《python爬虫》专题
-
 Python爬虫通过替换http request header来欺骗浏览器实现登录功能
Python爬虫通过替换http request header来欺骗浏览器实现登录功能本文向大家介绍Python爬虫通过替换http request header来欺骗浏览器实现登录功能,包括了Python爬虫通过替换http request header来欺骗浏览器实现登录功能的使用技巧和注意事项,需要的朋友参考一下 以豆瓣为例,访问https://www.douban.com/contacts/list 来查看自己关注的人,要登录才能查看。 如果用requests.get()方
-
python - 网络爬虫需要进行登陆操才的网站选择什么语言?
适合需要先进行登陆后才能操作的完整?应该使用什么语言呢?
-
Nginx限制搜索引擎爬虫频率、禁止屏蔽网络爬虫配置示例
本文向大家介绍Nginx限制搜索引擎爬虫频率、禁止屏蔽网络爬虫配置示例,包括了Nginx限制搜索引擎爬虫频率、禁止屏蔽网络爬虫配置示例的使用技巧和注意事项,需要的朋友参考一下 超过设置的限定频率,就会给spider一个503。 上述配置详细解释请自行google下,具体的spider/bot名称请自定义。 附:nginx中禁止屏蔽网络爬虫 可以用 curl 测试一下
-
JAVA 多线程爬虫实例详解
本文向大家介绍JAVA 多线程爬虫实例详解,包括了JAVA 多线程爬虫实例详解的使用技巧和注意事项,需要的朋友参考一下 JAVA 多线程爬虫实例详解 前言 以前喜欢Python的爬虫是出于他的简洁,但到了后期需要更快,更大规模的爬虫的时候,我才渐渐意识到Java的强大。Java有一个很好的机制,就是多线程。而且Java的代码效率执行起来要比python快很多。这份博客主要用于记录我对多线程爬虫的实
-
 NodeJS爬虫实例之糗事百科
NodeJS爬虫实例之糗事百科本文向大家介绍NodeJS爬虫实例之糗事百科,包括了NodeJS爬虫实例之糗事百科的使用技巧和注意事项,需要的朋友参考一下 1.前言分析 往常都是利用 Python/.NET 语言实现爬虫,然现在作为一名前端开发人员,自然需要熟练 NodeJS。下面利用 NodeJS 语言实现一个糗事百科的爬虫。另外,本文使用的部分代码是 es6 语法。 实现该爬虫所需要的依赖库如下。 request: 利用 g
-
nodejs制作小爬虫功能示例
本文向大家介绍nodejs制作小爬虫功能示例,包括了nodejs制作小爬虫功能示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了nodejs制作小爬虫功能。分享给大家供大家参考,具体如下: 1 安装nodejs 2 安装需要模块 3 新建js文件 4 引入 5 利用request模块发送请求 一个小爬虫案例就完了 附上完整代码 下面的带数据库 希望本文所述对大家node.js程序设计有所
-
 Java爬虫 信息抓取的实现
Java爬虫 信息抓取的实现本文向大家介绍Java爬虫 信息抓取的实现,包括了Java爬虫 信息抓取的实现的使用技巧和注意事项,需要的朋友参考一下 今天公司有个需求,需要做一些指定网站查询后的数据的抓取,于是花了点时间写了个demo供演示使用。 思想很简单:就是通过Java访问的链接,然后拿到html字符串,然后就是解析链接等需要的数据。技术上使用Jsoup方便页面的解析,当然Jsoup很方便,也很简单,一行代码就能知道怎么
-
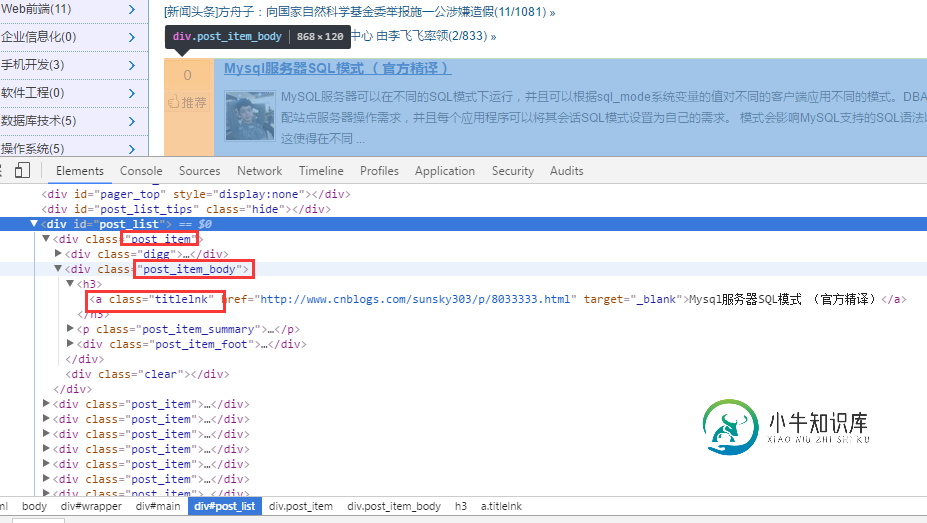
 php实现简单爬虫的开发
