《python爬虫》专题
-
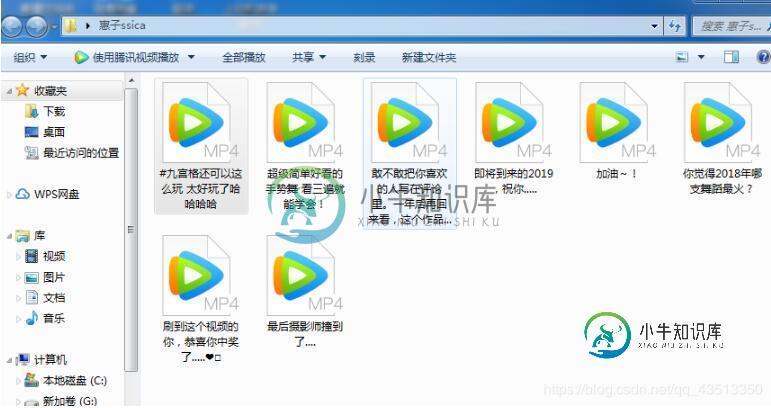 python批量爬取下载抖音视频
python批量爬取下载抖音视频本文向大家介绍python批量爬取下载抖音视频,包括了python批量爬取下载抖音视频的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了python批量爬取下载抖音视频的具体代码,供大家参考,具体内容如下 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
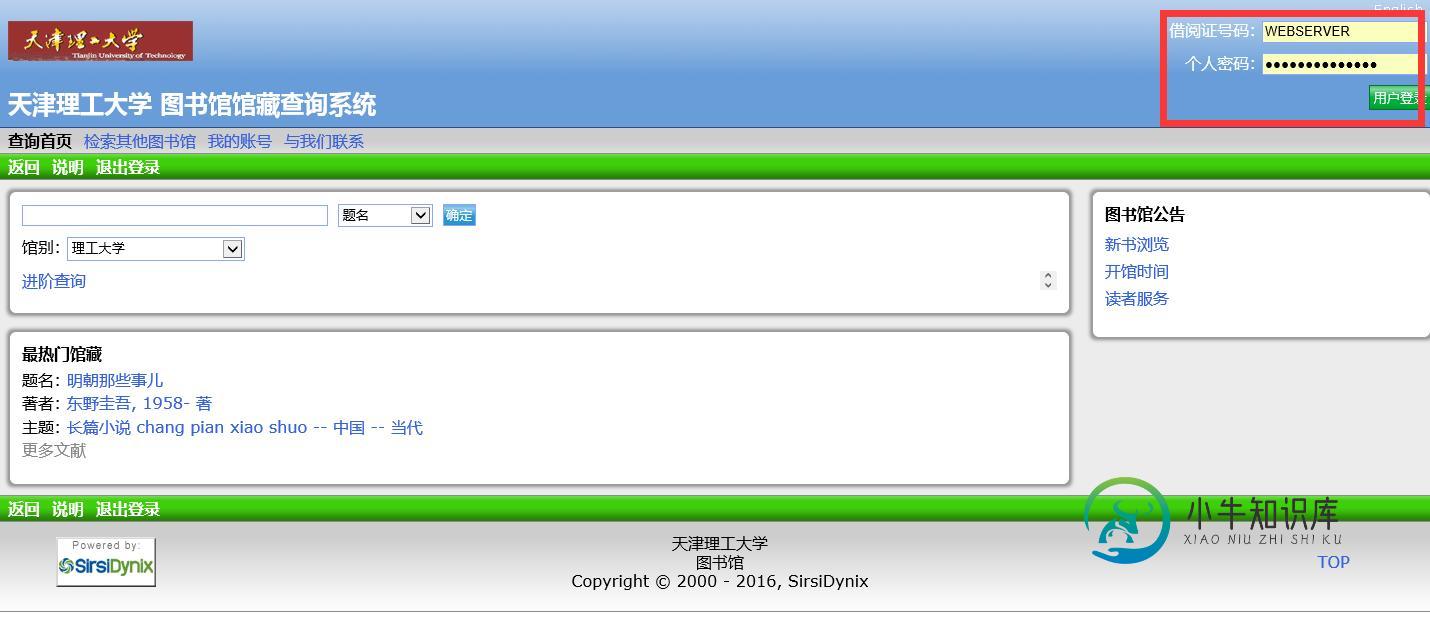 python&MongoDB爬取图书馆借阅记录
python&MongoDB爬取图书馆借阅记录本文向大家介绍python&MongoDB爬取图书馆借阅记录,包括了python&MongoDB爬取图书馆借阅记录的使用技巧和注意事项,需要的朋友参考一下 直接上需求和代码 首先是需要爬取的链接和网页:http://211.81.31.34/uhtbin/cgisirsi/x/0/0/57/49?user_id=LIBSCI_ENGI&password=LIBSC 登陆进去之后进入我的账号—
-
 利用Python爬取可用的代理IP
利用Python爬取可用的代理IP本文向大家介绍利用Python爬取可用的代理IP,包括了利用Python爬取可用的代理IP的使用技巧和注意事项,需要的朋友参考一下 前言 就以最近发现的一个免费代理IP网站为例:http://www.xicidaili.com/nn/。在使用的时候发现很多IP都用不了。 所以用Python写了个脚本,该脚本可以把能用的代理IP检测出来。 脚本如下: 运行成功后,打开E盘下的文件,可以看到如下可用
-
 node.js爬虫爬取拉勾网职位信息
node.js爬虫爬取拉勾网职位信息本文向大家介绍node.js爬虫爬取拉勾网职位信息,包括了node.js爬虫爬取拉勾网职位信息的使用技巧和注意事项,需要的朋友参考一下 简介 用node.js写了一个简单的小爬虫,用来爬取拉勾网上的招聘信息,共爬取了北京、上海、广州、深圳、杭州、西安、成都7个城市的数据,分别以前端、PHP、java、c++、python、Android、ios作为关键词进行爬取,爬到的数据以json格式储存到本地
-
 Python爬虫学习之获取指定网页源码
Python爬虫学习之获取指定网页源码本文向大家介绍Python爬虫学习之获取指定网页源码,包括了Python爬虫学习之获取指定网页源码的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了Python获取指定网页源码的具体代码,供大家参考,具体内容如下 1、任务简介 前段时间一直在学习Python基础知识,故未更新博客,近段时间学习了一些关于爬虫的知识,我会分为多篇博客对所学知识进行更新,今天分享的是获取指定网页源码的方法,
