《python爬虫》专题
-
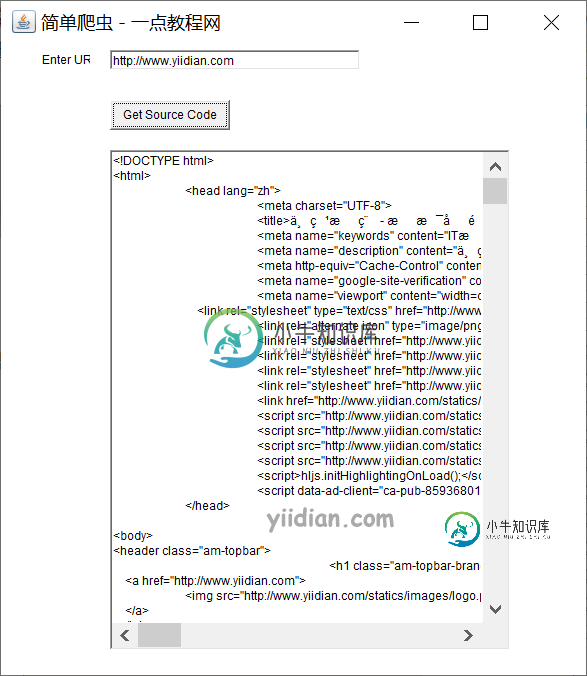 实战-Swing实现简单爬虫
实战-Swing实现简单爬虫主要内容:1 Swing实现简单爬虫1 Swing实现简单爬虫 我们可以借助网络,带有事件处理的Swing开发Java中的URL源代码生成器。让我们看一下用Java创建URL源代码生成器的代码。 核心代码: 让我们看一下生成URL源代码的代码。 输出结果为:
-
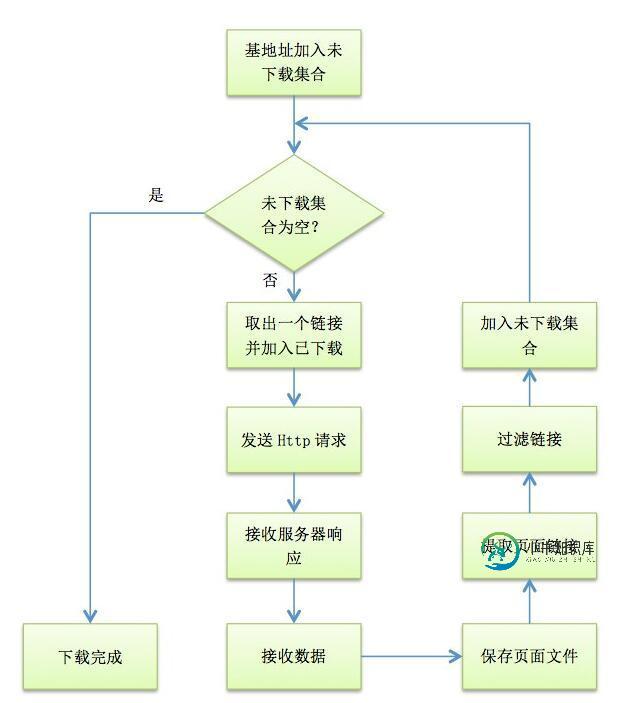 利用C#实现网络爬虫
利用C#实现网络爬虫本文向大家介绍利用C#实现网络爬虫,包括了利用C#实现网络爬虫的使用技巧和注意事项,需要的朋友参考一下 网络爬虫在信息检索与处理中有很大的作用,是收集网络信息的重要工具。 接下来就介绍一下爬虫的简单实现。 爬虫的工作流程如下 爬虫自指定的URL地址开始下载网络资源,直到该地址和所有子地址的指定资源都下载完毕为止。 下面开始逐步分析爬虫的实现。 1. 待下载集合与已下载集合 为了保存需要下载的URL
-
 基于C#实现网页爬虫
基于C#实现网页爬虫本文向大家介绍基于C#实现网页爬虫,包括了基于C#实现网页爬虫的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了基于C#实现网页爬虫的详细代码,供大家参考,具体内容如下 HTTP请求工具类: 功能: 1、获取网页html 2、下载网络图片 多线程爬取网页代码: 截图: 以上就是本文的全部内容,希望对大家的学习有所帮助。
-
24. 爬虫项目架构设计
1. 数据库设计: 为了方便后续的数据处理,将所有图书信息都汇总的一张数据表中。 创建数据库:doubandb 进入数据库创建数据表:books 表中字段: [ ID号、书名、作者、出版社、原作名、译者、出版年、页数、 定价、装帧、丛书、ISBN、评分、评论人数 ] 数据表结构: CREATE TABLE `books` (
