 下几
-
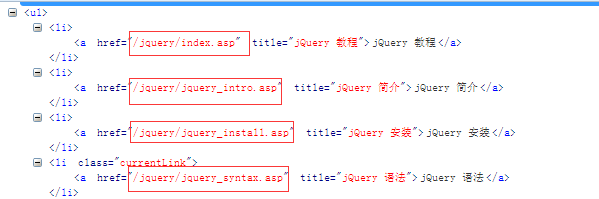 python爬取w3shcool的JQuery课程并且保存到本地
python爬取w3shcool的JQuery课程并且保存到本地本文向大家介绍python爬取w3shcool的JQuery课程并且保存到本地,包括了python爬取w3shcool的JQuery课程并且保存到本地的使用技巧和注意事项,需要的朋友参考一下 最近在忙于找工作,闲暇之余,也找点爬虫项目练练手,写写代码,知道自己是个菜鸟,但是要多加练习,书山有路勤为径。各位爷有测试坑可以给我介绍个啊,自动化,功能,接口都可以做。 首先呢,我们明确需求,很多同学呢,有
-
 用Python爬取美食网站3032个菜谱并分析
用Python爬取美食网站3032个菜谱并分析打开各大美食网站,如豆果美食、下厨房、美食天下等。经过甄选,最终爬取了豆果网最新发布的中国菜系共3032个菜谱,然后清洗数据并做可视化分析,试图走上美食博主的康庄大道。 01.数据获取 豆果美食网的数据爬取比较简单 图片 豆果美食网 本次爬取的数据范围为川菜、粤菜、湘菜等八个中国菜系,包含菜谱名、链接、用料、评分、图片等字段。限于篇幅,仅给出核心代码。