-
 python 实现一个贴吧图片爬虫的示例
python 实现一个贴吧图片爬虫的示例本文向大家介绍python 实现一个贴吧图片爬虫的示例,包括了python 实现一个贴吧图片爬虫的示例的使用技巧和注意事项,需要的朋友参考一下 今天没事回家写了个贴吧图片下载程序,工具用的是PyCharm,这个工具很实用,开始用的Eclipse,但是再使用类库或者其它方便并不实用,所以最后下了个专业开发python程序的工具,开发环境是Python2,因为大学时自学的是python2 第一步:就是
-
 python爬虫实现教程转换成 PDF 电子书
python爬虫实现教程转换成 PDF 电子书本文向大家介绍python爬虫实现教程转换成 PDF 电子书,包括了python爬虫实现教程转换成 PDF 电子书的使用技巧和注意事项,需要的朋友参考一下 写爬虫似乎没有比用 Python 更合适了,Python 社区提供的爬虫工具多得让你眼花缭乱,各种拿来就可以直接用的 library 分分钟就可以写出一个爬虫出来,今天就琢磨着写一个爬虫,将廖雪峰的 Python 教程 爬下来做成 PDF 电子
-
python并发爬虫实用工具tomorrow实用解析
本文向大家介绍python并发爬虫实用工具tomorrow实用解析,包括了python并发爬虫实用工具tomorrow实用解析的使用技巧和注意事项,需要的朋友参考一下 tomorrow是我最近在用的一个爬虫利器,该模块属于第三方的一个模块,使用起来非常的方便,只需要用其中的threads方法作为装饰器去修饰一个普通的函数,既可以达到并发的效果,本篇将用实例来展示tomorrow的强大之处。后面将对
-
Python爬虫之Selenium设置元素等待的方法
本文向大家介绍Python爬虫之Selenium设置元素等待的方法,包括了Python爬虫之Selenium设置元素等待的方法的使用技巧和注意事项,需要的朋友参考一下 一、显式等待 WebDriverWait类是由WebDirver 提供的等待方法。在设置时间内,默认每隔一段时间检测一次当前页面元素是否存在,如果超过设置时间检测不到则抛出异常(TimeoutException) 语法: WebDr
-
 Python实现的异步代理爬虫及代理池
Python实现的异步代理爬虫及代理池本文向大家介绍Python实现的异步代理爬虫及代理池,包括了Python实现的异步代理爬虫及代理池的使用技巧和注意事项,需要的朋友参考一下 使用python asyncio实现了一个异步代理池,根据规则爬取代理网站上的免费代理,在验证其有效后存入redis中,定期扩展代理的数量并检验池中代理的有效性,移除失效的代理。同时用aiohttp实现了一个server,其他的程序可以通过访问相应的url来从