-
23. 爬虫项目需求分析
1 项目名称 《豆瓣读书信息爬取项目》 2 项目描述: 使用Python编程语言编写一个网络爬虫项目,将豆瓣读书网站上的所有图书信息爬取下来,并存储到MySQL数据库中。 爬取信息字段要求: [ID号、书名、作者、出版社、原作名、译者、出版年、页数、定价、装帧、丛书、ISBN、评分、评论人数] 3 爬取网站过程分析: 打开豆瓣读书的首页:https://book.douban.com/ 在豆瓣读书
-
7. 网络爬虫基础使用
urllib介绍: 在Python2版本中,有urllib和urlib2两个库可以用来实现request的发送。 而在Python3中,已经不存在urllib2这个库了,统一为urllib。 Python3 urllib库官方链接:https://docs.python.org/3/library/urllib.html urllib中包括了四个模块,包括: urllib.request:可以用来
-
6. 网络爬虫工作原理
网络爬虫使用的技术--数据抓取: 在爬虫实现上,除了scrapy框架之外,python有许多与此相关的库可供使用。其中,在数据抓取方面包括: urllib2(urllib3)、requests、mechanize、selenium、splinter; 其中,urllib2(urllib3)、requests、mechanize用来获取URL对应的原始响应内容;而selenium、splinter通
-
大话爬虫的实践技巧
大话爬虫的实践技巧 图1-意淫爬虫与反爬虫间的对决 数据的重要性 如今已然是大数据时代,数据正在驱动着业务开发,驱动着运营手段,有了数据的支撑可以对用户进行用户画像,个性化定制,数据可以指明方案设计和决策优化方向,所以互联网产品的开发都是离不开对数据的收集和分析,数据收集的一种是方式是通过上报API进行自身平台用户交互情况的捕获,还有一种手段是通过开发爬虫程序,爬取竞品平台的数据,后面就重点说下爬