php实现简单爬虫的开发本文向大家介绍php实现简单爬虫的开发,包括了php实现简单爬虫的开发的使用技巧和注意事项,需要的朋友参考一下 有时候因为工作、自身的需求,我们都会去浏览不同网站去获取我们需要的数据,于是爬虫应运而生,下面是我在开发一个简单爬虫的经过与遇到的问题。 开发一个爬虫,首先你要知道你的这个爬虫是要用来做什么的。我是要用来去不同网站找特定关键字的文章,并获取它的链接,以便我快速阅读。 按照
-
PHP实现简单爬虫的方法
本文向大家介绍PHP实现简单爬虫的方法,包括了PHP实现简单爬虫的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP实现简单爬虫的方法。分享给大家供大家参考。具体如下: 希望本文所述对大家的php程序设计有所帮助。
-
 Android编写简单的网络爬虫
Android编写简单的网络爬虫本文向大家介绍Android编写简单的网络爬虫,包括了Android编写简单的网络爬虫的使用技巧和注意事项,需要的朋友参考一下 一、网络爬虫的基本知识 网络爬虫通过遍历互联网络,把网络中的相关网页全部抓取过来,这体现了爬的概念。爬虫如何遍历网络呢,互联网可以看做是一张大图,每个页面看做其中的一个节点,页面的连接看做是有向边。图的遍历方式分为宽度遍历和深度遍历,但是深度遍历可能会在深度上过深的遍历或
-
一则python3的简单爬虫代码
本文向大家介绍一则python3的简单爬虫代码,包括了一则python3的简单爬虫代码的使用技巧和注意事项,需要的朋友参考一下 不得不说python的上手非常简单。在网上找了一下,大都是python2的帖子,于是随手写了个python3的。代码非常简单就不解释了,直接贴代码。 关于cookie、异常等处理看了一下,没有花时间去处理,毕竟只是想通过写爬虫来学习python。
-
python3.7简单的爬虫实例详解
本文向大家介绍python3.7简单的爬虫实例详解,包括了python3.7简单的爬虫实例详解的使用技巧和注意事项,需要的朋友参考一下 python3.7简单的爬虫,具体代码如下所示: 总结 以上所述是小编给大家介绍的python3.7简单的爬虫实例详解,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对呐喊教程网站的支持! 如果你觉得本文对你有帮助,欢迎
-
Storm爬虫中的ES查询异常
我使用以下软件包Apache zookeeper 3 . 4 . 14 Apache storm 1 . 2 . 3 Apache Maven 3 . 6 . 2 elastic search 7 . 2 . 0(本地托管)Java 1.8.0_252 aws ec2中型实例,带4GB ram 我已经使用这个命令来增加jvm的虚拟内存(之前它显示了jvm没有足够内存的错误) 我已经创建了 mave
-
25. 爬虫项目的代码实现
25.1 数据库的准备: 启动MySQL和Redis数据库 在MySQL数据库中创建数据库:doubandb,并进入数据库中创建books数据表 CREATE TABLE `books` ( `id` bigint(20) unsigned NOT NULL COMMENT 'ID号',
-
13. 网络爬虫案例实战2
爬取猫眼电影中榜单栏目中TOP100榜的所有电影信息,并将信息写入文件 目标:使用urllib分页爬取猫眼电影中榜单栏目中TOP100榜的所有电影信息,并将信息写入文件 URL地址:http://maoyan.com/board/4 其中参数offset表示其实条数 获取信息:{排名,图片,标题,主演,放映时间,评分} from urllib import request,error import