-
 Python使用requests及BeautifulSoup构建爬虫实例代码
Python使用requests及BeautifulSoup构建爬虫实例代码本文向大家介绍Python使用requests及BeautifulSoup构建爬虫实例代码,包括了Python使用requests及BeautifulSoup构建爬虫实例代码的使用技巧和注意事项,需要的朋友参考一下 本文研究的主要是Python使用requests及BeautifulSoup构建一个网络爬虫,具体步骤如下。 功能说明 在Python下面可使用requests模块请求某个url获取响
-
python爬虫 模拟登录人人网过程解析
本文向大家介绍python爬虫 模拟登录人人网过程解析,包括了python爬虫 模拟登录人人网过程解析的使用技巧和注意事项,需要的朋友参考一下 requests 提供了一个叫做session类,来实现客户端和服务端的会话保持 使用方法 1.实例化一个session对象 2.让session发送get或者post请求 下面就用人人网来实战一下 就这么简单,模拟登录上人人网并且获取了个人首页信息页面保
-
 Python爬虫 bilibili视频弹幕提取过程详解
Python爬虫 bilibili视频弹幕提取过程详解本文向大家介绍Python爬虫 bilibili视频弹幕提取过程详解,包括了Python爬虫 bilibili视频弹幕提取过程详解的使用技巧和注意事项,需要的朋友参考一下 两个重要点 1.获取弹幕的url是以 .xml 结尾 2.弹幕url的所需参数在视频url响应的 javascript 中 先看代码 先找到弹幕的url,以.xml结尾,所以先找到这串数字所在的位置,并获取这串数字发起第二次请求
-
Python 正则表达式爬虫使用案例解析
本文向大家介绍Python 正则表达式爬虫使用案例解析,包括了Python 正则表达式爬虫使用案例解析的使用技巧和注意事项,需要的朋友参考一下 现在拥有了正则表达式这把神兵利器,我们就可以进行对爬取到的全部网页源代码进行筛选了。 下面我们一起尝试一下爬取内涵段子网站: http://www.neihan8.com/article/list_5_1.html 打开之后,不难看出里面一个一个非常有内涵
-
 PHP实现爬虫爬取图片代码实例
PHP实现爬虫爬取图片代码实例本文向大家介绍PHP实现爬虫爬取图片代码实例,包括了PHP实现爬虫爬取图片代码实例的使用技巧和注意事项,需要的朋友参考一下 文字信息 我们尝试获取表的信息,这里,我们就用某校的课表来代替: 接下来我们就上代码: a.php 然后咱们就运行一下: 成功获取到课表; 图片获取 绝对链接 我们以百度图库的首页为例 b.php 然后,我们就获得了下面的页面: 相对链接 百度图库的图片的链接大部