-
大话爬虫的基本套路
大话爬虫的基本套路 什么是爬虫? 网络爬虫也叫网络蜘蛛,如果把互联网比喻成一个蜘蛛网,那么蜘蛛就是在网上爬来爬去的蜘蛛,爬虫程序通过请求url地址,根据响应的内容进行解析采集数据, 比如:如果响应内容是html,分析dom结构,进行dom解析、或者正则匹配,如果响应内容是xml/json数据,就可以转数据对象,然后对数据进行解析。 有什么作用? 通过有效的爬虫手段批量采集数据,可以降低人工成
-
5. 使用注解编写爬虫
5.使用注解编写爬虫 WebMagic支持使用独有的注解风格编写一个爬虫,引入webmagic-extension包即可使用此功能。 在注解模式下,使用一个简单对象加上注解,可以用极少的代码量就完成一个爬虫的编写。对于简单的爬虫,这样写既简单又容易理解,并且管理起来也很方便。这也是WebMagic的一大特色,我戏称它为OEM(Object/Extraction Mapping)。 注解模式的开发方
-
 WebMagic 爬虫框架中文文档
WebMagic 爬虫框架中文文档WebMagic是我业余开发的一款简单灵活的爬虫框架。基于它你可以很容易的编写一个爬虫。 这本小书以WebMagic入手,一方面讲解WebMagic的使用方式,另一方面讲解爬虫开发的一些惯用方案。
-
示例代码 - 多进程爬虫
EasySwoole利用redis队列+定时器+task进程实现的一个多进程爬虫。直接上代码 添加Redis配置信息 修改配置文件,添加Redis配置 "REDIS"=>array( "HOST"=>'', "PORT"=>6379, "AUTH"=>"" ) 封装Redis namespace AppUtilityDb; use ConfConfig; class Re
-
 python 爬取马蜂窝景点翻页文字评论的实现
python 爬取马蜂窝景点翻页文字评论的实现本文向大家介绍python 爬取马蜂窝景点翻页文字评论的实现,包括了python 爬取马蜂窝景点翻页文字评论的实现的使用技巧和注意事项,需要的朋友参考一下 使用Chrome、python3.7、requests库和VSCode进行爬取马蜂窝黄鹤楼的文字评论(http://www.mafengwo.cn/poi/5426285.html)。 首先,我们复制一段评论,查看网页源代码,按Ctrl+F查找
-
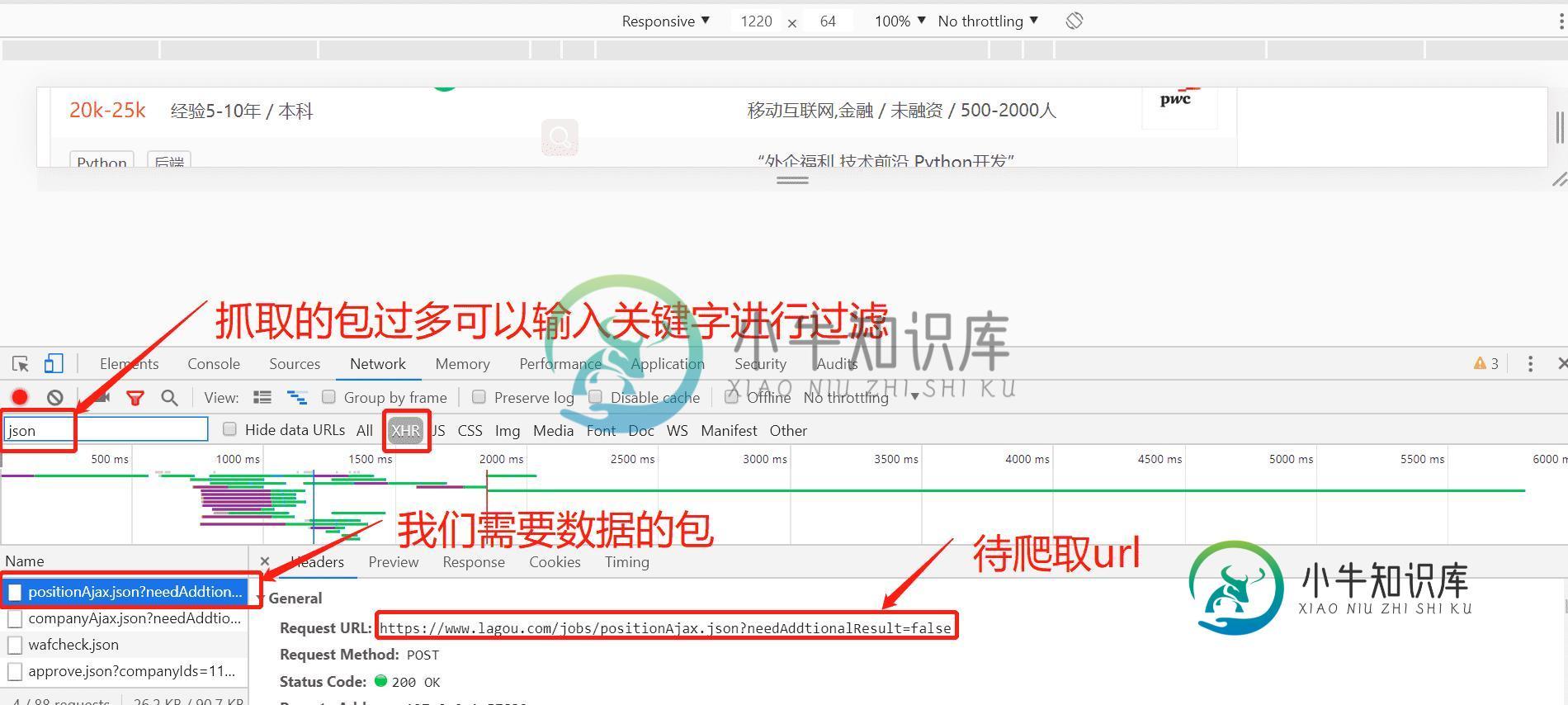 python如何爬取网站数据并进行数据可视化
python如何爬取网站数据并进行数据可视化本文向大家介绍python如何爬取网站数据并进行数据可视化,包括了python如何爬取网站数据并进行数据可视化的使用技巧和注意事项,需要的朋友参考一下 前言 爬取拉勾网关于python职位相关的数据信息,并将爬取的数据已csv各式存入文件,然后对csv文件相关字段的数据进行清洗,并对数据可视化展示,包括柱状图展示、直方图展示、词云展示等并根据可视化的数据做进一步的分析,其余分析和展示读者可自行发挥
-
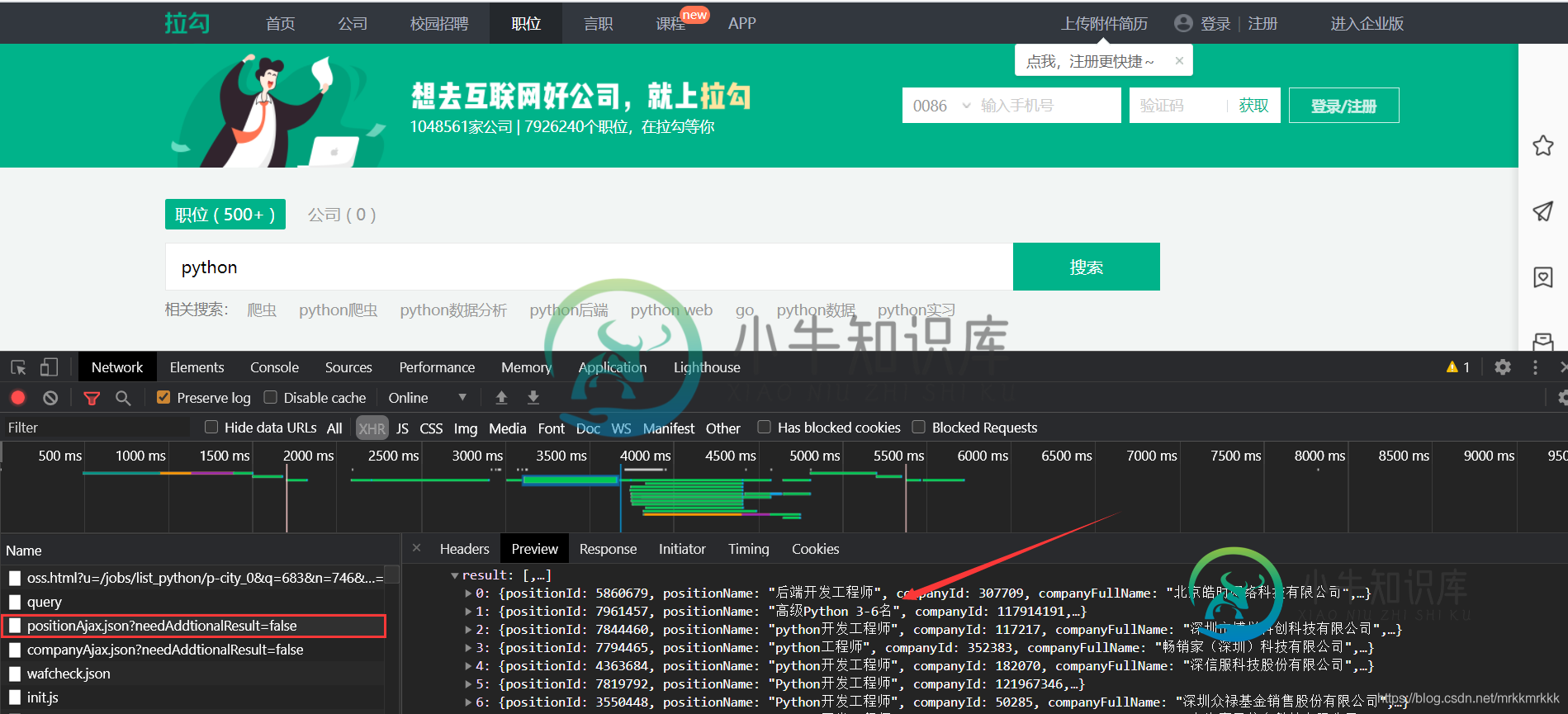 python使用requests库爬取拉勾网招聘信息的实现
python使用requests库爬取拉勾网招聘信息的实现本文向大家介绍python使用requests库爬取拉勾网招聘信息的实现,包括了python使用requests库爬取拉勾网招聘信息的实现的使用技巧和注意事项,需要的朋友参考一下 按F12打开开发者工具抓包,可以定位到招聘信息的接口 在请求中可以获取到接口的url和formdata,表单中pn为请求的页数,kd为关请求职位的关键字 使用python构建post请求 发现没有从接口获取到数据 换了个